

seq2seq项目详解
一、seq2seq和encoder-decoder关系
seq2seq是从解决问题的目的角度来说的,利用的框架是encoder-decoder
二、项目例子
比如我们有两个文件letters_source.txt和letters_target.txt,他们行数一致,也就是我们的训练集合,他们每一行互应(这两个文件同一行彼此长度可以不一致:比如中英互译)
我们只展示前10行(我们该项目的目的是训练一个seq2seq模型,最终输入一个原序列,给出对原序列排序的目标序列)
''' 原序列 目标序列 bsaqq abqqs npy npy lbwuj bjluw bqv bqv kial aikl tddam addmt edxpjpg degjppx nspv npsv huloz hlouz kmclq cklmq ............. '''
1)读取文件
''' 只展示前十个序列 source_seq: ['bsaqq', 'npy', 'lbwuj', 'bqv', 'kial', 'tddam', 'edxpjpg', 'nspv', 'huloz', 'kmclq'] target_seq: ['abqqs', 'npy', 'bjluw', 'bqv', 'aikl', 'addmt', 'degjppx', 'npsv', 'hlouz', 'cklmq'] '''
2)针对source和target中的所有字符,我们建立一个字典,将字符变成数字
'''
为每个char进行int转换:(这里为了每次转换保持一致,已经进行了字符列表的排序)
source_int_to_letter {0: '<PAD>', 1: '<UNK>', 2: '<GO>', 3: '<EOS>', 4: 'a', 5: 'b', 6: 'c', 7: 'd', 8: 'e', 9: 'f', 10: 'g', 11: 'h', 12: 'i', 13: 'j', 14: 'k', 15: 'l', 16: 'm', 17: 'n', 18: 'o', 19: 'p', 20: 'q', 21: 'r', 22: 's', 23: 't', 24: 'u', 25: 'v', 26: 'w', 27: 'x', 28: 'y', 29: 'z'}
source_letter_to_int {'<PAD>': 0, '<UNK>': 1, '<GO>': 2, '<EOS>': 3, 'a': 4, 'b': 5, 'c': 6, 'd': 7, 'e': 8, 'f': 9, 'g': 10, 'h': 11, 'i': 12, 'j': 13, 'k': 14, 'l': 15, 'm': 16, 'n': 17, 'o': 18, 'p': 19, 'q': 20, 'r': 21, 's': 22, 't': 23, 'u': 24, 'v': 25, 'w': 26, 'x': 27, 'y': 28, 'z': 29}
target_int_to_letter {0: '<PAD>', 1: '<UNK>', 2: '<GO>', 3: '<EOS>', 4: 'a', 5: 'b', 6: 'c', 7: 'd', 8: 'e', 9: 'f', 10: 'g', 11: 'h', 12: 'i', 13: 'j', 14: 'k', 15: 'l', 16: 'm', 17: 'n', 18: 'o', 19: 'p', 20: 'q', 21: 'r', 22: 's', 23: 't', 24: 'u', 25: 'v', 26: 'w', 27: 'x', 28: 'y', 29: 'z'}
target_letter_to_int {'<PAD>': 0, '<UNK>': 1, '<GO>': 2, '<EOS>': 3, 'a': 4, 'b': 5, 'c': 6, 'd': 7, 'e': 8, 'f': 9, 'g': 10, 'h': 11, 'i': 12, 'j': 13, 'k': 14, 'l': 15, 'm': 16, 'n': 17, 'o': 18, 'p': 19, 'q': 20, 'r': 21, 's': 22, 't': 23, 'u': 24, 'v': 25, 'w': 26, 'x': 27, 'y': 28, 'z': 29}
由于原序列和目标序列都是26个英语字母,如果是其他情况,如翻译,他们就是分别是单词或者中文文字库
'''
3)source和target序列进行数值转换
''' 有了上面的序列字符组成的字符库,我们需要对原序列和目标序列转换成对应的数字序列,这里分别列出前十个: source_int = [[5, 22, 4, 20, 20], [17, 19, 28], [15, 5, 26, 24, 13], [5, 20, 25], [14, 12, 4, 15], [23, 7, 7, 4, 16], [8, 7, 27, 19, 13, 19, 10], [17, 22, 19, 25], [11, 24, 15, 18, 29], [14, 16, 6, 15, 20], ......](如序列bsaqq对应的数值序列为[5, 22, 4, 20, 20]) target_int = [[4, 5, 20, 20, 22, 3], [17, 19, 28, 3], [5, 13, 15, 24, 26, 3], [5, 20, 25, 3], [4, 12, 14, 15, 3], [4, 7, 7, 16, 23, 3], [7, 8, 10, 13, 19, 19, 27, 3], [17, 19, 22, 25, 3], [11, 15, 18, 24, 29, 3], [6, 14, 15, 16, 20, 3], ......](target序列abqqs对应的数值序列就是排序[4, 5, 20, 20, 22],我们为每个target序列加上EOS,也就是数字3) 综上,原序列和target序列就被数值化 '''
下面我们讲几个概念:
- Epoch(时期):
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次epoch。(也就是说,所有训练样本在神经网络中都进行了一次正向传播和一次反向传播 )
