

关于情感分类(Sentiment Classification)的文献整理
最*对NLP中情感分类子方向的研究有些兴趣,在此整理下个人阅读的笔记(持续更新中):
1. Thumbs up? Sentiment classification using machine learning techniques
年份:2002;关键词:ML;引用量:9674;推荐指数(1-5):2
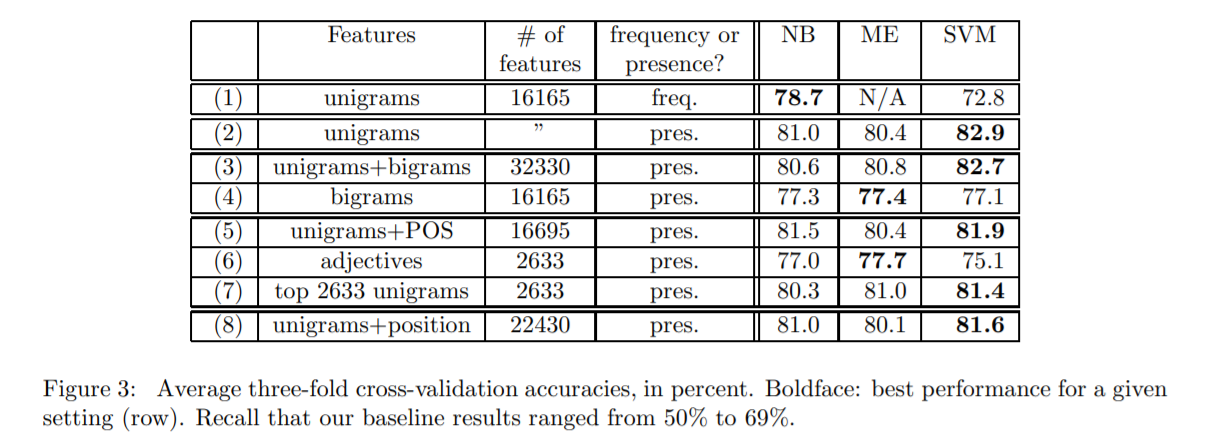
描述:基于电影评价,使用传统ML模型(Navie Bayes, maximum entropy classification和SVM)做情感分析。
心得:
(1)主题分类(Topic Classification)≈情感分类(Sentiment Classification),但后者更难,因为前者更关注于找到识别性强的关键词,而后者更微妙些,比如:电影评价中会有“thwarted expectations”期待受挫败的评价(即用户说了一堆自己原本对电影的正面期待,但最后就说了一句表示不满意的话),这样常误导分类器认为该类评论是正面的,实际上不对。因此“the whole is not necessarily the sum of the parts”是当时研究的一个瓶颈。
(2)简单来说作者的做法是:BOW(基于frequency或presence)+ unigram/bigrams + POS/adjectives/position + NB/ME/SVM。依次讨论下做法各模块:
- BOW:情感分类使用presence的词袋模型更好,主题分类用frequency更好;
- unigram/bigrams:bigrams加入并没有带来提升(原因不明)。作者在选取特征时,全语料库中至少出现4次的unigrams和至少出现7次的bigrams抽出来当特征。另外前者给unigrams考虑了否定标签(not, isn't, didn't等)成"NOT_unigram"。
- POS/adjectives/position: 加入它们效果都没提升(原因不明)。POS是Part of Speech词(例如:名词动词这些,可用Oliver Mason's Qtag标注软件进行标注),考虑到形容词对情感分类重要性,作者才加的。此外,由于用户评论电影可能是按照一定顺序,比如总体情感表达->剧情描述->观点总结,所以才加上位置。
- 模型:SVM表现最好。NB模型有对‘特征相互独立’的前提假设,所以使用bigrams效果会变差,SVM和ME不受bigrams影响。
