
As a reader --> TabDDPM: Modelling Tabular Data with Diffusion Models
- 📌论文分类3:
TabDDPM——一个扩散模型,它可以普遍应用于任何表格数据集并处理任何特征类型。https://github.com/yandex-research/tab-ddpm- 论文名称 TabDDPM: Modelling Tabular Data with Diffusion Models
- 作者 Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, Artem Babenko
- 期刊名称 International Conference on Machine Learning. PMLR, 2023: 17564-17579.
- 简要摘要
去噪扩散概率模型正在成为许多重要数据模态的主要生成建模范式。作为计算机视觉社区中最流行的模型,扩散模型最近在其他领域得到了一些关注,包括语音、自然语言处理和类图数据。这项工作研究扩散模型的框架是否有利于一般的表格问题,其中数据点通常由异构特征的向量表示。表格数据固有的异质性使得精确建模非常具有挑战性,因为单个特征可能具有完全不同的性质,即有些特征可能是连续的,有些特征可能是离散的。
为了处理这样的数据类型,本文引入了TabDDPM——一个扩散模型,它可以普遍应用于任何表格数据集并处理任何特征类型。在广泛的基准上对TabDDPM进行了广泛的评估,并证明其优于现有的GAN/VAE替代品,这与扩散模型在其他领域的优势是一致的。
- ✏️论文内容
- 【内容1】
- 💡Introduction
- 去噪扩散概率模型(DDPM) 最近在生成建模社区中成为一个非常有研究兴趣的对象,因为它们在个体样本的真实性和多样性方面往往优于其他方法。DDPM最令人印象深刻的成功是在自然图像领域,扩散模型的优势在各种应用被成功利用,比如着色、图片修复、分割、超分辨率、语义编辑,等等。除了计算机视觉之外,DDPM框架还在其他领域进行了研究,例如NLP、波形信号处理、分子图、时间序列,……,这证明了扩散模型在广泛问题中的普遍性。
- 本工作旨在研究DDPM的普遍性是否可以扩展到一般表格问题的情况,这些问题在各种工业应用中无处不在,包括由一组异构特征描述的数据。对于许多此类应用,由于现代隐私法规(如GDPR)禁止发布真实用户数据,而生成模型生成的合成数据可以共享,因此对高质量生成模型的需求尤为迫切。然而,由于单个特征的异质性和典型表格数据集的相对较小的规模,训练高质量的表格数据模型可能比计算机视觉或NLP更具挑战性。