再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。
然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练
-
Batch(批 / 一批样本):
将整个训练样本分成若干个Batch -
Batch_Size(批大小):
每批样本的大小 -
Iteration(一次迭代):
训练一个Batch就是一次Iteration(这个概念跟程序语言中的迭代器相似)
这里我们把epoch设置为60,batch_size=128
# 将数据集分割为train和validation train_source = source_int[batch_size:] train_target = target_int[batch_size:] # 留出一个batch进行验证 valid_source = source_int[:batch_size] valid_target = target_int[:batch_size]
这样我们把source序列和target(分别有10000条序列)拆分为训练集和验证集(前128条为验证序列)
4)encoder层
下面我们看看encoder部分干了什么事情:
# Encoder
# 在Encoder端,我们需要进行两步,第一步要对我们的输入进行Embedding,再把Embedding以后的向量传给RNN进行处理
# 在Embedding中,我们使用tf.contrib.layers.embed_sequence,它会对每个batch执行embedding操作
def get_encoder_layer(input_data, rnn_size, num_layers, source_sequence_length, source_vocab_size, encoding_embedding_size):
"""
构造Encoder层
参数说明:
- input_data: 输入tensor
- rnn_size: rnn隐层结点数量
- num_layers: 堆叠的rnn cell数量
- source_sequence_length: 源数据的序列长度,也就是有效长度
- source_vocab_size: 源数据的词典大小
- encoding_embedding_size: embedding的大小
"""
# Encoder embedding,这里进行embedding原理是什么呢?我只提供了序列数字,以及词汇数量,就完成了向量化
encoder_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
cell = tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output, encoder_state = tf.nn.dynamic_rnn(
cell, encoder_embed_input, sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
我们假如输入的一个batch是128 * 7的tensor(即:128个句子样本,每个样本句子长度为7),rnn_size = 60,num_layers = 2,source_sequence_length为一个list,保留了128个句子样本中每个句子样本的原长,encoding_embedding_size = 15,即每个字符嵌入向量长度15,我们演示上面的encoder过程,别眨眼啊:
我们可以根据每个batch中最长序列的长度,对其他序列进行pad填充:
'''只展示前六个 valid_sources_batch: [[5,22,4,20,20,0,0], [17,19,28,0,0,0,0], [15,5,26,24,13,0,0], [,5,20,25,0,0,0,0],[14,12,4,15,0,0,0], [23,7,7,4,16,0,0]] valid_targets_batch: [[4,5,20,20,22,3,0,0], [17,19,28,3,0,0,0,0], [5,13,15,24,26,3,0,0], [,5,20,25,3,0,0,0,0], [4,12,14,15,3,0,0,0], [4,7,7,16,23,3,0,0]] valid_targets_lengths: [6, 4, 6, 4, 5, 6] valid_sources_lengths: [5, 3, 5, 3, 4, 5] '''
上面是验证集的展示,训练集从129行开始
同理,每个batch处理方式相同,我们以第一个epoch的第一个batch为例,讲述训练过程:其中第一个batch是从source_int[batch_size:256]和target_int[batch_size:256],也就说source_int和target_int的下标:128到256,以前几行为例:

我们看一下转数字并pading之后:sources_batch[0:10]:这里是训练集的第一batch,也就说从原序列129行开始(前128行是验证集),这里只是展示129-138行的序列
''' sources_batch[0:10] [[24 9 17 0 0 0 0] ufn对应的数字进行pad后 [14 13 0 0 0 0 0] kj对应的数字进行pad后 [20 26 23 19 10 20 0] qwtpgq对应的数字进行pad后 [26 23 15 0 0 0 0] [11 25 0 0 0 0 0] [17 25 17 0 0 0 0] [13 6 22 0 0 0 0] [21 29 0 0 0 0 0] [ 8 29 27 21 0 0 0] [23 13 8 0 0 0 0]] tje对应的数字进行pad后 [3, 2, 6, 3, 2, 3, 3, 2, 4, 3]这个保存的是他们未进行pad时各自序列长度 targets_batch[0:10]: [[ 9 17 24 3 0 0 0 0] [13 14 3 0 0 0 0 0] [10 19 20 20 23 26 3 0] [15 23 26 3 0 0 0 0] [11 25 3 0 0 0 0 0] [17 17 25 3 0 0 0 0] [ 6 13 22 3 0 0 0 0] [21 29 3 0 0 0 0 0] [ 8 21 27 29 3 0 0 0] [ 8 13 23 3 0 0 0 0]] [4, 3, 7, 4, 3, 4, 4, 3, 5, 4] 与上面的sources_batch对应,注意,每个target序列都进行了EOS(数字3)的添加,所以每个target序列都比原序列长度多1 '''
