基于jieba,TfidfVectorizer,LogisticRegression进行搜狐新闻文本分类
一、简介
此文是对利用jieba,word2vec,LR进行搜狐新闻文本分类的准确性的提升,数据集和分词过程一样,这里就不在叙述,读者可参考前面的处理过程
经过jieba分词,产生24000条分词结果(sohu_train.txt有24000行数据,每行对应一个分词结果)
with open('cutWords_list.txt') as file:
cutWords_list = [ k.split() for k in file ]

1)TfidfVectorizer模型
调用sklearn.feature_extraction.text库的TfidfVectorizer方法实例化模型对象。TfidfVectorizer方法4个参数含义:
- 第1个参数是分词结果,数据类型为列表,其中的元素也为列表
- 第2个关键字参数stop_words是停顿词,数据类型为列表
- 第3个关键字参数min_df是词频低于此值则忽略,数据类型为int或float
- 第4个关键字参数max_df是词频高于此值则忽略,数据类型为int或float
from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer(cutWords_list, stop_words=stopword_list, min_df=40, max_df=0.3)
2)特征工程
X = tfidf.fit_transform(train_df['文章'])
print('词表大小', len(tfidf.vocabulary_))
print(X.shape)
可见每篇文章内容被向量化,维度特征时3946
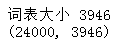
3)模型训练
3.1)LabelEncoder
from sklearn.preprocessing import LabelEncoder
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
labelEncoder = LabelEncoder()
y = labelEncoder.fit_transform(train_df[0])#一旦给train_df加上columns,就无法使用[0]来获取第一列了
y.shape
3.2)逻辑回归
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2) logistic_model = LogisticRegression(multi_class = 'multinomial', solver='lbfgs') logistic_model.fit(train_X, train_y) logistic_model.score(test_X, test_y)
其中逻辑回归参数官方文档:http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html

3.3)保存模型
调用pickle:pip install pickle
第1个参数是保存的对象,可以为任意数据类型,因为有3个模型需要保存,所以下面代码第1个参数是字典
第2个参数是保存的文件对象
import pickle
with open('tfidf.model', 'wb') as file:
save = {
'labelEncoder' : labelEncoder,
'tfidfVectorizer' : tfidf,
'logistic_model' : logistic_model
}
pickle.dump(save, file)
3.4)交叉验证
在进行此步的时候,不需要运行此步之前的所有步骤,即可以重新运行jupyter notebook。然后调用pickle库的load方法加载保存的模型对象,代码如下:
import pickle
with open('tfidf.model', 'rb') as file:
tfidf_model = pickle.load(file)
tfidfVectorizer = tfidf_model['tfidfVectorizer']
labelEncoder = tfidf_model['labelEncoder']
logistic_model = tfidf_model['logistic_model']
load模型后,重新加载测试集:
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
X = tfidfVectorizer.transform(train_df[1])
y = labelEncoder.transform(train_df[0])
调用sklearn.linear_model库的LogisticRegression方法实例化逻辑回归模型对象。
调用sklearn.model_selection库的ShuffleSplit方法实例化交叉验证对象。
调用sklearn.model_selection库的cross_val_score方法获得交叉验证每一次的得分。
最后打印每一次的得分以及平均分,代码如下:
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import ShuffleSplit from sklearn.model_selection import cross_val_score logistic_model = LogisticRegression(multi_class='multinomial', solver='lbfgs') cv_split = ShuffleSplit(n_splits=5, test_size=0.3) score_ndarray = cross_val_score(logistic_model, X, y, cv=cv_split) print(score_ndarray) print(score_ndarray.mean())

4)模型评估
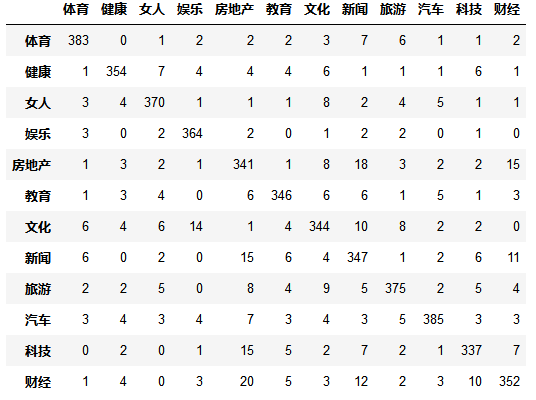
绘制混淆矩阵:
from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegressionCV from sklearn.metrics import confusion_matrix import pandas as pd train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2) logistic_model = LogisticRegressionCV(multi_class='multinomial', solver='lbfgs') logistic_model.fit(train_X, train_y) predict_y = logistic_model.predict(test_X) pd.DataFrame(confusion_matrix(test_y, predict_y),columns=labelEncoder.classes_, index=labelEncoder.classes_)
绘制precision、recall、f1-score、support报告表:
import numpy as np
from sklearn.metrics import precision_recall_fscore_support
def eval_model(y_true, y_pred, labels):
#计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support( y_true, y_pred)
#计算总体的平均Precision, Recall, f1, support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': labels,
u'Precision' : p,
u'Recall' : r,
u'F1' : f1,
u'Support' : s
})
res2 = pd.DataFrame({
u'Label' : ['总体'],
u'Precision' : [tot_p],
u'Recall': [tot_r],
u'F1' : [tot_f1],
u'Support' : [tot_s]
})
res2.index = [999]
res = pd.concat( [res1, res2])
return res[ ['Label', 'Precision', 'Recall', 'F1', 'Support'] ]
predict_y = logistic_model.predict(test_X)
eval_model(test_y, predict_y, labelEncoder.classes_)
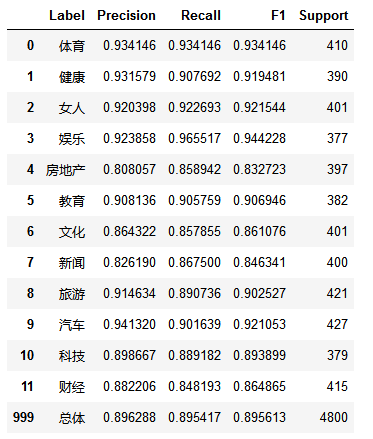
5)模型测试
import pandas as pd
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_X = tfidfVectorizer.transform(test_df[1])
test_y = labelEncoder.transform(test_df[0])
predict_y = logistic_model.predict(test_X)
eval_model(test_y, predict_y, labelEncoder.classes_)
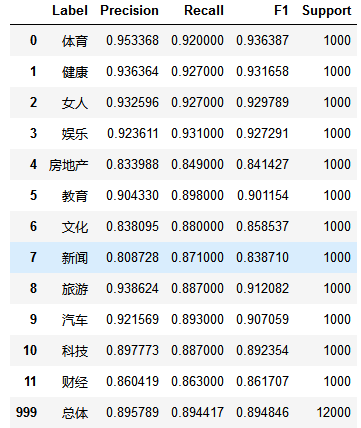
6)总结
训练集数据共有24000条,测试集数据共有12000条。经过交叉验证,模型平均得分为0.8711
模型评估时,使用LogisticRegressionCV模型,得分提高了3%,为0.9076
最后在测试集上的f1-score指标为0.8990,总体来说这个分类模型较优秀,能够投入实际应用
7)致谢
本文参考简书:https://www.jianshu.com/p/96b983784dae
感谢作者的详细过程,再次感谢!
8)流程图