
shell关于文件操作
一、如何将一个十进制的整数用2进制表示出来?
echo "obase=2;50" | bc
二、Linux下经常需要删除空白行,grep,sed,awk,tr等工具均可实现
grep -v '^$' filename
sed '/^$/d' filename
awk '{if($0!="") print $0}' filename
tr -s '\n' < filename
三、shell中if 判断语句中的匹配模式
=~ 表示匹配
if [[ $slave =~ "140$" ]]
then
echo "end with 140"
fi
四、awk中split的用法
有一个文件存在两域,第一域是基因名字,第二域是别名,别名存在多个,以|分割,要求将基因名和别名一一对应,如将下图转换成下下图的结果

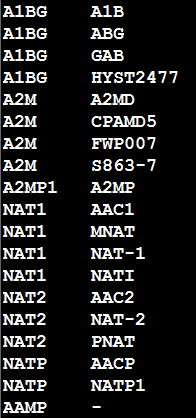
awk -F"\t" -v OFS="\t" '{if($2~/\|/){len=split($2,a,"|");for(i=1;i<=len;i++)print $1,a[i]}else print $0}' input > result
#~表示第二域匹配到|,按|分割保存到数组a
#split()返回a的长度,并遍历a
#else未匹配到|则直接输出
五、join对两个文件相同域进行合并操作
现在有两个文件,其中两个文件有部分相同的域,如何筛选出这些域相同的记录,如A,B文件如下图:
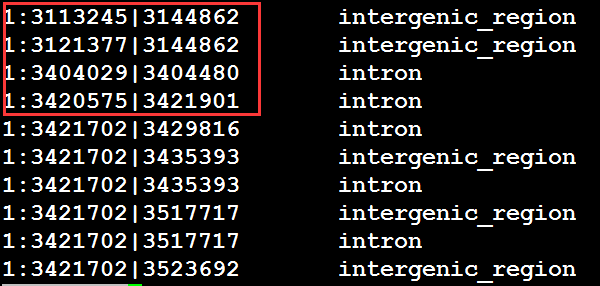

从上可以看出两个文件前四行有相同的域,那么我想把这些相同域的记录筛选出来,即前四行筛选出来,该怎么做呢?注意:join操作必须按指定的域进行排过序
join -1 1 -2 4 file_one file_two ''' 1:3113245|3144862 intergenic_region 1 3113245 3144862 1:3121377|3144862 intergenic_region 1 3121377 3144862 1:3404029|3404480 intron 1 3404029 3404480 1:3420575|3421901 intron 1 3420575 3421901 ''' #-1和-2指定连接的域 join -1 4 -2 1 two one ''' 1:3113245|3144862 1 3113245 3144862 intergenic_region 1:3121377|3144862 1 3121377 3144862 intergenic_region 1:3404029|3404480 1 3404029 3404480 intron 1:3420575|3421901 1 3420575 3421901 intron '''
六、有两个关键词,如何将这两个关键词之间的行打印出来?
: comment
file:
1
2
3
3
4
5
6
7
7
8
9
10
comment
#将3和7之间的行打印出来
awk '/3/,/7/{print $0}' file
'''
3
3
4
5
6
7
'''
#可见将3和7之间的行一块儿打印出来了,其中3有2行,7只打印出一行
#如果不想打印出3和7关键词行
awk '/3/,/7/{if(i>1)print x;x=$0;i++}' file
'''
3
4
5
6
'''
awk '/3/,/7/{if(i>2)print x;x=$0;i++}' file
'''
4
5
6
'''
七、awk中substr()函数使用
substr():截取字符串,返回从起始位置起,指定长度之子字符串;若未指定长度,则返回从起始位置到字符串末尾的子字符串。
格式:
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分
#将fastq转换为fasta
awk '{if(NR%4 == 1){print ">" substr($0, 2)}}{if(NR%4 == 2){print}}' fastq > fasta
八、有一文件

如何根据红框中的值是否相同,将两行或者多行变成一行,GENE_ID列按逗号分隔,结果如下:

awk -F"GENE_ID=" 'BEGIN{tem=0}{split($2,array,";"); if($1!=tem){printf("\n%sGENE_ID=%s",$1,array[1]);tem=$1}else{printf(",%s",array[1])}}' paragon | sed '/^$/d'
#coding=utf-8
import sys
in_file = sys.argv[1]
#需要保存上一行的name和line
#注意输入文件bed要先排序:sort -V your_bed
name_before = ''
line_before = ''
with open(in_file) as f1:
for eachline in f1:
array = eachline.strip().split('\t')
if array[3] != name_before:
if line_before:
print line_before
gene_id = array[-1].strip().split(';')[0]
new_line = '\t'.join((array[0:-1] + [gene_id]))
name_before = array[3]
line_before = new_line
else:
gene_id = array[-1].strip().split(';')[0].split('=')[-1]
line_before = line_before + ',' + gene_id
#print the last line
print line_before
九、如何提取字符串中的数字部分
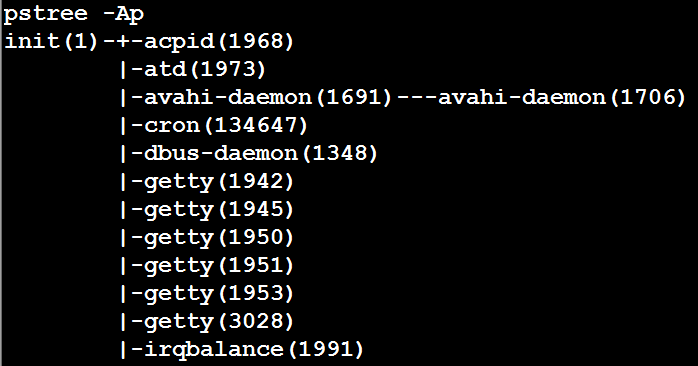
如执行上面的命令,想提取其中的数字部分:
pstree -Ap | tr -cd "[0-9])" | sed 's/)/\n/g' | less
-d表示删除,[0-9]表示所有数字,-c表示对条件取反,所以tr -cd "[0-9]"这句话的意思就是,剔除非数字的字符
十、一个文件vim编辑中文显示正常,more或者less显示乱码
执行下面的命令试试:
cat data_20190306.csv | iconv -f GBK -t UTF-8 > data_20190306_new.csv
如果vi中文乱码:
vi ~/.vimrc #添加:set fileencodings=utf-8,gbk
如果使用python打开文件报UnicodeDecodeError错误,则可以再linux下使用file命令,查看文件编码格式,然后open时候指定encoding参数,如:
Little-endian UTF-16 Unicode text, with CRLF, CR line terminators
说明文件是utf-16编码,并且是\n\r换行
十一、windows文件转换unix文件
vi一个文件:
set ff? #显示当前文件格式 set ff=unix #设置成unix格式 set ff=dos #设置成dos格式
或者dos2unix命令,但是得先安装