OK,我们至此已经有了一个batch 的input(128个序列),其中第一对训练序列如:source-[24 9 17 0 0 0 0]长度为3,已经pad处理,target-[ 9 17 24 3 0 0 0 0]长度为4,加了EOS和PAD
其实我们每一batch的source是二维矩阵:$128 * 7$,这里的7不是固定的,因为第一batch中source最长是7,所以这里是7,这个列数由每一批中序列最长的序列长度决定(但要注意这个序列不会太长哦)
然后我们可以对其进行encode:
在Encoder端,我们需要进行两步,第一步要对我们的输入进行Embedding,再把Embedding以后的向量传给LSTM进行处理。
在Embedding中,我们使用tf.contrib.layers.embed_sequence,它会对每个batch执行embedding操作,我们设置encoding_embedding_size = 15,也就说每个序列中的每个字符(也就是每个字母)从一维扩张到15维,我们的sources_batch也就是我们的input,会被embedding:
sources_batch:一batch为128,每个序列长度为7(比如哈,可能其他batch中有条序列长度大于7,那么该批次就每个序列长度pad后就为最长序列长度)
同时,我们要知道我们的source序列总共有多少种字符(本项目中为26个字母外加四种特殊字符,也就是30种)
我们的source_batch本来是128 * 7,被embeding后就变成了128 * 7 * 15,我们把第一batch训练集的第一个序列[24 9 17 0 0 0 0]即ufn进行embeding后展示出来:(7*15)
# Encoder embedding encoder_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size) #下面是一行embeding后结果展示 ''' [[-0.36065042 -0.17114215 -0.05008167 0.21896338 -0.18541089 0.19533116 -0.12902524 0.07539368 -0.23459466 0.21035886 -0.18695556 0.11775276 -0.0019387 -0.12290165 0.02873832] [-0.25419667 -0.10173807 0.22848481 -0.0533388 -0.00930399 -0.02172154 0.13963962 0.02923623 0.09819978 -0.12081417 -0.23042265 -0.28695342 0.1045948 0.04559454 0.09481269] [ 0.19500643 0.28019369 0.10704392 0.03675491 0.35994822 0.08842304 -0.15914266 0.33308589 -0.12992106 -0.13675191 -0.17976578 -0.20379627 -0.29855976 0.03020796 -0.30255833] [-0.06587648 -0.05019096 -0.10603911 0.33219868 0.36303657 0.16047823 -0.0563249 -0.13622303 -0.24733457 -0.30284318 0.03862795 -0.07534647 0.28796619 -0.07870796 0.16098654] [-0.06587648 -0.05019096 -0.10603911 0.33219868 0.36303657 0.16047823 -0.0563249 -0.13622303 -0.24733457 -0.30284318 0.03862795 -0.07534647 0.28796619 -0.07870796 0.16098654] [-0.06587648 -0.05019096 -0.10603911 0.33219868 0.36303657 0.16047823 -0.0563249 -0.13622303 -0.24733457 -0.30284318 0.03862795 -0.07534647 0.28796619 -0.07870796 0.16098654] [-0.06587648 -0.05019096 -0.10603911 0.33219868 0.36303657 0.16047823 -0.0563249 -0.13622303 -0.24733457 -0.30284318 0.03862795 -0.07534647 0.28796619 -0.07870796 0.16098654]] '''
这样我们一个batch的Input就是128*7*15,也就是我们已经获得encoder_embed_input,下面我们可以进行encode了,我们先定义一个LSTM单元
# RNN cell
rnn_size = 50
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
我们先说说这个rnn_size = 50是什么意思,假设我们当前x输入是某个字符-15维向量,那么这个rnn_size也就是num_units就说下面的h,即就是一个50维的向量,h和x进行concatenate,就得到了65维的向量作为input
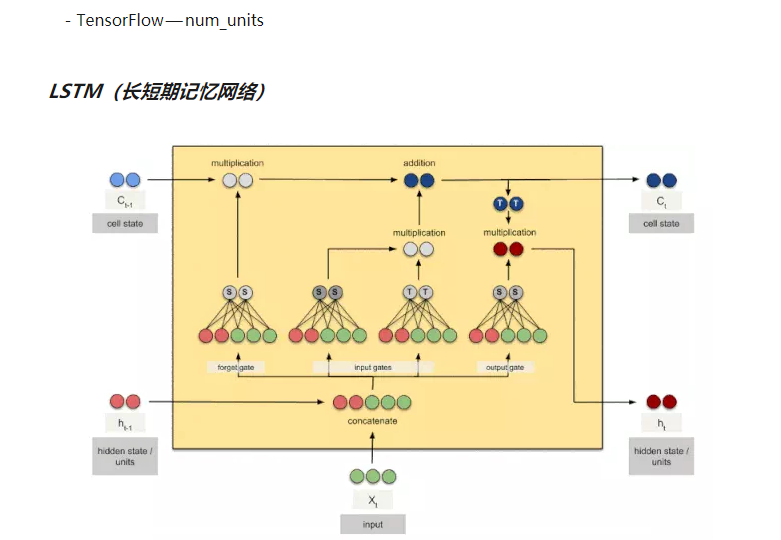
下面我们参考下面的链接,继续讲解,在使用Tensorflow跑LSTM的试验中, 有个num_units(也就是上面所说的rnn_size)的参数,这个参数是什么意思呢?
