
Hadoop安装教程
一、所需软件
Java 必须安装。Hadoop 2.7 及以后版本,需要安装 Java 7
ssh 必须安装并且保证 sshd 一直运行,以便用 Hadoop 脚本管理远端Hadoop 守护进程,如果没有安装,ubuntu系统:
$ sudo apt-get install ssh
$ sudo apt-get install rsync
二、下载hadoop
地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/
wget -c http://mirror.cogentco.com/pub/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
三、运行 Hadoop 集群的准备工作
下载后解压,编辑etc/hadoop/hadoop-env.sh 文件,定义如下参数:
#设置 Java 的安装目录 : export JAVA_HOME=/your path of java/
#设置hadoop安装目录:export HADOOP_PREFIX=/your path of hadoop/
尝试如下命令:
$ bin/hadoop
将会显示 hadoop 脚本的使用文档
现在你可以用以下三种支持的模式中的一种启动 Hadoop 集群:
- 本地(单机)模式
- 伪分布式模式
- 完全分布式模式
四、hadoop单机模式下的操作实例(注:Hadoop刚完成安装不修改配置文件即为单机模式,只需要在hadoop-env.sh中增加java的路径)
默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助
统计许多文件中的每个单词出现的次数,这个曾经作为58同城校招面试题(当初不了解hadoop,惭愧)
mkdir input cp hadoop-2.6.5/etc/hadoop/*.xml input hadoop jar hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount ./input/ output#注意不用自己提前建立output目录 #output目录下_SUCCESS文件表示作业成功,part-r-00000文件记录了每个单词出现的次数
其他配置文件不用编辑:
######几个重要的配置文件原始配置######
###core-site.xml###
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
</configuration>
###hdfs-site.xml###
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
</configuration>
###yarn-site.xml###
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
</configuration>
五、伪分布式模式的操作方法
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于hadoop-2.6.5/etc/hadoop中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式实现,修改配置文件 core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
初始的core-site.xml文件只含<configuration> </configuration>两行,需要自己提前新建/hadoop/tmp(自己建立的目录,根据自己的选择建立路径)
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/tmp/dfs/data</value>
</property>
</configuration>
其中/hadoop/tmp/要和上面的配置文件core-site.xml里的路径保持一致
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错
设置免密码登录
$ ssh localhost
若未成功登录,则执行下面命令
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
产生公钥和私钥,现在是伪分布式,全分布式的时候,需要在一个节点(如node1)免密登录其他节点(如node2),则需要将node1的公钥追加到node2的authorized_keys文件里,这样在node1即可node2机器上。
配置完成后,执行 NameNode 的格式化:
hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错
接着开启 NameNode 和 DataNode 守护进程
./sbin/start-dfs.sh ''' Starting namenodes on [localhost] localhost: starting namenode, logging to namenode-ubuntu.out localhost: starting datanode, logging to datanode-ubuntu.out Starting secondary namenodes [0.0.0.0] ... '''
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
jps ''' 28864 ResourceManager 39237 Jps 38937 SecondaryNameNode 38573 DataNode 38398 NameNode '''
六、分布式安装(以三台机器为例):
1)三台机器均装上java
2)先将hadoop安装包放在作为NameNode的节点
a:配置hadoop-2.6.5/etc/hadoop下的core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/userid/hadoop/tmp</value>#自己选择一个目录
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://111.200.251.237:9000</value>
</property>
</configuration>
#由于是全分布式了,所以hdfs的值不用localhost了,而是用自己的NameNode的IP
b:由于我只有三个机器,即只有两个DataNode,设置hdfs-site.xml文件中的block的副本数为2(dfs.replication默认是3):
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/userid/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/userid/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