- 本文表明,尽管存在这两种复杂性,但扩散模型可以成功地近似表格数据的典型分布,从而在大多数基准测试中获得最先进的性能。更详细地说,这项工作的主要贡献如下:
- 1. 介绍TabDDPM——一个简单的用于表格问题的DDPM设计,它可以应用于任何表格任务,并处理混合数据类型,包括数值和分类特征。
- 2. 证明了TabDDPM优于为表格数据设计的替代方法,包括基于GAN和基于VAE的方法,并在几个数据集上说明了这种优势的来源。
- 3. 观察到基于浅插值的方法,例如SMOTE (Chawla等人,2002),产生了令人惊讶的有效合成数据,提供了具有竞争力的高机器学习效率。结果表明,与SMOTE相比,当使用合成数据代替无法共享的真实用户数据时,TabDDPM的数据更适合涉及隐私的场景。
- 1. 介绍TabDDPM——一个简单的用于表格问题的DDPM设计,它可以应用于任何表格任务,并处理混合数据类型,包括数值和分类特征。
- 💡Introduction
- 【内容2】
- 💡Related Work
- Diffusion models
一种生成建模的范例,旨在通过马尔可夫链的端点近似目标分布,它从给定的参数分布开始,通常是标准高斯分布。每个马尔可夫步骤都是由一个深度神经网络执行的,该网络有效地学习用已知的高斯核反转扩散过程。Ho等人证明了扩散模型和分数匹配的等价性,表明它们是通过迭代去噪过程将简单已知分布逐渐转换为目标分布的两种不同视角。近期的几项工作开发了更强大的模型架构以及不同的高级学习协议,这导致DDPM在计算机视觉领域的生成质量和多样性方面优于GAN。这项工作证明了人们也可以成功地将扩散模型用于表格问题。
- Generative models for tabular problems
目前是机器学习社区的一个活跃的研究方向,因为许多表格任务对高质量的合成数据有很大的需求。首先,表格数据集通常在大小上是有限的,不像在视觉或NLP问题中,在互联网上有大量的“额外”数据。其次,适当的合成数据集不包含实际的用户数据。
因此,它们不受类似GDPR的监管,可以在不违反匿名性的情况下公开共享。最近的工作已经开发了大量的模型,包括表格VAEs,和基于GAN的方法。通过对大量公共基准进行广泛的评估,TabDDPM优于现有的替代方案,而且通常有很大的优势。
- “Shallow” synthetics generation
与非结构化图像或自然文本不同,表格数据通常是结构化的,即单个特征通常是可解释的,并且不清楚它们的建模是否需要几层“深度”架构。因此,简单的插值技术,如SMOTE (Chawla等人,2002)(最初是为了解决类不平衡而提出的)可以作为简单而强大的解决方案,如(Camino等人,2020)所示,SMOTE在小类过采样方面优于表格GAN。在本文实验中,从隐私保护的角度证明了TabDDPM合成数据比用插值技术生产的合成数据的优势。
