

NLP-Commen Sense
一、WordPiece
what:现在基本性能好一些的NLP模型,例如OpenAI GPT,google的BERT,在数据预处理的时候都会有WordPiece的过程。WordPiece字面理解是把word拆成piece一片一片,其实就是这个意思
why:比如"loved","loving","loves"这三个单词。其实本身的语义都是“爱”的意思,但是如果我们以单词为单位,那它们就算不一样的词,在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不是太好。BPE算法通过训练,能够把上面的3个单词拆分成"lov","ed","ing","es"几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量。
how:WordPiece的一种主要的实现方式叫做BPE(Byte-Pair Encoding)双字节编码。我们原始词表如下:{'l o w e r ': 2, 'n e w e s t ': 6, 'w i d e s t ': 3, 'l o w ': 5},其中的key是词表的单词拆分层字母,再加代表结尾,value代表词出现的频率。下面我们每一步在整张词表中找出频率最高相邻序列,并把它合并,依次循环
原始词表 {'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3, 'l o w </w>': 5}
出现最频繁的序列 ('s', 't') 9
合并最频繁的序列后的词表 {'n e w e st </w>': 6, 'l o w e r </w>': 2, 'w i d e st </w>': 3, 'l o w </w>': 5}
出现最频繁的序列 ('e', 'st') 9
合并最频繁的序列后的词表 {'l o w e r </w>': 2, 'l o w </w>': 5, 'w i d est </w>': 3, 'n e w est </w>': 6}
出现最频繁的序列 ('est', '</w>') 9
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'l o w e r </w>': 2, 'n e w est</w>': 6, 'l o w </w>': 5}
出现最频繁的序列 ('l', 'o') 7
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'lo w e r </w>': 2, 'n e w est</w>': 6, 'lo w </w>': 5}
出现最频繁的序列 ('lo', 'w') 7
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'low e r </w>': 2, 'n e w est</w>': 6, 'low </w>': 5}
出现最频繁的序列 ('n', 'e') 6
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'low e r </w>': 2, 'ne w est</w>': 6, 'low </w>': 5}
出现最频繁的序列 ('w', 'est</w>') 6
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'low e r </w>': 2, 'ne west</w>': 6, 'low </w>': 5}
出现最频繁的序列 ('ne', 'west</w>') 6
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'low e r </w>': 2, 'newest</w>': 6, 'low </w>': 5}
出现最频繁的序列 ('low', '</w>') 5
合并最频繁的序列后的词表 {'w i d est</w>': 3, 'low e r </w>': 2, 'newest</w>': 6, 'low</w>': 5}
出现最频繁的序列 ('i', 'd') 3
合并最频繁的序列后的词表 {'w id est</w>': 3, 'newest</w>': 6, 'low</w>': 5, 'low e r </w>': 2}
总结:WordPiece或者BPE这么好,我们是不是哪里都能这么用呢?其实在我们的中文中不是很适用。首先我们的中文不像英文或者其他欧洲的语言一样通过空格分开,我们是连续的。其次我们的中文一个字就是一个最小的单元,无法在拆分的更小了。在中文中一般的处理方式是两中,分词和分字。理论上分词要比分字好,因为分词更加细致,语义分的更加开。分字简单,效率高,词表也很小,常用字就3000左右
参考:https://www.cnblogs.com/huangyc/p/10223075.html
二、AR vs AE