先总结一下,num_units这个参数的大小就是LSTM输出结果的维度。例如num_units=128(上面的例子rnn_size=50), 那么LSTM网络最后输出就是一个128维的向量
我们先换个角度举个例子,最后再用公式来说明。
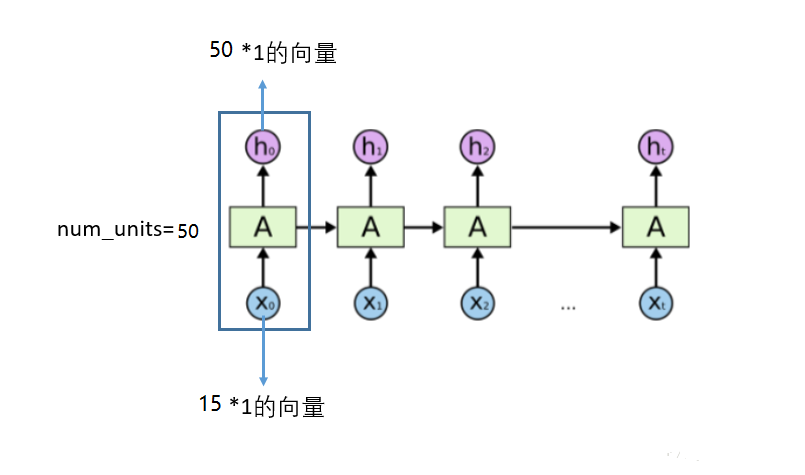
假设在我们的训练数据中,每一个样本 x(在这里指每一行序列) 是 $7*15$(上面的例子是7*15:7表示一个序列长度,15表示每个元素(这里为一个字符)被embeding成15维向量) 维的一个矩阵,那么将这个样本的每一行当成一个输入,通过7个时间步骤展开LSTM,在每一个LSTM单元,我们输入一行维度为15的向量,如下图所示(修改别人的图片了,自己PS的,不要被row image字样影响,就当作一个向量就行)

那么,对每一个LSTM单元,参数num_units=50的话,就是每一个单元的输出为 50*1 的向量,在展开的网络维度来看,如下图所示,对于每一个输入15维的向量,LSTM单元都把它映射到50维的维度, 在下一个LSTM单元时,LSTM会接收上一个50维的输出,和新的15维的输入,处理之后再映射成一个新的50维的向量输出,就这么一直处理下去,知道网络中最后一个LSTM单元,输出一个50维的向量
从LSTM的公式的角度看是什么原理呢?我们先看一下LSTM的结构和公式:
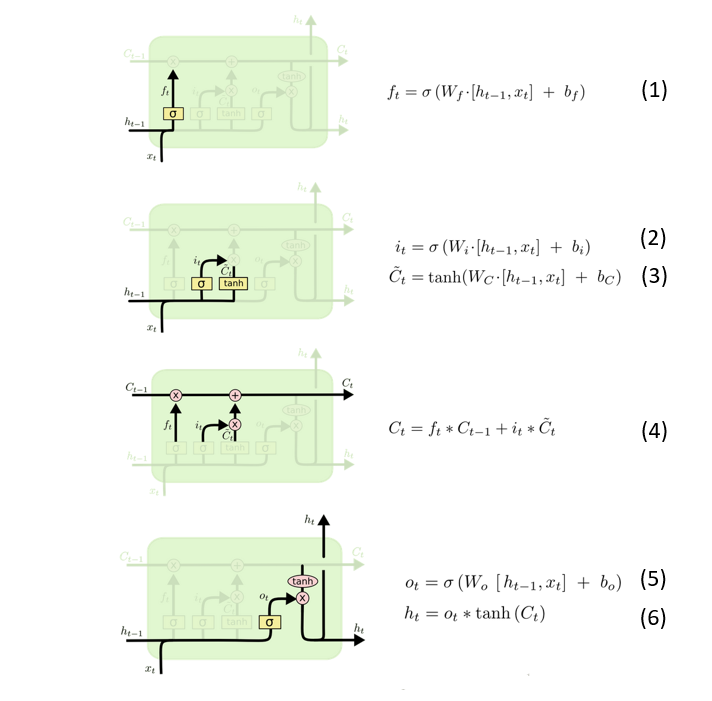
参数num_units=50的话,(在机器学习领域,我们说的向量都是列向量)
对于公式 (1) ,h=50∗1维, x=15∗1维,[h,x]便等于65∗1维,(由于h要输出同样是50维),W=50*65维,W∗[h,x]=50∗65∗65∗1=50∗1维,b=50*1维,所以f=50*1维
对于公式 (2) 和 (3),同上可分析得 i=50∗1维,$\hat C$=50*1维
对于公式(4),f(t)=50*1维,C(t−1)=50∗1,f(t).∗C(t−1) = 50*1 点乘 50*1 = 50*1,i点乘$\hat C$=50*1点乘50*1=50*1维,所以$C_t$=50*1维
对于公式 (5) 和 (6) , 同理可得 O=50∗1=50∗1 维,h=O点乘tanh(C)=50∗1
所以最后LSTM单元输出的h就是 50*1 的向量
以上就是 num_units 参数的含义
我们接着讲:上面我们只是讲了单隐层的LSTM,比如现在输入的是ufn序列中的u(u已经被embeding成15维向量),我们希望对应的target为fnu,即希望输出f(u -> f),状态向量继续流入下一个LSTM单元,同时输出也流入下一个单元与新的输入f合并成新的65维向量,继续进行上面公式(1)到(6)的操作,请注意:我们目前只是单隐层的LSTM单元前后连接,我们也可以创建多隐层的LSTM,上下叠加(这里前后和上下叠加是形象化解释,便于理解),请参考
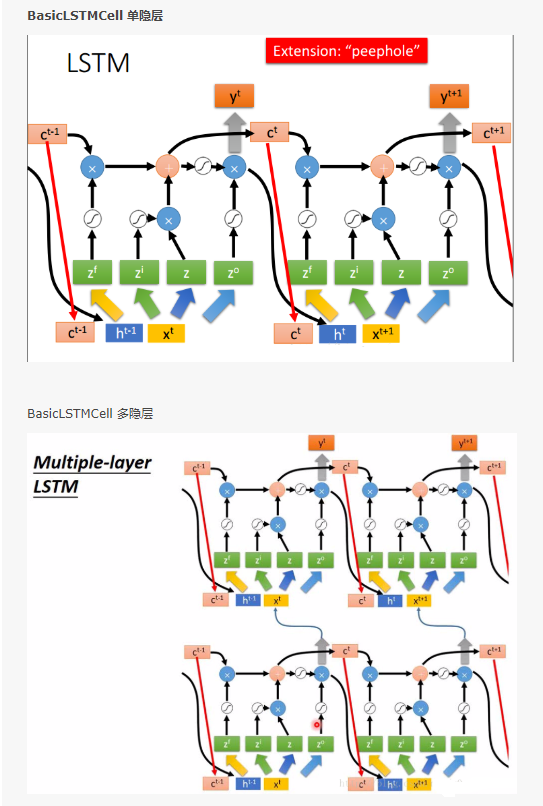
我们使用tensorflow可以轻松的创建多隐藏的LSTM:
# RNN cell,这里rnn_size=50,num_layers=2,就是说我们创建的是双隐层的LISTM
#这里注意:我们的两个隐层,他们的rnn_size都是50,我们也可以为每个隐层设置不同的rnn_size