- Diffusion models
- 💡Related Work
- 【内容3】
- 💡Background
- Diffusion models
- Gaussian diffusion models
- Multinomial diffusion models
- Diffusion models
- 💡Background
- 【内容4】
- 💡TabDDPM
![]()
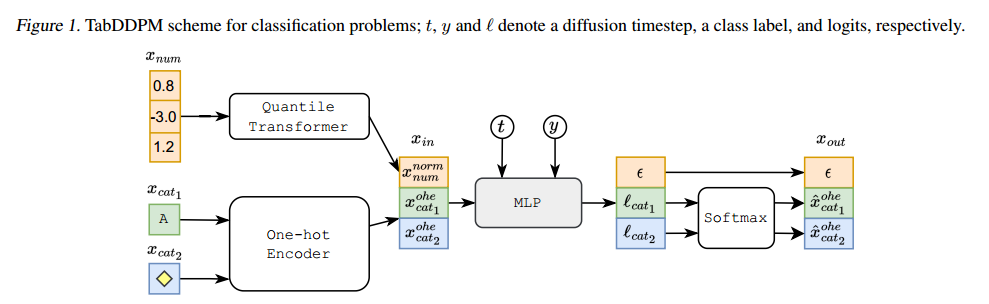
描述TabDDPM的设计以及影响模型有效性的主要超参数。- TabDDPM采用多项扩散法对分类和二值特征进行建模,采用高斯扩散法对数值特征进行建模。更详细地说,对于表格数据x:
![]()
- 对于预处理,使用scikit-learn库中的高斯分位数变换,每个分类特征由一个单独的前向扩散过程处理,即所有特征的噪声分量是独立采样的。TabDDPM中的反向扩散步骤是由一个多层神经网络建模的,该神经网络的输出维度与x0相同,其中前N_num个元素是高斯扩散的ε的预测,其余的是多项式扩散的x_cati^ohe的预测。
- 分类问题的TabDDPM模型如图1所示。模型是通过最小化高斯扩散项的均方误差总和,和每个多项式扩散项的KL散度训练的。多项扩散的总损失另外除以分类特征的数目。
![]()
- 对于分类数据集,使用类条件模型,也就是说,pθ(xt−1|xt, y)是习得的;对于回归数据集,将目标值作为附加的数值特征,并学习联合分布。
- 为了对反向过程建模,使用了一个简单的MLP架构,改编自(gorishny等人,2021):
![]()
- 如(Nichol, 2021; Dhariwal & Nichol, 2021)所述,表格输入x_in,时间步长t和类标签y的处理如下:
![]()
- 其中SinTimeEmb指正弦时间嵌入,如(Nichol, 2021;Dhariwal & Nichol, 2021)所述,维度为128。方程5中的所有线性层都有一个固定的投影维度128。
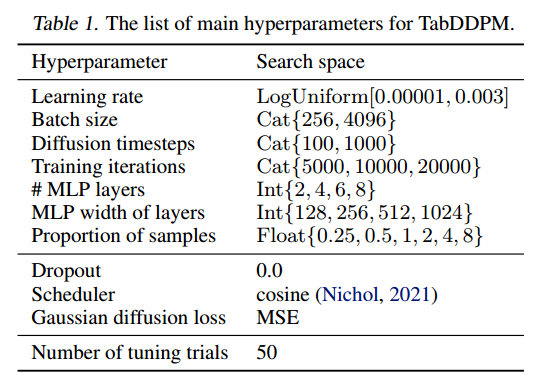
- TabDDPM中的超参数是必不可少的,因为在实验中观察到它们对模型有效性有很强的影响。表1列出了主要的超参数以及每个超参数的搜索空间,建议使用这些超参数。实验部分详细描述了微调过程。
![]()
- TabDDPM采用多项扩散法对分类和二值特征进行建模,采用高斯扩散法对数值特征进行建模。更详细地说,对于表格数据x:
- 💡TabDDPM