2. Opinion mining and sentiment analysis
年份:2016;关键词:Survey;引用量:10188;推荐指数(1-5):1
描述:该篇文献综述也是由Bo Pang写的,内容多为理论描述,极少给出具体技术上的描述,有助于了解背景但实用性不太高。我就选读了Classification and extraction这一章节。
心得:我就罗列些值得注意的零散知识点如下:
(1)情感评分预测是一个顺序回归任务(即ordinal regression),因为分数为类似0-5的顺序型数据;
(2)中评不一定客观,有可能是评论者避免被卖家报复而打中评。因此评论的主客观分类是个研究点,主观评论更能对情感分类有帮助。有时单次出现的词可能更具主观性。
(3)对情感分类可能有帮助的点:
- 分词位置;
- 更为复杂的特征;
- 歧义词;
- POS:解决词义模糊;
- 形容词:绑定主观性评论;
- 语法:Dependency-tree-based特征可能优于BOW特征;
- 否定标签Negation;
- 讽刺鉴别;
- 加入topic信息:例如:‘目标研究的党派’和‘候选党派’在文本中被替换为'PARTY'和‘OTHER’;
- Domain Adaption:相同词在不同领域可能有不同含义,例如“go read book”在书评和影评中分别为好评和差评;
- Cross-lingual Adaption:使用机器翻译在情感分析预处理中,可以处理跨语种的情感分类。
3. Deep Learning for Sentiment Analysis: A Survey
年份:2018;关键词:Survey;引用量:422;推荐指数(1-5):4
描述:该篇文献综述总结了用深度学*做情感分析的相关研究,大部分都是罗列了各种技术上的研究描述,总体来说是不错的,推荐看下。
心得:情感分析有三种levels:文档级(Document-level)、句子级(Sentence-level)和立场级(Aspect-level)。Document通过客观性分类(subjectivity classification)知道哪些句子客观性强,再对这些句子进行情感极性分析(polarity classification)得到句子的情感极性(积极/消极),而句子能使用立场抽取(Aspect Extraction)和实体抽取(Entity Extraction)分别抽取出立场(例如:“声音质量”)和实体目标(例如:iPhone)进行情感关联。