#这里的rnn_size,就说tensorflow该函数官方参数num_units
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
cell = tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
目前,我们已经可以为每一batch(128个样本,也就是128行序列)数据进行embeding(从2维变成了3维:如输入Input是128*7,字嵌入后变成128*7*15),并且已经创建了双隐层的LSTM,而且还已经知道了每个序列的长度(未进行PAD的长度,也就是我们序列的有效长度,因为进行PAD后长度都是7了),我们可以利用tf.nn.dynamic_rnn()获取output和state
def get_encoder_layer(input_data, rnn_size, num_layers,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
'''
构造Encoder层
参数说明:
- input_data: 输入tensor
- rnn_size: rnn隐层结点数量
- num_layers: 堆叠的rnn cell数量
- source_sequence_length: 源数据的序列长度
- source_vocab_size: 源数据的词典大小
- encoding_embedding_size: embedding的大小
'''
# Encoder embedding
encoder_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
cell = tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output, encoder_state = tf.nn.dynamic_rnn(cell, encoder_embed_input,
sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
这里需要记录一下encoder_output和encoder_state的shape,划重点了,我们的Input是一个128* 7 * 15的矩阵,我们开始讲解上面的encoder过程:如下图
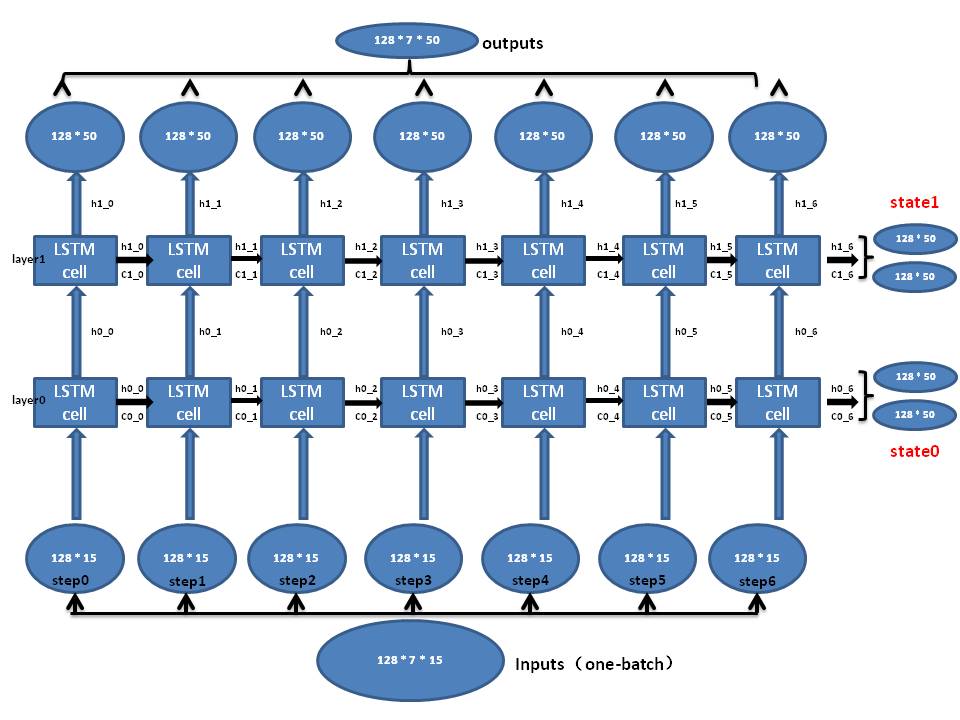
有了上面的图,我们可以测试一下 encoder_output, encoder_state这两个结果的维度,看是否和上图维度一致(是一致的)
这里的data下载,请查看下载链接,提取码:9e6d
import sys
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
class Processing:
def __init__(self, source_file='data/letters_source.txt', target_file='data/letters_target.txt'):
self.source_data = self.safe_open(source_file)