- 【内容5】
- 💡Experiments
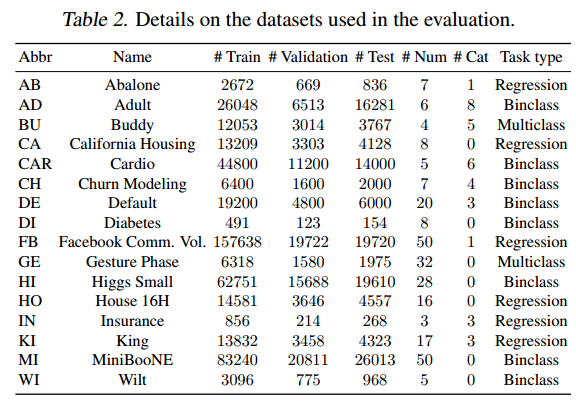
- Datasets
![]()
- Baselines
- TVAE (Xu et al ., 2019)——用于表格数据生成的最先进的变分自动编码器。据我们所知,目前还没有一种替代的类似于VAE的模型能够超越TVAE并且拥有开源代码。
- CTGAN(Xu et al., 2019)——可以说是最流行和最知名的基于GAN的合成数据生成模型。
- CTABGAN(Zhao et al., 2021)——最近一种基于GAN的模型,在各种基准测试中表现优于现有的表格式GAN。这种方法不能处理回归任务。
- CTABGAN+(Zhao et al., 2022)——CTABGAN模型的扩展,发表在最近的预印本中。我们不知道还是否有CTABGAN+之后提出的基于GAN的表格数据模型,并有一个公开的源代码。
- SMOTE(Chawla et al., 2002)——一种基于“浅”插值的方法,它“生成”一个合成点,作为真实数据点和数据集中第k个最近邻居的凸组合。该方法最初是针对小类过采样提出的。这里将其推广到合成数据生成,作为简单的完整性检查,即,通过插入来自同一类的两个样本来“生成”新的合成样本。对于回归问题,通过目标变量的中位数将数据分成两类。
- TVAE (Xu et al ., 2019)——用于表格数据生成的最先进的变分自动编码器。据我们所知,目前还没有一种替代的类似于VAE的模型能够超越TVAE并且拥有开源代码。
- Evaluation measure
- 主要评估指标是机器学习(ML)的效率(或效用)。更详细地说,机器学习效率量化了在合成数据上训练并在真实测试集上评估的分类或回归模型的性能。直观地说,在高质量合成材料上训练的模型应该比在真实数据上训练的模型更有竞争力(甚至更好)。本文使用两种评估协议来计算机器学习效率。
- 在第一种方案中,计算了一组不同ML模型(逻辑回归、决策树等)的平均效率。在第二个方案中,仅使用CatBoost模型评估机器学习效率,该模型可以说是领先的GBDT实现,在表格任务上提供最先进的性能。【第5.2节的实验中表明,使用第二种协议是至关重要的,而第一种协议往往会产生误导。】
- 主要评估指标是机器学习(ML)的效率(或效用)。更详细地说,机器学习效率量化了在合成数据上训练并在真实测试集上评估的分类或回归模型的性能。直观地说,在高质量合成材料上训练的模型应该比在真实数据上训练的模型更有竞争力(甚至更好)。本文使用两种评估协议来计算机器学习效率。
- Tuning process
