



多文件断点续传组件(MFC ActiveX)
多文件断点续传组件(MFC ActiveX)是一个用于Web上传文件的ActiveX控件,他应该支持断点和多文件异步上传。
针对断点续传组件,我需要解决下面5个问题:
1、 文件状态问题
2、 文件传输效率与安全问题
3、 编码问题
4、 系统设计问题
5、 交互问题
一、文件状态问题
一个文件从被打开到关闭,它需要经过4种状态:初始化、就绪、上传中、完成,而且他们仅有一种转化关系(初始化→就绪→上传中→完成)。实际上,为了实现断点续传,我还需要引进两种状态:等待和暂停。
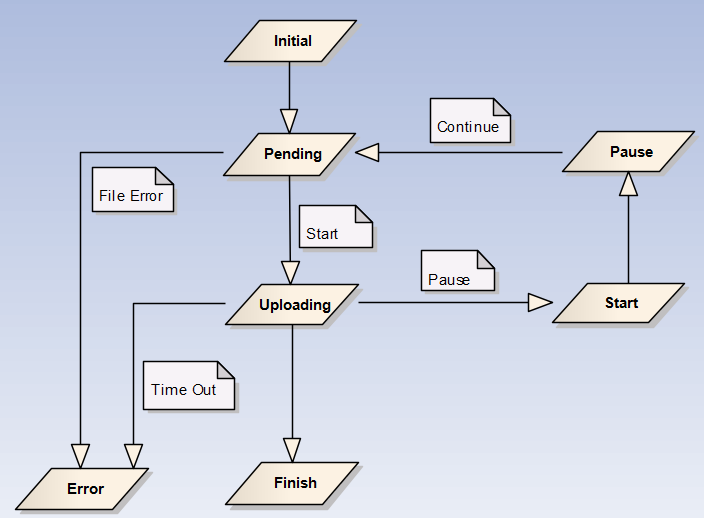
图1
考虑到组件的健壮性,还需要一个“出错”状态来容错(见图1),如上传超时的时候。
二、文件传输效率与安全问题
我们知道,大多数Web服务器出于安全考虑,会限制一次请求上传数据量,比如ASP.NET,默认的文件大小上限为4MB,是为了避免潜在DOS攻击危险。若是攻击者提交了一个或多个大文件,往往会让服务器不堪重负。若是用户上传的文件大于4MB,将会得到“Maximum request length exceeded.”异常信息。当然,我们可以更改默认设置,但是,这样将是以安全为代价去换回文件的上限。我们可以考虑将一个文件分割成多次请求发送,这样做的后果是出现了新的问题——传输效率问题。
假设有一个fKB的文件需要上传,当前网络传输速率vKB/s,每次请求响应时间ts。
文件大小没有上限情况:
![]()
表示完成上传所需要的时间。
文件大小上限为MKB的情况:
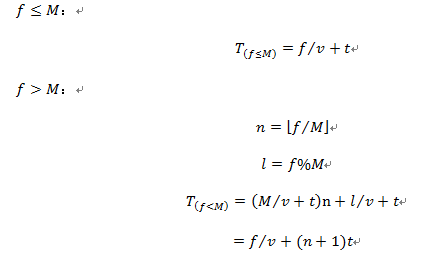
分析可知,当f<M时,由于每次请求都要消耗(n+1)t时间,所以大文件分次传输要比一次传输多耗时,一个常量级的增长是可以接受的。
三、编码问题
从组件向服务器发送的数据要符合规范URL的标准,但是服务器对于规范URL的标准德解释是没有规定的,这样我们向服务器发送数据还存在编码不一致性的问题。通常浏览器会用两种编码方式发送URL到服务器,分别是UTF-8和ANSI(当前系统语言设置,在Windows系统中可以理解为当前代码页)。
3.1、直接在地址栏输入URL的情况
中文Windows环境下,假如直接在浏览器的地址栏输入URL:
http://www.charset.cn/中国.html?kw=中国
- IE浏览器特性
|
| PATH部分 | 参数部分 |
| UTF-8模式(默认) | %E4%B8%AD%E5%9B%BD.html | kw=中国 |
|
| UTF-8编码、urlencode | GBK编码、无urlencode |
| ANSI模式 | 中国.html | kw=中国 |
|
| GBK编码、无urlencode | GBK编码、无urlencode |
- 中文Windows环境下,IE中默认发送的URL的PATH部分是UTF-8编码,参数部分是GBK编码。IE的设置选项中有一项是“总是以 UTF-8 发送URL”可以改变发送URL的编码为ANSI。
- FireFox浏览器特性
|
| PATH部分 | 参数部分 |
| UTF-8模式 | %E4%B8%AD%E5%9B%BD.html | kw=%E4%B8%AD%E5%9B%BD |
|
| UTF-8编码、urlencode | UTF-8编码、urlencode |
| ANSI模式(默认) | %D6%D0%B9%FA.html | kw=%D6%D0%B9%FA |
|
| GBK编码、urlencode | GBK编码、urlencode |
- 中文Windows环境下FireFox中默认发送的URL的PATH和参数都是GBK编码,在FireFox地址栏输入“about:config”,找到选项“network.standard-url.encode-utf8”,即可改变发送URL的编码方式。
- Opera浏览器特性
|
| PATH部分 | 参数部分 |
| UTF-8模式(默认) | %E4%B8%AD%E5%9B%BD.html | kw=%E4%B8%AD%E5%9B%BD |
|
| UTF-8编码、urlencode | UTF-8编码、urlencode |
3.2、来自网页中的链接
在不同的浏览器中打开不同编码的网页中的链接,特性也不相同。在不改变浏览器默认选项情况下访问不同编码的网页中以下链接:
http://www.charset.cn/中国.html?kw=中国
- IE浏览器特性
|
| PATH部分 | 参数部分 |
| UTF-8网页 | %E4%B8%AD%E5%9B%BD.html | kw=中国 |
|
| UTF-8编码、urlencode | UTF-8编码、无urlencode |
| GBK网页 | %E4%B8%AD%E5%9B%BD.html | kw=中国 |
|
| UTF-8编码、urlencode | GBK编码、无urlencode |
- FireFox浏览器特性
|
| PATH部分 | 参数部分 |
| UTF-8网页 | %E4%B8%AD%E5%9B%BD.html | kw=%E4%B8%AD%E5%9B%BD |
|
| UTF-8编码、urlencode | UTF-8编码、urlencode |
| GBK网页 | %D6%D0%B9%FA.html | kw=%D6%D0%B9%FA |
|
| GBK编码、urlencode | GBK编码、urlencode |
对此,我们需要在组件中实现URL编码。