self.target_data = self.safe_open(target_file)
# 构造映射表
self.source_int_to_letter, self.source_letter_to_int = self.extract_character_vocab(self.source_data)
self.target_int_to_letter, self.target_letter_to_int = self.extract_character_vocab(self.target_data)
# 对字母进行转换
self.source_int = self.char_to_int('source')
self.target_int = self.char_to_int('target')
def safe_open(self, file_name):
with open(file_name, 'r', encoding='utf-8') as f:
data = f.read().strip()
return data
def extract_character_vocab(self, data):
"""
构造映射表
< PAD>: 补全字符。
< EOS>: 解码器端的句子结束标识符。
< UNK>: 低频词或者一些未遇到过的词等。
< GO>: 解码器端的句子起始标识符
"""
special_words = ['<PAD>', '<UNK>', '<GO>', '<EOS>']
set_words = sorted(list(set([character for line in data.split('\n') for character in line])))
# 这里要把四个特殊字符添加进词典
int_to_vocab = {idx: word for idx, word in enumerate(special_words + set_words)}
vocab_to_int = {word: idx for idx, word in int_to_vocab.items()}
return int_to_vocab, vocab_to_int
def char_to_int(self, sequence):
if sequence == 'source':
return [[self.source_letter_to_int.get(letter, self.source_letter_to_int['<UNK>']) for letter in line]
for line in self.source_data.split('\n')]
elif sequence == 'target':
return [[self.target_letter_to_int.get(letter, self.target_letter_to_int['<UNK>']) for letter in line] + [self.target_letter_to_int['<EOS>']]
for line in self.target_data.split('\n')]
else:
print('Please input the sequence you want to convert into int!')
