
情感分析-英文电影评论
一、简介
情感分析,有时也称为观点挖掘,是NLP领域一个非常重要的一个分支,它主要分析评论、文章、报道等的情感倾向,掌握或了解人们这些情感倾向非常重要。这些倾向对我们处理后续很多事情都有指定或借鉴作用
在NLP中,首先需要把文本或单词等转换为数值格式,为后续机器学习或深度学习使用,把文本或单词转换为数值,有几种模型,如词袋模型(bag of words或简称为BOW)、word2vec等
下面实例讲解一下BOW模型:
a)BOW的假设前提
BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现
也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立存在
b)TF-IDF
假设有三个文档:
1、The sun is shining
2、The weather is sweet
3、The sun is shining and the the weather is sweet
基于这三个文本文档(为简便这里以一个句子代表一个文档),构造一个词典或词汇库。如果构建词典?首先,看出现哪些单词,然后,给每个单词编号。
在这三个文档中,共出现7个单词(不区分大小写),分别是:the,is ,sun,shining,and,weather,sweet
然后,我们把这7个单词给予编号,从0开始,从而得到一个单词vs序号的字典:{'and':0,'is':1,'shining':2,'sun':3,'sweet':4,'the':5,'weather':6}
现在根据这个字典,把以上三个文档转换为特征向量(在对应序列号中是否有对应单词及出现的频率):
第一句可转换为:[0 1 1 1 0 1 0]
第二句可转换为:[0 1 0 0 1 1 1]
第三句可转换为:[1 2 1 1 1 2 1]
0表示字典中对应单词在文档中未出现,1表示对应单词在文档出现一次,2表示出现2次,也就是tf(t,d)表示单词t在文档d出现的次数
如果有几个文档,而且有些单词在每个文档中出现的频度都较高,这种频繁出现的单词往往不含有用或特别的信息,在向量中如何降低这些单词的权重?这里我们可以采用逆文档频率(inverse document frequency,idf)技术来处理
原始词频结合逆文档频率,称为词频-逆文档词频(term frequency - inverse document frequency,简称为tf-idf),那么tf-idf如何计算呢?计算公式如:\(tf-idf(t,d)=tf(t,d)*idf(t,d)\)
其中:\(idf(t,d)=log(n_d/(1+df(d,t)))\),\(n_d\)表示总文档数(这里总文档数为3),\(df(d,t)\)为文档d中的单词t涉及的文档数量
取对数是为了保证文档中出现频率较低的单词被赋予较大的权重,分母中的加1是为了防止\(df(d,t)\)为零的情况。有些模型中也会在分子加上1,分子变为\(1+n_d\)
如我们看单词the在第一个句子或第一个文档(d1来表示)中的\(tf-idf(t,d)\)的值:\(tf-idf('the',d1) = tf('the',d1) * idf('the',d1) = 1 * log3/(1+3) = 1 * log0.75 = log0.75\)
这些计算都有现成的公式,以下我们以Scikit-learn中公式或库来计算
from sklearn.feature_extraction.text import CountVectorizer count = CountVectorizer() docs = np.array( ['The sun is shining', 'The weather is sweet', 'The sun is shining and the weather is sweet']) bag = count.fit_transform(docs) print(count.vocabulary_)
先导入countVectorizer库,然后实例化对象count,转换成字典:
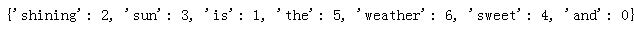
然后文档向量化,结果和我们在前面讲的文档的向量化结果一样:
print(bag.toarray())

进而我们求出文档的tf-idf:
from sklearn.feature_extraction.text import TfidfTransformer tfidf = TfidfTransformer() np.set_printoptions(precision=2) print(tfidf.fit_transform(bag).toarray())

说明:sklearn计算tf-idf时,还进行了归一化处理,其中TfidfTransformer缺省使用L2范数
我们按照sklearn的计算方式,即\(tf-idf(t,d) = tf(t,d) * ( log[(1+n_d) / (1+df(d,t)] + 1 ) \),不难验证以上结果,以第一语句为例:
第一个元素下标是0,即and词频是0,所以tf-idf值是0
第二个元素下标是1,即is词频是1,idf为:1+3 = 4,然后除以(1+涉及的文档数=1+3 = 4),取ln值为0,然后再加1,所以tf-idf值是1
第三个元素下标是2,即shining词频是1,idf为:1+3 = 4,然后除以(1+涉及的文档数=1+2=3),ln(4/3)值为0.287657,然后再加1,所以tf-idf值为1.28
......
第七个元素下标是6,即weather词频是0,所以idf值为0
综上所述:第一个语句(文档)的向量结果: \(v = tf-idf(t,d1)=[0, 1, 1.28, 1.28, 0, 1, 0]\),各个元素平方和为:\(0 + 1 + 1.28^2 + 1.28^2 + 0 + 1 + 0 = 5.2768\)
\(tf-idf(t,d1)norm = |v|/sqrt(\sum v_i^2) = v/sqrt(5.2768) = v/2.29 = [0, 0.43, 0.56, 0.56, 0, 0.43, 0]\),这与sklearn计算出来的tf-idf结果一致
二、英文电影评论情感分析实例
1)数据下载
链接:http://ai.stanford.edu/~amaas/data/sentiment,为了防止读者无法打开该链接,故将下载的文件:aclImdb_v1.tar.gz上传到百度云盘,链接:https://pan.baidu.com/s/1AuMyDBuJcZ-KT5AvsdXQig 提取码:6m11
在桌面新建情感分析文件夹,将下载数据解压到情感分析文件夹,情感分析/aclImdb文件夹下有如下文件:

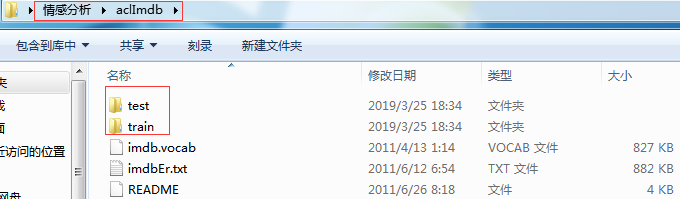
在train和test目录下,各有二级子目录neg和pos目录。其中neg目录存放大量评级负面或消极txt文件,pos存放大量评级为正面或积极的评论txt文件:(train和test目录结构如下)
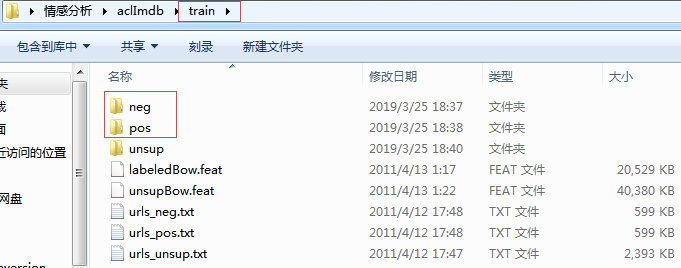
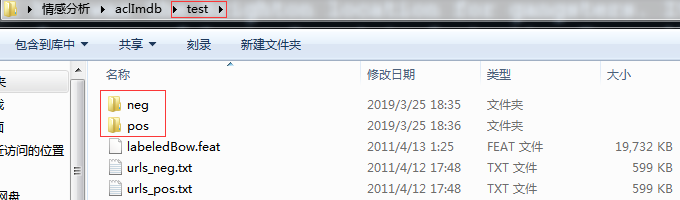
在情感分析文件夹内按住shift,然后鼠标右键,在此窗口打开命令窗口,输入jupyter notebook,然后新建名为emotion_analysis的脚本文件:

2)数据处理
pyprind是进度条小工具,可能需要读者安装:pip install pyprind
我们把train和test下的neg,pos的评论合并到一块儿,处理数据的过程中用进度条显示进度:
import pandas as pd
import os
import pyprind
pbar = pyprind.ProgBar(50000)
labels = {'pos':1, 'neg':0}
df = pd.DataFrame()
for s in ('test', 'train'):
for l in ('pos', 'neg'):
path = './aclImdb/%s/%s' % (s, l)
for file in os.listdir(path):
with open(os.path.join(path, file), 'r',encoding='UTF-8') as infile:
txt = infile.read()
df = df.append( [[txt, labels[l]]], ignore_index=True )
pbar.update()
df.columns = ['review', 'sentiment']
可以看出处理时间不足2分钟:
为了让数据产生随机化的效果(sklearn.utils.shuffle),我们打乱数据,然后保存到csv文件:
from sklearn.utils import shuffle
df = shuffle(df)
df.to_csv('./movie_data.csv', index = False)

重新加载数据,发现label已经被打乱:
df = pd.read_csv('./movie_data.csv')
df.head(10)
3)NLTK处理
a)下载停词
import nltk
nltk.download('stopwords')
如下显示下载成功

b)对文件进行预处理,过滤停词、删除多余符号等
我们发现文件内容中含有许多下图的thml标签字符,如10011_9.txt文件中:

我们需要将其去掉:
import re
s = 'movies of the summer.<br /><br />Robin Williams'
re.sub('<[^>]*>', '', s)
#'movies of the summer.Robin Williams'
^用在中括号中表示非,\W表示非单词字符,比如空格括号等等:
from nltk.corpus import stopwords
import re
stop = stopwords.words('english')
def tokenizer(text):
text = re.sub('<[^>]*>', '', text)
text=re.sub( '[\W]+',' ',text.lower() )
tokenized=[w for w in text.split() if w not in stop]
return tokenized
上面使用\W,去掉了非单词字符
c)定义一个生成器函数,从csv文件中读取文档
def stream_docs(path):
with open(path, 'r', encoding='UTF-8') as csv:
next(csv)#skip header
for line in csv:#这里没有分割,并且没有去掉尾部换行符,所以下标-1代表换行符,-2就是标签,-3就是逗号
text, label = line[:-3], int(line[-2])
yield text, label
来看看movie_data.csv文件:

关于生成器函数:生成一个 iterable 对象,目的节省内存,下面我们来看看示例:
doc_stream = stream_docs(path='./movie_data.csv') text, label = next(doc_stream) print(text, label) #再获取一个元素 text, label = next(doc_stream) print(text, label)
代码示例,通过next()函数获取可迭代对象元素值:
通过上面的小例子展示函数生成器返回一个 iterable 对象,如上面的doc_stream就是一个 iterable 对象
d)定义一个每次获取的小批量数据的函数
def get_minibatch(doc_stream, size):
docs, y = [], []
try:
for _ in range(size):
text, label = next(doc_stream)
docs.append(text)
y.append(label)
except StopIteration:
return None,None
return docs, y
代码示例,我们看看小批量数据函数,我们将size设置为3,读取文件的三行,而doc_stream是一个可迭代对象:
doc_stream = stream_docs(path='./movie_data.csv')
docs, y = get_minibatch(doc_stream, 3)
for i in range(3):
print(docs[i])
print(y[i])
代码示例结果:

e)利用sklearn中的HashingVectorizer进行语句的特征化、向量化等
from sklearn.feature_extraction.text import HashingVectorizer from sklearn.linear_model import SGDClassifier vect = HashingVectorizer( decode_error='ignore', n_features=2**2, preprocessor=None, tokenizer=tokenizer) clf = SGDClassifier(loss='log', random_state=1, n_iter=1) doc_stream = stream_docs(path='./movie_data.csv')
4)训练模型
import pyprind
import numpy as np
import warnings
warnings.filterwarnings('ignore')
pbar = pyprind.ProgBar(45)
classes = np.array([0, 1])
for _ in range(45):
x_train, y_train = get_minibatch(doc_stream, size=1000)
if not x_train:
break
x_train = vect.transform(x_train)
clf.partial_fit(x_train, y_train, classes=classes)
pbar.update()
代码示例结果:

5)评估模型
x_test, y_test = get_minibatch(doc_stream, size=5000)
x_test = vect.transform(x_test)
print('accuracy: %.3f' % clf.score(x_test, y_test))
代码示例结果:

准确率达到了87%
6)完整代码
#coding=utf-8
import pandas as pd
import os
import pyprind
pbar = pyprind.ProgBar(50000)
#将train和test的pos和neg合并
labels = {'pos':1, 'neg':0}
df = pd.DataFrame()
for s in ('test', 'train'):
for l in ('pos', 'neg'):
path = './aclImdb/{}/{}'.format(s, l)
for file in os.listdir(path):
with open(os.path.join(path, file), 'r',encoding='UTF-8') as infile:
txt = infile.read()
df = df.append( [ [txt, labels[l]] ], ignore_index=True )
pbar.update()
df.columns = ['review', 'sentiment']
from sklearn.utils import shuffle
df = shuffle(df)
df.to_csv('./movie_data.csv', index = False)
df = pd.read_csv('./movie_data.csv')
print('df_to_csv done!')
#预处理
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
import re
stop = stopwords.words('english')
def tokenizer(text):
text=re.sub('<[^>]*>','',text)
emoticons=re.findall('(?::|;|=)(?:-)?(?:</span>|<spanclass="es0">|D|P)',text.lower())
text=re.sub('[\W]+',' ',text.lower())+' '.join(emoticons).replace('-','')
tokenized=[w for w in text.split() if w not in stop]
return tokenized
def stream_docs(path):
with open(path, 'r', encoding='UTF-8') as csv:
next(csv)#skip header
for line in csv:#这里没有分割,并且没有去掉尾部换行符,所以下标-1代表换行符,-2就是标签,-3就是逗号
text, label = line[:-3], int(line[-2])
yield text, label
def get_minibatch(doc_stream, size):
docs, y = [], []
try:
for _ in range(size):
text, label = next(doc_stream)
docs.append(text)
y.append(label)
except StopIteration:
return None,None
return docs, y
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.linear_model import SGDClassifier
vect = HashingVectorizer( decode_error='ignore', n_features=2**21, preprocessor=None, tokenizer=tokenizer)
clf = SGDClassifier(loss='log', random_state=1, n_iter=1)
doc_stream = stream_docs(path='./movie_data.csv')
import pyprind
import numpy as np
import warnings
warnings.filterwarnings('ignore')
pbar = pyprind.ProgBar(45)
classes = np.array([0, 1])
for _ in range(45):
x_train, y_train = get_minibatch(doc_stream, size=1000)
if not x_train:
break
x_train = vect.transform(x_train)
clf.partial_fit(x_train, y_train, classes=classes)
pbar.update()
x_test, y_test = get_minibatch(doc_stream, size=5000)
x_test = vect.transform(x_test)
print('accuracy: %.3f' % clf.score(x_test, y_test))
三、致谢
本文参考:http://www.feiguyunai.com/index.php/2017/10/20/pythonai-nlp-emotionanaly01/
感谢作者的分享,另外本人已经将代码上传百度云盘, 提取码:iyi5