c:指明DataNode所在机器,即配置hadoop-2.6.5/etc/hadoop下的slaves文件(该文件默认内容是localhost,是伪分布式的设置),将DataNode节点的IP或者主机名添加到slaves文件中(删除localhost)
d:设置SecondaryNameNode,只需要不合NameNode不在一个节点上即可,设置masters文件,添加SecondaryNameNode节点的IP,但是注意:2.0版以后就没有masters文件:vi master文件并添加SecondaryNameNode机子IP,然后编辑hdfs-site.xml文件,将其中的0.0.0.0改为你的namenode的IP地址,并添加SecondaryNameNode的地址,hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/uid/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/uid/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>NameNode IP:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SecondaryNameNode IP:50090</value>
</property>
</configuration>
也许有人问了,DataNode和SecondaryNameNode都有专门的文件配置指定,那NameNode呢?-别忘了core-site.xml文件中已经配置了fs.defaultFS,已经指定了NameNode的IP
3)设置免密码登录
分别在三台机器上执行:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #分别设置各个节点免密登录
然后将NameNode的id_rsa.pub分别追加到DataNode节点的authorized_keys文件中,以便NameNode节点可以免密登录其他节点(从A想免密登录B,就把A的id_rsa.pub追加到B的authorized_keys文件中)
当然,这里只是设置了NameNode节点可以免密登录到其他节点上,并没有设置成其他节点可以登录到NameNode节点上,如果需要,则任何节点登录其他节点,就将彼此的id_rsa.pub都存放到authorized_keys文件中,确保每个节点都有彼此的id_rsa.pub即可
4)将hadoop安装到其他节点(DataNode)上,以同样的路径安装(保证配置文件完全一样,所以建议见NameNode下安装的hadoop完全拷贝到其他节点),别忘设置JAVA_HOME环境变量(hadoop-env.sh中)
5)在NameNode上执行hadoop namenode -format
6)sbin/start-dfs.sh(不是start-all.sh)如果启动失败,先sbin/stop-dfs.sh,然后排查原因
以上完成了hdfs的配置
7)配置hadoop-2.6.5/etc/hadoop下的mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.151:10020</value>#master IP或者主机名
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.151:19888</value>#master IP或者主机名
</property>
</configuration>
8)配置hadoop-2.6.5/etc/hadoop下的yarn-site.xml文件:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.151</value>#marster的IP或者主机名
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
9)将配置好的这些配置文件传输到slave节点上
10)CentOS 系统需要关闭防火墙:
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
sudo service iptables stop # 关闭防火墙服务 sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了
若用是 CentOS 7,需通过如下命令关闭(防火墙服务改成了 firewall):
systemctl stop firewalld.service # 关闭firewall systemctl disable firewalld.service # 禁止firewall开机启动
11 启用集群
start-all.sh mr-jobhistory-daemon.sh start historyserver
使用jps命令查看各个进程,出现下面的进程,则正常:

七、主节点master的配置(也就是NameNode)
集群中分为主结点(Master Node)和从结点(Slave Node)两种结点。我们选择一个主结点,两个从结点进行配置。主结点IP为192.168.1.151,修改主结点的/etc/hosts(sudo vi /etc/hosts),内容配置如下所示(不需要改动IPV6的配置内容)
127.0.0.1 localhost 192.168.1.151 master 192.168.1.150 slave01 192.168.1.149 slave02
Ubuntu系统,还要修改主机名,对应的配置文件为/etc/hostname,修改该配置文件(sudo vi /etc/hostname),内容如下所示:
master
这里,因为在集群启动以后,master需要登录到任意一个从结点上,执行相应的授权操作,所以,master的/etc/hosts中要配置上集群中全部从结点的主机名到对应IP地址的映射,用 CentOS 6.x 系统,则是修改 /etc/sysconfig/network 文件,改为:
HOSTNAME=master
从节点slave01和slave02节点也要修改自己的 /etc/hosts和/etc/hostname,其中slave01 /etc/hosts修改为:(slave01的/etc/hostname修改为slave01)
127.0.0.1 localhost 192.168.1.151 master 192.168.1.150 slave01
slave02的 /etc/hosts修改为:(slave02的/etc/hostname修改为slave02)
127.0.0.1 localhost 192.168.1.151 master 192.168.1.149 slave02
说明:为什么建议使用主机名称,而不直接使用IP地址?