- 为了调整TabDDPM和基线的超参数,使用Optuna库。调优过程由在保留验证数据集上生成的合成数据的ML效率值指导(分数在五个不同的采样种子上平均)。表1报告了TabDDPM所有超参数的搜索空间。此外,证明使用CatBoost指南调优超参数不会引入任何类型的“CatBoost偏置”,而Catboost-微调的TabDDPM生产的合成数据也优于其他模型,如MLP。
- 为了调整TabDDPM和基线的超参数,使用Optuna库。调优过程由在保留验证数据集上生成的合成数据的ML效率值指导(分数在五个不同的采样种子上平均)。表1报告了TabDDPM所有超参数的搜索空间。此外,证明使用CatBoost指南调优超参数不会引入任何类型的“CatBoost偏置”,而Catboost-微调的TabDDPM生产的合成数据也优于其他模型,如MLP。
- 1.Qualitative comparison
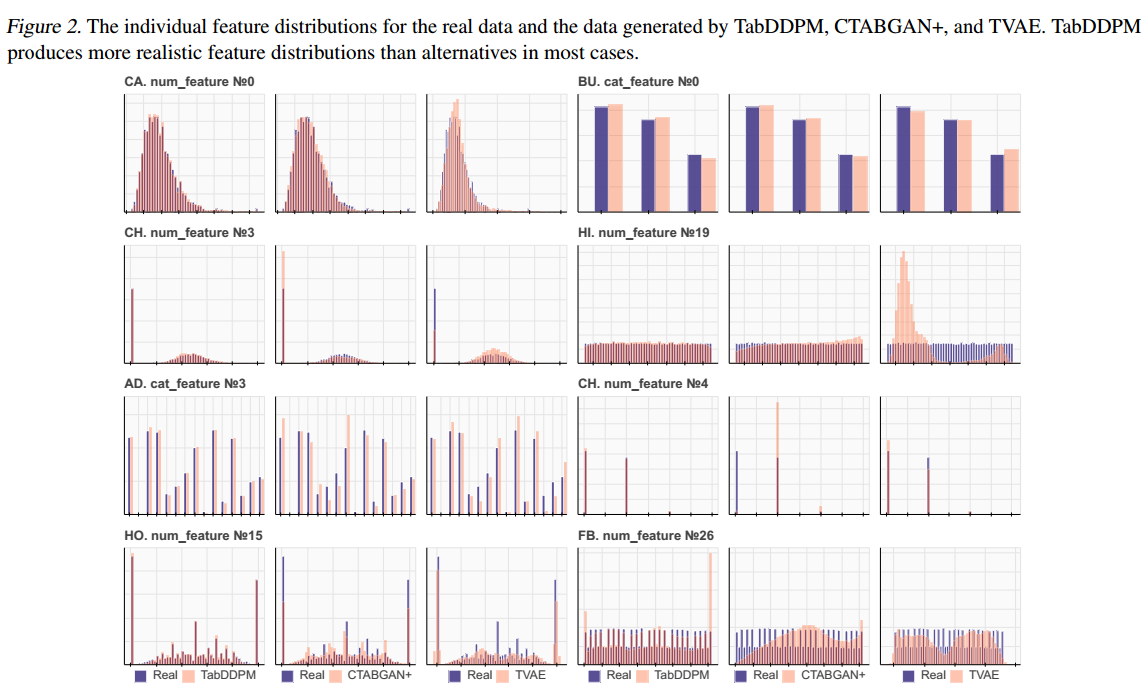
- 定性研究TabDDPM与TVAE、CTABGAN+基线相比,对个体和联合特征分布的建模能力。特别是,对于每个数据集,从TabDDPM、 TVAE和CTABGAN+中生成与特定数据集中的真实训练集相同大小的合成数据集。对于分类数据集,每个类别根据其在真实数据集中的比例进行采样。在图2中可视化了真实数据和合成数据的典型单个特征分布。为了完整起见,给出了不同类型和分布的特征。
![]()
- 在大多数情况下,与TVAE和CTABGAN+相比,TabDDPM产生的特征分布更真实。对于(1)均匀分布的数值特征,(2)具有高基数的分类特征,以及(3)结合连续和离散分布的混合类型特征,优势更加明显。
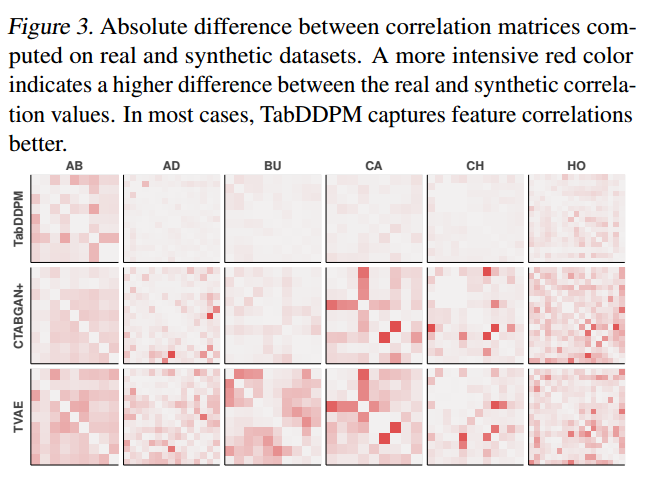
- 此外,还可视化了对不同数据集的真实数据和合成数据计算的关联矩阵之间的差异,参见图3。
![]()
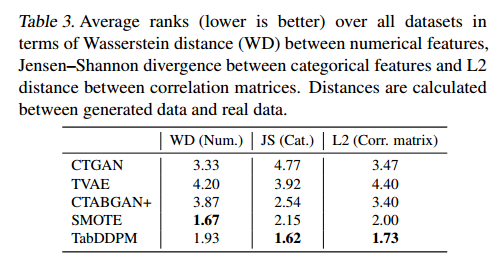
- 为了计算相关矩阵,使用皮尔逊相关系数来表示数值相关性,使用相关比率来表示分类数值情况,使用Theil’s U统计量来表示分类特征。与CTABGAN+和TVAE相比,TabDDPM生成的合成数据集具有更现实的两两相关性。这些实例表明,TabDDPM模型比其他模型更灵活,并产生更好的合成数据。还遵循(Zhao et al ., 2021)并测量数值特征之间的Wasserstein距离和分类特征之间的Jensen-Shannon散度,报告了相关矩阵之间的L2距离。结果在表3中显示为所有数据集的平均排名(越低越好)。排名越低,WD、JS散度和L2距离越低。
![]()