(1)文本表征:文本表征有三种做法:BoW,embedding和BoW+embedding。但使用BoW有三种缺点:稀疏性、忽略词顺序、没考虑语义信息。而且在文本表征过程中,有些人会考虑引入其他特征,例如商品评论的文本表征中,会考虑加入用户信息(反映用户个人偏好)和商品信息(商品质量)。很早以前会用parse tree做文本表征,但是CNN、RNN和embedding的出现,逐渐取代了它。
(2)立场情感分类的三大重要任务:对目标target的上下文进行表征;生成target的表征;对具体的target识别它重要的情感上下文(words)。
(3)因为文档包含长依赖关系,所以文档级情感分类常用关注机制。
4. Transformers: State-of-the-Art Natural Language Processing
年份:2018;关键词:开源代码库Transformers;引用量:15;推荐指数(1-5):3
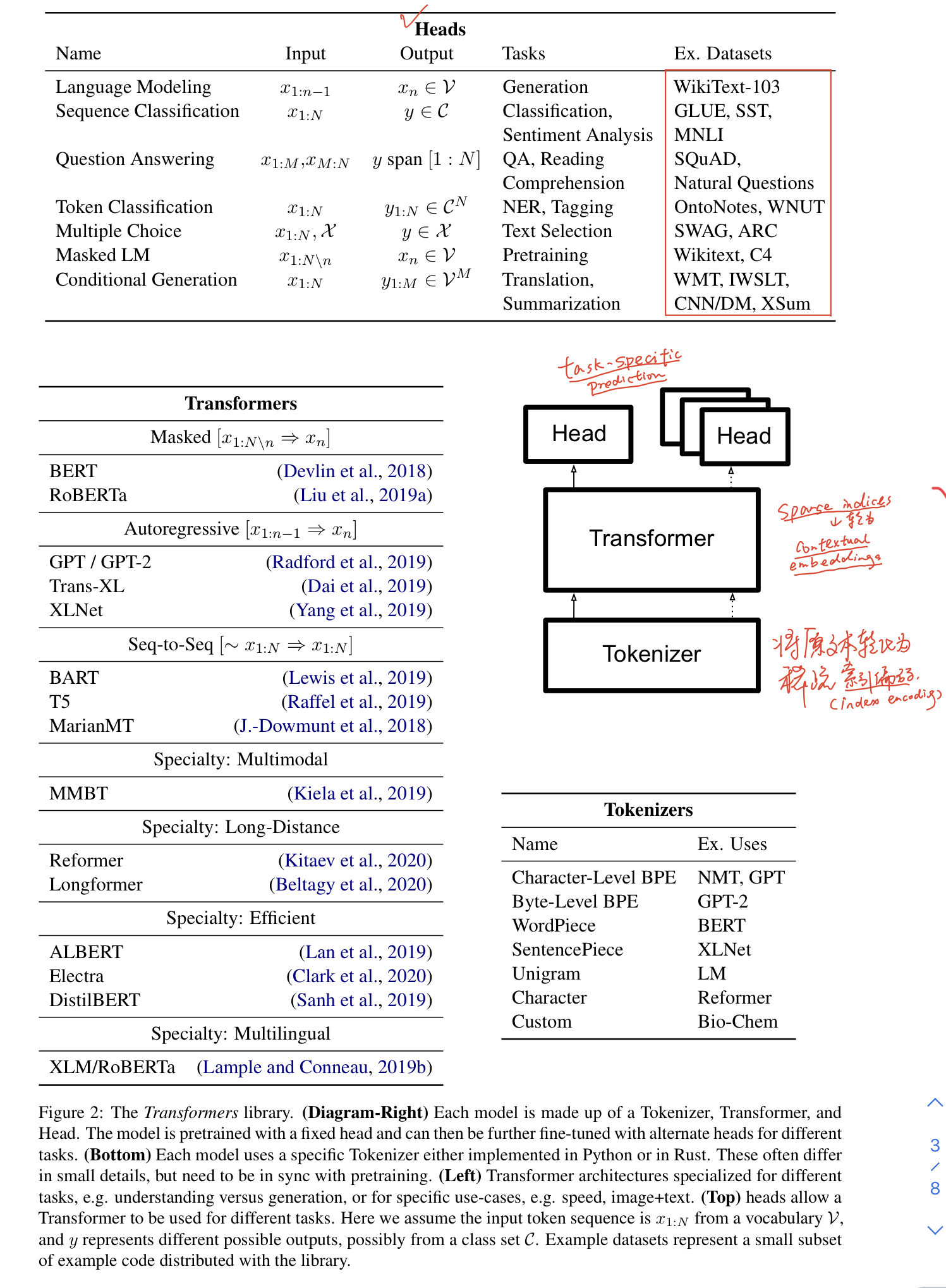
描述:介绍了Transformers库,内含各类基于Transformer的前沿模型和预训练模型权重,可拿来做不同的NLP任务。代码已开源:https://github.com/huggingface/transformers。
心得:很不错的开源代码库,设计的pipeline是:预处理数据、模型应用和预测。主要对应的三个代码模块是:
- tokenizer:将原文本转化为稀疏的索引编码(index encodings);
- transformer:将稀疏索引转化为上下文编码(contextual embeddings);
- head:使用上下文编码做特定任务的预测(task-specific prediction)。
5. RoBERTa: A Robustly Optimized BERT Pretraining Approach
年份:2019;关键词:RoBERTa;引用量:421;推荐指数(1-5):5
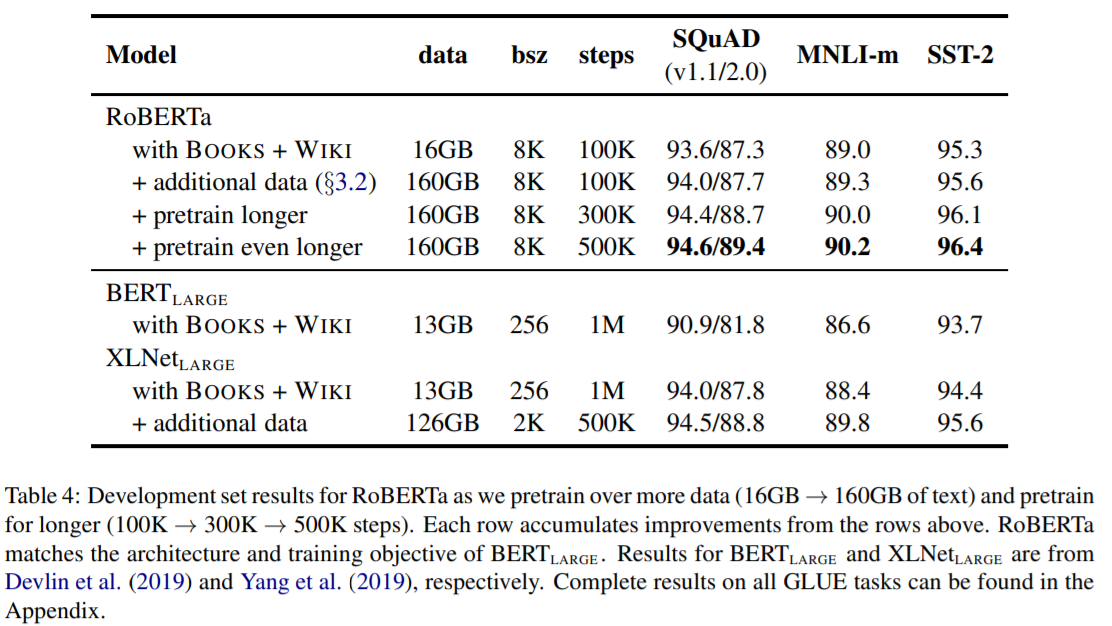
描述:作者对BERT进行预训练优化后使得模型表现提高。优化点有4个:
- 更多数据,训练更久。原BERT使用BOOKCORPUS和English WIKIPEDIA共16G数据训练,而RoBERTa还加入了CC-News,OPENWEBTEXT和STORIES数据集(共计160G数据);此外,通过梯度累计,增大batch size也能提高模型表现。
- 去掉“预测下一句”目标。在BERT预训练时,有两个目标:Masked Language Model(MLM)和Next Sentence Prediction(NSP),NSP是个二分类任务,为了预测是否两个segments片段在原文本里是连续的。该论文作者实验后发现去掉NSP损失会亲为提高下游任务的表现。