自回归模型,是统计上一种处理时间序列的方法,用同一变数例如${x}$的之前各期,亦即${x_1}$至${x_{t-1}}$来预测${x_t}$的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用${x}$预测${y}$,而是用${x}$预测${x}$自己,所以叫做自回归。
AR:Autoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有ELMO、GTP等
$$\begin{aligned}\text { forward: } p(x) &=\prod_{t=1}^{T} p\left(x_{t} \mid x_{<t}\right) \\\text { backward: } p(x) &=\prod_{t=T}^{1} p\left(x_{t} \mid x_{>t}\right)\end{aligned}$$
-
缺点:它只能利用单向语义而不能同时利用上下文信息。ELMO通过双向都做AR模型,然后进行拼接,但从结果来看,效果并不是太好
-
优点:对自然语言生成任务(NLG)友好,天然符合生成式任务的生成过程。这也是为什么GPT能够编故事的原因
AE:Autoencoding Language Modeling,又叫自编码语言。通过上下文信息来预测当前被mask的token,代表有BERT,Word2Vec(CBOW)
$$p(x)=\prod_{x \in M a s k} p\left(x_{t} \mid \text {context}\right)$$
-
缺点:由于训练中采用了MASK标记,导致预训练与微调阶段不一致的问题。此外对于生成式问题,AE模型也显得捉襟见肘,这也是目前BERT为数不多没有实现大的突破的领域
-
优点:能够很好的编码上下文语义信息,在自然语言理解(NLU)相关的下游任务上表现突出
三、UniLM
what:自然语言理解与生成的统一预训练语言模型,来自于微软研究院
why:UniLM模型之所以强大,是因为它既可以应用于自然语言理解(NLU)任务,又可以应用于自然语言生成(NLG)任务。结构与BERT一致,是由一个多层Transformer网络构成
how:
训练参数-在模型预训练过程中,在一个训练batch中,使用1/3的数据进行双向语言模型优化,1/3的数据进行序列到序列语言模型优化,1/6的数据进行从左向右的单向语言模型优化,1/6的数据进行从右向左的单向语言模型优化。模型结构与BERT-base模型一致,由一个12层768隐藏节点和12个头的Transformer编码器组成,并由训练好的BERT-base模型初始化参数。
token掩码的概率为15%,在被掩掉的token中,有80%使用[MASK]替换,10%使用字典中随机词进行替换,10%保持越来token不变,与BERT模型一致。此外,在80%的情况下,每次随机掩掉一个token,在剩余的20%情况下,掩掉一个二元token组或三元token组。
学习率是3e-5,最大长度是512,batch_size大小是80。共训练为16.4万步。使用4张Nvidia Telsa V100 16GB GPU卡,通过混合精度训练。
Fine Tune-可以直接使用BERT代码,只需加载unilm的model、config、vocab即可。
四、Chinese-BERT-wwm
哈工大讯飞联合实验室发布基于全词覆盖(Whole Word Masking)-wwm的中文BERT预训练模型。
Whole Word Masking (wwm):是谷歌在2019年5月31日发布的一项BERT的升级版本,主要更改了原预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个词缀,在生成训练样本时,这些被分开的词缀会随机被[MASK]替换。在全词Mask中,如果一个完整的词的部分WordPiece被[MASK]替换,则同属该词的其他部分也会被[MASK]替换,即全词Mask。
同理,由于谷歌官方发布的BERT-base(Chinese)中,中文是以字为粒度进行切分,没有考虑到中文分词。将全词Mask的方法应用在了中文,即对组成同一个词的汉字全部进行[MASK]。该模型使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大语言技术平台LTP作为分词工具
下面展示wwm的生成样例

五、分词原理介绍
英文一般直接根据空格分词,但是因需求而定,如‘New York’需要被看做是一个词
基于字符串匹配方法:正向最大匹配法,逆向最大匹配法,双向最大匹配法,最少切分(使每一句中切出的词数最小)
现代分词大多数都是基于统计的方法,统计的样本内容都来自于一些标准语料库,如人民日报语料,假如有一句子“南京市长江大桥”可能得到有几种分词方式,如
“南京市/长江大桥/在/上个世纪/修建”
“南京/市长/江大桥/在/上个世纪/修建”
显然第一种分词方式的概率要比第二种分词的概率大,那是如何得到这样的选择呢?
以下就开始介绍语言模型-所谓语言模型,简单明了:它是用来计算一个句子的概率模型,也就是判断一句话是否是人话的概率?这个和分词原理有什么关系呢?