- 定性研究TabDDPM与TVAE、CTABGAN+基线相比,对个体和联合特征分布的建模能力。特别是,对于每个数据集,从TabDDPM、 TVAE和CTABGAN+中生成与特定数据集中的真实训练集相同大小的合成数据集。对于分类数据集,每个类别根据其在真实数据集中的比例进行采样。在图2中可视化了真实数据和合成数据的典型单个特征分布。为了完整起见,给出了不同类型和分布的特征。
- 2.Machine Learning efficiency
- 将TabDDPM与其他生成模型在机器学习效率方面进行比较。从每个生成模型中,按表1的比例采样一个具有真实训练集大小的合成数据集。然后使用这些合成数据来训练分类/回归模型,然后使用真实的测试集对其进行评估。实验中,分类性能用F1分数来评价,回归性能用R2分数来评价。使用两种方案:
- 1.计算一组不同ML模型的平均ML效率,该集合包括决策树、随机森林、逻辑回归(或Ridge回归)和来自scikit-learn库的MLP模型。
- 2.根据当前最先进的表格数据模型计算机器学习效率。具体来说,考虑了CatBoost和(gorishny等人,2021)的MLP架构进行评估。CatBoost和MLP超参数使用来自(gorishny等人,2021)的搜索空间在每个数据集上进行彻底调优。这种评估协议更可靠地展示了合成数据的实用价值,因为在大多数实际场景中,从业者对使用弱和次优分类器/回归器不感兴趣。
- 1.计算一组不同ML模型的平均ML效率,该集合包括决策树、随机森林、逻辑回归(或Ridge回归)和来自scikit-learn库的MLP模型。
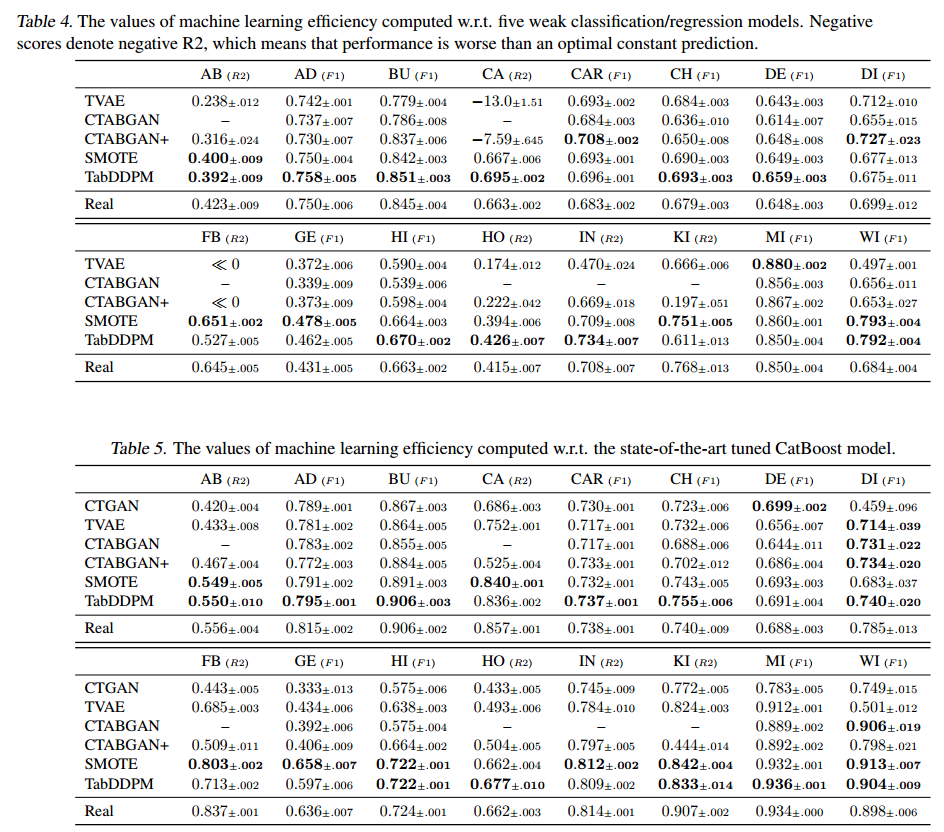
- 两种方案计算的ML效率值如表4、5所示。为了计算每个值,对合成生成的五个随机种子的结果进行平均;对于每个生成的数据集,对训练分类器/回归器的十个随机种子进行平均。
![]()
- 在这两种评估方案中,TabDDPM在大多数数据集上都明显优于TVAE和CTABGAN+,这突出了表格数据的扩散模型的优势,并在先前的工作中证明了其他领域。
- 基于插值的SMOTE方法表现出与TabDDPM相竞争的性能,并且通常显著优于GAN/VAE方法。
- 有趣的是,大多数关于表格数据生成模型的先前工作都没有与SMOTE进行比较,而SMOTE似乎是一个简单的基线,这是具有挑战性的。
- 虽然许多先前的工作使用第一种评估方案来计算机器学习效率,但本文认为第二种(使用最先进的模型)更合适。表4、5显示,第一种方案的分类/回归性能的绝对值要低得多,即在考虑的基准测试中,弱分类器/回归器实质上不如CatBoost。因此,人们很难使用这些次优模型来代替CatBoost,并且它们的性能值对从业者来说是没有信息的。此外,在第一种方案中,对合成数据的训练往往比对真实数据的训练更有利。这给人一种印象,即生成模型产生的数据比真实数据更有价值。然而,在大多数实际场景中,当使用调优的ML模型时,情况并非如此。