第二,扩展性好。因为通过/etc/hosts对主机名和IP地址进行了映射,即使IP变了,主机名可以保持不变。在Hadoop安装的时候,需要配置master和slaves两个文件,如果这两个文件都使用IP的话,试想,一个具有200个结点的集群,因为一次企业的网络规划重新分配网段,导致IP全部变更,那么这些配置都要进行修改,工作量很大。但是,如果使用主机名的话,Hadoop的配置不需要任何改变,而对于主机名到IP地址的映射配置交给系统管理员去做好了
netstat -ano | grep 50070
2)查看防火墙的状态,是否关闭,如果没有,强制性关闭
service iptables status#若开启,则运行下面的关闭命令 chkconfig iptables off#永久关闭防火墙 service iptables stop#临时关闭防火墙
但由于LInux原始的防火墙工具iptables过于繁琐,所以ubuntu默认提供了一个基于iptable之上的防火墙工具ufw。ubuntu 9.10默认的便是UFW防火墙,它已经支持界面操作了。在命令行运行ufw命令就可以看到提示的一系列可进行的操作:
ufw version#查看版本 #启用 sudo ufw enable sudo ufw default deny #运行以上两条命令后,开启了防火墙,并在系统启动时自动开启。关闭所有外部对本机的访问,但本机访问外部正常 sudo ufw allow | deny #开启 | 禁用 sudo ufw status#查看状态 sudo ufw enable | disable #开启/关闭防火墙 (默认设置是’disable’)
一般当防火墙开启了,则 disable关闭,即可访问http://192.168.1.*:50070这是我的marster 节点IP
九、一个分布式实例
hdfs dfs -mkdir -p /user/hadoop#创建HDFS 上的用户目录 #配置文件作为输入文件复制到分布式文件系统中 hdfs dfs -mkdir input hdfs dfs -put hadoop-2.6.5/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:
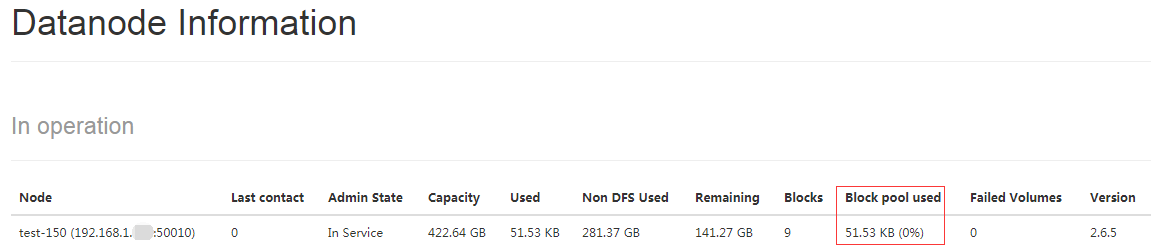
提交map/reduce作业:(从input文件中查找dfs后跟字母或者.的字符串)
hadoop jar hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+'
同样可以通过 Web 界面查看任务进度 http://master:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:

十、关闭集群
关闭 Hadoop 集群也是在 Master 节点上执行的:
stop-yarn.sh stop-dfs.sh mr-jobhistory-daemon.sh stop historyserver
十一、排错
1)集群启动后如果有异常,应该首先去相应的节点目录hadoop-2.6.5/logs下查看Log文件,比如出现下面的信息:Datanode denied communication with namenode because hostname cannot be resolved
由于配置hadoop没有使用host+hostName的配置方式,导致了hadoop无法解析DataNode,对DataNode的注册失败,这时hdfs-site.xml中添加:
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
2)SecondaryNameNode节点启动失败,显示其端口被占用,这时可以更改SecondaryNameNode节点的IP,也就是换一台机子作为SecondaryNameNode,当然也可以更换占用的端口