假设有一个句子S,它有m种分词方式,那么分词最终要做的事情就是使得其中一种分词方式的概率最大(相当于分词之后组合得到的概率最大,这个就和语言模型的思想不谋而和了)
$r=\underbrace{\arg \max }_{i} P\left(W_{i 1}, W_{i 2}, \ldots, W_{i n_{i}}\right)$
即概率可以表示为:$P(S)=P\left(W_{1}, W_{2}, \ldots, W_{k}\right)=p\left(W_{1}\right) P\left(W_{2} \mid W_{1}\right) \ldots P\left(W_{k} \mid W_{1}, W_{2}, \ldots, W_{k-1}\right)$
可是这样的方法有两个问题:
1:某些生僻词,或者相邻分词联合分布在语料库没有,这样就会出现概率为0,这时候通常需要采用拉普拉斯平滑
2:参数维度过多:条件概率可能性太多,无法有效计算。
因此为了解决这种问题,我们引入马尔科夫假设。
马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
一元语言模型:如果一个词的出现与周围词无关,也就是它是独立的,那称这种模型为一元语言模型(unigram)
二元语言模型:如果一个词的出现依赖于前面一个词,那称这种模型为二元语言模型(bigram)
N元语言模型:以此类推,如果一个词的出现依赖于前面N-1个词,那称这种模型为N元语言模型(N-gram)在实践中用的最多的就是二元语言模型和三元语言模型
在NLP中,通常我们用到齐次马尔科夫假设,即每一个分词出现的概率只与前面一个分词相关,与其他分词无关。即
$P(S)=P\left(W_{1}, W_{2}, \ldots, W_{k}\right)=p\left(W_{1}\right) P\left(W_{2} \mid W_{1}\right) \ldots P\left(W_{k} \mid W_{k-1}\right)$
通过我们标准语料库,可以计算所有分词的二元条件概率:$P\left(w_{2} \mid w_{1}\right)=\frac{P\left(w_{1}, w_{2}\right)}{P\left(w_{1}\right)} \approx \frac{f r e q\left(w_{1}, w_{2}\right)}{f r e q\left(w_{1}\right)}$
即一起出现的频数比上条件单独出现的频数,因此通过以上方法我们即可求出各种分词组合的联合分布概率,找到最大概率对应的分词即为最优分词。
Verterbi算法与分词
它是用来解决动态规划最优化问题的:基于局部最优寻找全局最优,是一种动态规划最大概率寻找法,首先我们来看下它在NLP中的应用,例如:“人生如梦境”。它的分词可能情况如下图:
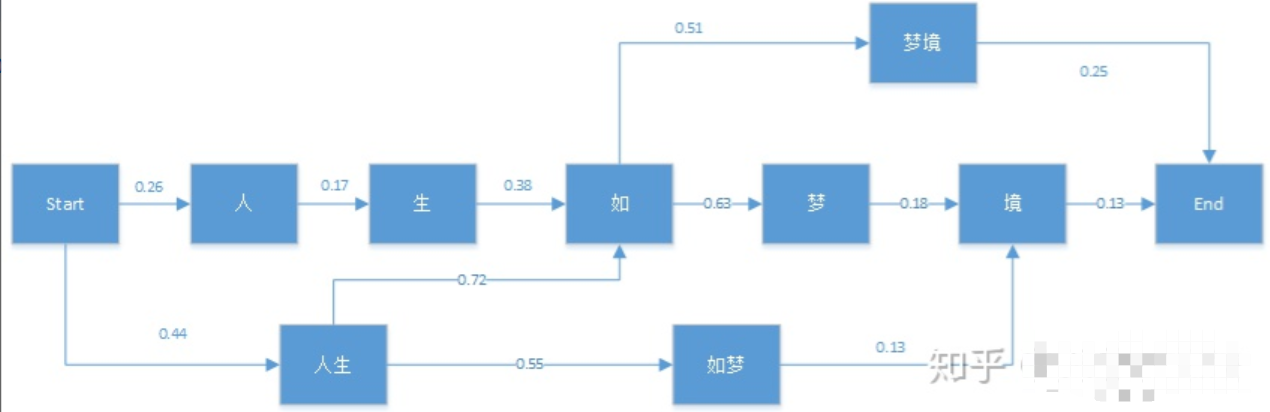
维特比算法帮我们找到最优路径-即最佳分词路径:https://zhuanlan.zhihu.com/p/65680803
六、NMF非负矩阵分解
NMF的基本思想可以简单描述为:对于任意给定的一个非负矩阵A,NMF算法能够寻找到一个非负矩阵U和一个非负矩阵V,使得满足 ,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积。
分解前后可理解为:原始矩阵${V}$的列向量是对左矩阵${W}$中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称${W}$为基矩阵,${H}$为系数矩阵。一般${k}$(${W}$的列数)要比${N}$小,这时用系数矩阵代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵,从而减少存储空间,减少计算机资源。
原矩阵${V}$中的一列向量可以解释为对左矩阵${W}$中所有列向量(称为基向量)的加权和,而权重系数为右矩阵H中对应列向量中的元素。这种基于基向量组合的表示形式具有很直观的语义解释,它反映了人类思维中“局部构成整体”的概念。
虽然NMF是一个很厉害的算法,但其实质是加权和