- 使用更大的Byte-Pair Encoding(BPE)。BPE是介于字符和单词级别的混合文本表征编码,相比于整个字,它更依赖于subwords单元。
- 采用动态掩码(Dynamic Masking)。原BERT是静态掩码(即在预训练前就进行一次掩码预处理),而动态掩码是每次都想模型输入不同的掩码序列。
心得:RoBERTa现在比较主流的优化预训练BERT的方法了。
6. Pre-Training with Whole Word Masking for Chinese BERT
年份:2019;关键词:WWM;引用量:71;推荐指数(1-5):5
描述:Whole Word Masking(WWM)是BERT一个升级操作。它会将属于一个word的token合并起来。如下图所示:

作者实验发现RoBERT-wwm-ext-large(wwm:Whole Word Masking; ext:extended data; large:网络结构更大,BERT_base是12层,768隐藏层维度,12个关注头,110M的参数量(12×768×12),而BERT_large是24层,1024隐藏层维度,16个关注头,340M的参数量(12*1024*16))表现最好。
心得:作者在最后给了一些建议:
- 起始学*率的设置最重要。BERT和BERT-wwm的学*率*乎相同,可共用。但ERINE(Sun等人提出的Enhanced Representation through kNowledge IntEgration)一定要调lr。
- BERT和BERT-wwm是在维基百科上训练的,所以在正式文本上表现较好。而ERINE有在博客文本上训练,所以在非正式文本上会表现好些。
- 在阅读理解和文本分类上,建议使用BERT/BERT-wwm。
- 做含繁体中文的任务用BERT/BERT-wwm,因为ERINE预处理会清除繁体字。
- 在做新的domain任务前,建议再用新domain数据去预训练下。如果不想再预训练,那就选择相*domain预训练过的模型。
现居地:深圳
兴趣领域:数据挖掘,机器学习及计算机视觉
博客:https://www.cnblogs.com/alvinai/
公众号:zaicode
Github:https://github.com/AlvinAi96
邮箱:alvinai9603@outlook.com



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异