sys.exit()
def pad_sentence_batch(self, sentence_batch, pad_int):
"""
对batch中的序列进行补全,保证batch中的每行都有相同的sequence_length
参数:
- sentence batch
- pad_int: <PAD>对应索引号
"""
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
def get_batches(self, targets, sources, batch_size, source_pad_int, target_pad_int):
"""
定义生成器,用来获取batch
"""
print('sources length in get_batches:', len(sources), len(sources) // batch_size)
for batch_i in range(0, len(sources) // batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
# 补全序列
pad_sources_batch = np.array(self.pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(self.pad_sentence_batch(targets_batch, target_pad_int))
# 记录每条记录的长度
targets_lengths = []
for target in targets_batch:
targets_lengths.append(len(target))
source_lengths = []
for source in sources_batch:
source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, targets_lengths, source_lengths
class EncodeDecodeModelBuild:
def __init__(self):
pass
# Encoder
# 在Encoder端,我们需要进行两步,第一步要对我们的输入进行Embedding,再把Embedding以后的向量传给RNN进行处理
# 在Embedding中,我们使用tf.contrib.layers.embed_sequence,它会对每个batch执行embedding操作
def get_encoder_layer(self, input_data, rnn_size, num_layers, source_sequence_length, source_vocab_size, encoding_embedding_size):
"""
构造Encoder层
参数说明:
- input_data: 输入tensor
- rnn_size: rnn隐层结点数量
- num_layers: 堆叠的rnn cell数量
- source_sequence_length: 源数据的序列长度,也就是有效长度
- source_vocab_size: 源数据的词典大小
- encoding_embedding_size: embedding的大小
"""
# Encoder embedding,这里进行embedding原理是什么呢?我只提供了序列数字,以及词汇数量,就完成了向量化
encoder_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def get_lstm_cell(rnn_size):
lstm_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return lstm_cell
cell = tf.contrib.rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)])
encoder_output, encoder_state = tf.nn.dynamic_rnn(
cell, encoder_embed_input, sequence_length=source_sequence_length, dtype=tf.float32)
return encoder_output, encoder_state
if __name__ == '__main__':
process = Processing()
print('source_seq:', process.source_data.split('\n')[0:10])
print('target_seq:', process.target_data.split('\n')[0:10])
print('source_int_to_letter', process.source_int_to_letter)
print('source_letter_to_int', process.source_letter_to_int)
print('target_int_to_letter', process.target_int_to_letter)
print('target_letter_to_int', process.target_letter_to_int)
source_letter_to_int = process.source_letter_to_int
target_letter_to_int = process.target_letter_to_int
encode_decode = EncodeDecodeModelBuild() # 实例化,没什么初始化操作
# 超参数
# Batch Size
batch_size = 128
# RNN Size
rnn_size = 50
# Number of Layers
num_layers = 2
# Embedding Size
encoding_embedding_size = 15
valid_source = process.source_int[:batch_size]
valid_target = process.target_int[:batch_size]
print('valid_source[0:10]:', valid_source[0:10])
print('valid_target[0:10]:', valid_target[0:10])
(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(
process.get_batches(
valid_target, valid_source, batch_size,
process.source_letter_to_int['<PAD>'],
process.target_letter_to_int['<PAD>'])
)
print('valid_sources_batch[0:10]:', valid_sources_batch[0:10])
print('valid_targets_batch[0:10]:', valid_targets_batch[0:10])
print('valid_sources_lengths[0:10]:', valid_sources_lengths[0:10])
print('valid_targets_lengths[0:10]:', valid_targets_lengths[0:10])
input_data = valid_sources_batch
targets = valid_targets_batch
source_sequence_length = valid_sources_lengths
target_sequence_length = valid_targets_lengths
max_target_sequence_length = 7
source_vocab_size = len(source_letter_to_int)
encoder_output, encoder_state = encode_decode.get_encoder_layer(
input_data, rnn_size, num_layers, source_sequence_length, source_vocab_size, encoding_embedding_size)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print('encoder_output.shape:', sess.run(encoder_output).shape)
print('\n')
print(sess.run(encoder_state[0]))
print('0-c:', sess.run(encoder_state[0][0]).shape)
print('0-h:', sess.run(encoder_state[0][1]).shape)
print('\n')
print(sess.run(encoder_state[1]))
print('1-c:', sess.run(encoder_state[1][0]).shape)
print('1-h:', sess.run(encoder_state[1][1]).shape)
'''
encoder_output.shape: (128, 7, 50)
LSTMStateTuple(c=array([[-0.04304752, -0.03509561, 0.08023848, ..., 0.00869391,
-0.05691399, -0.0037792 ],
[ 0.00383653, -0.00961697, -0.00571259, ..., -0.06620879,
-0.03612325, -0.05058336],
[-0.01471607, -0.00054711, -0.00437702, ..., -0.04058436,
-0.08962905, -0.00147169],
...,
[ 0.05962741, 0.03080438, -0.01021096, ..., 0.03458264,
-0.01859237, -0.00854286],
[ 0.10512877, 0.05675253, -0.05238747, ..., 0.08558378,
0.03848773, 0.0153399 ],
[-0.00535806, -0.00980609, -0.00647817, ..., 0.01386383,
0.00361691, -0.01494723]], dtype=float32), h=array([[-0.02223058, -0.01775076, 0.03938275, ..., 0.00433571,
-0.02808682, -0.00186137],
[ 0.00186763, -0.00502355, -0.00283817, ..., -0.0320057 ,
-0.01752974, -0.02522181],
[-0.00723557, -0.00028466, -0.00215382, ..., -0.02022631,
-0.04316105, -0.00071936],
...,
[ 0.02942469, 0.01522003, -0.00491344, ..., 0.01708112,
-0.00908282, -0.00431359],
[ 0.0540871 , 0.02825295, -0.02745056, ..., 0.04257125,
0.01909489, 0.00735466],
[-0.00273725, -0.00494143, -0.00335784, ..., 0.00702268,
0.00177948, -0.00720975]], dtype=float32))
0-c: (128, 50)
0-h: (128, 50)
LSTMStateTuple(c=array([[-1.5820017e-02, -2.6942336e-03, -1.0050132e-03, ...,
8.5409246e-03, 6.6550612e-03, 8.1391260e-03],
[ 7.7295029e-03, 4.1437177e-03, 4.6428009e-03, ...,
1.1356347e-02, 8.1963371e-05, -7.8776069e-03],
[ 1.0825472e-02, 4.3439609e-03, 1.2341643e-02, ...,
1.4018469e-02, 1.0256685e-02, 8.7942984e-03],
...,
[-3.0825241e-03, -2.2337481e-05, -6.5338850e-04, ...,
-6.1642872e-03, -1.1415123e-03, 7.1417345e-03],
[-1.2705816e-02, -1.6099531e-03, 2.2869529e-02, ...,
-2.3452278e-02, -7.6105753e-03, 7.6716589e-03],
[-1.0074907e-03, 3.4129494e-05, -1.8248253e-03, ...,
-5.8616372e-04, -1.6492521e-03, -8.0834865e-04]], dtype=float32), h=array([[-7.8813164e-03, -1.3356666e-03, -5.0444109e-04, ...,
4.2508096e-03, 3.3232903e-03, 4.0544183e-03],
[ 3.8475350e-03, 2.0742973e-03, 2.3326257e-03, ...,
5.6687519e-03, 4.0923649e-05, -3.9418442e-03],
[ 5.4338807e-03, 2.1625140e-03, 6.1921040e-03, ...,
6.9652013e-03, 5.1008761e-03, 4.3697306e-03],
...,
[-1.5396455e-03, -1.1132359e-05, -3.2613808e-04, ...,
-3.0813138e-03, -5.6903326e-04, 3.5529216e-03],
[-6.3411035e-03, -8.0282643e-04, 1.1467443e-02, ...,
-1.1772511e-02, -3.8120230e-03, 3.8370693e-03],
[-5.0305878e-04, 1.7079228e-05, -9.1262913e-04, ...,
-2.9348588e-04, -8.2494150e-04, -4.0417191e-04]], dtype=float32))
1-c: (128, 50)
1-h: (128, 50)
'''
说完了encode,我们说一下decode,先对target进行处理
# Decoder
# 先对target数据进行预处理
def process_decoder_input(self, data, vocab_to_int, batch_size):
"""
补充<GO>,并移除最后一个字符
"""
# cut掉最后一个字符
data = tf.constant(data, dtype=tf.int32)
ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1])
# vocab_to_int['<GO>']在本例中是2,经过在列维度上的合并,每个序列都是以GO(对应数值为2)开头
decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1)
return decoder_input
前面我们已经有了该batch的targets序列,target_letter_to_int以及batch_size=128,那么我们看看上面的process_decoder_input做了什么骚操作:
''' valid_targets_batch[0:10]: [[ 4 5 20 20 22 3 0 0] [17 19 28 3 0 0 0 0] [ 5 13 15 24 26 3 0 0] [ 5 20 25 3 0 0 0 0] [ 4 12 14 15 3 0 0 0] [ 4 7 7 16 23 3 0 0] [ 7 8 10 13 19 19 27 3] [17 19 22 25 3 0 0 0] [11 15 18 24 29 3 0 0] [ 6 14 15 16 20 3 0 0]] 经过process_decoder_input(targets, target_letter_to_int, batch_size)骚操作后 就在target首位添加了数字2:'GO',并去掉了原来target序列补充的一个数字0 decoder_input: [[ 2 4 5 20 20 22 3 0] [ 2 17 19 28 3 0 0 0] [ 2 5 13 15 24 26 3 0] [ 2 5 20 25 3 0 0 0] [ 2 4 12 14 15 3 0 0] [ 2 4 7 7 16 23 3 0] [ 2 7 8 10 13 19 19 27] [ 2 17 19 22 25 3 0 0] [ 2 11 15 18 24 29 3 0] [ 2 6 14 15 16 20 3 0]] '''
对tf.strided_slice,tf.fill,tf.concat感兴趣的可以参考这个例子
我们先进行embedding,即对decoder_input进行embedding,这样我们就获得了一个三维矩阵:128 * 8 * 15
# 1. Embedding target_vocab_size = len(target_letter_to_int) decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size])) decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
如何理解呢?不难,请参考
然后构建decoder中RNN单元,代码和encoder一样,不做解释
# 1. Embedding
target_vocab_size = len(target_letter_to_int)
# 创建一个shape为[target_vocab_size, decoding_embedding_size]的矩阵变量,这里为[30, 15]
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
# 2. 构造Decoder中的RNN单元
def get_decoder_cell(rnn_size):
decoder_cell = tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed= 2
return decoder_cell
cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)])
然后构建输出全连接层(获得每个字符的输出概率)
from tensorflow.python.layers.core import Dense
output_layer = Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
全连接层例子,自己没找到合适的Dense()函数例子,但可以参考这个理解