- 在这两种评估方案中,TabDDPM在大多数数据集上都明显优于TVAE和CTABGAN+,这突出了表格数据的扩散模型的优势,并在先前的工作中证明了其他领域。
- 总的来说,TabDDPM提供了最先进的生成性能,可以用作高质量合成数据的来源。有趣的是,就机器学习效率而言,一个简单的“浅”SMOTE方法与TabDDPM竞争,这就提出了一个问题,即是否需要复杂的深度生成模型。下面对这个问题给出一个肯定的答案。
- 将TabDDPM与其他生成模型在机器学习效率方面进行比较。从每个生成模型中,按表1的比例采样一个具有真实训练集大小的合成数据集。然后使用这些合成数据来训练分类/回归模型,然后使用真实的测试集对其进行评估。实验中,分类性能用F1分数来评价,回归性能用R2分数来评价。使用两种方案:
- 3. Privacy
- 研究TabDDPM在涉及隐私的设置中,例如,在不泄露个人或敏感信息的情况下共享数据。在这些设置中,人们对不显示原始数据集记录的高质量合成数据感兴趣。
- 用与最近记录的平均距离来衡量生成数据的隐私性。具体来说,对于每个合成样本,得到到真实记录的最小L2距离。平均DCR在所有生成的样本上取这些距离的平均值。低DCR值表明合成样本基本上模拟了一些真实的数据点,并且可能违反隐私要求。较高的DCR值表示生成模型可以生成“新”记录,而不仅仅是真实数据的近副本。请注意,分布外数据,例如随机噪声,也将提供高DCR。因此,DCR需要与ML效率一起考虑。
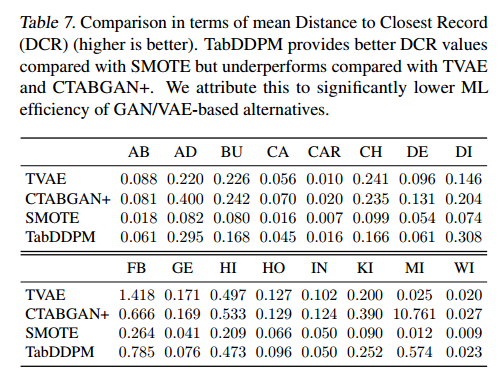
- 表7给出了TabDDPM、SMOTE、CTABGAN+和TVAE的DCR值。观察到TabDDPM比SMOTE更私密,比GAN/VAE替代品更不私密,将此归因于基于GAN/VAE基线的ML效用显着降低。
![]()
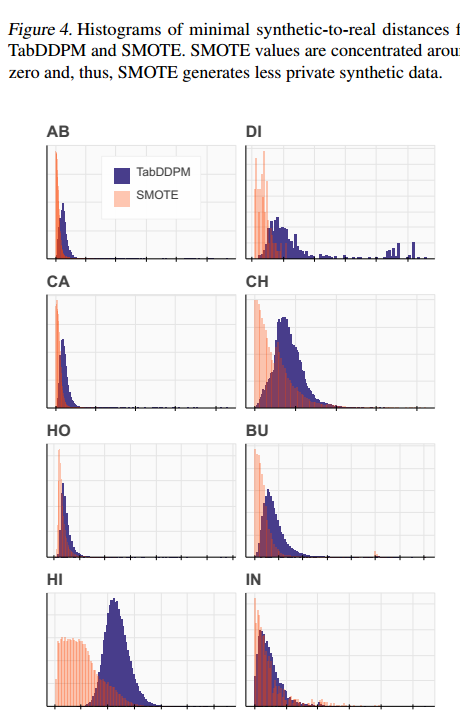
- 由于SMOTE计算的是真实记录的凸组合,原始的DCR度量可能会降低SMOTE的隐私性。为了解决这个问题,使用真实数据在每个数据集上预训练一个MLP模型。然后,使用该模型从合成数据中提取特征,并在预训练模型的潜在空间中测量DCR。表14给出了MLP特征的平均DCR值。结果与表7基本一致,并没有改变前面结论。此外,本文还可视化了图4中最小合成距离的直方图。对于SMOTE,大多数距离值都集中在零附近,而TabDDPM样本离实际数据点明显更远。
![]()
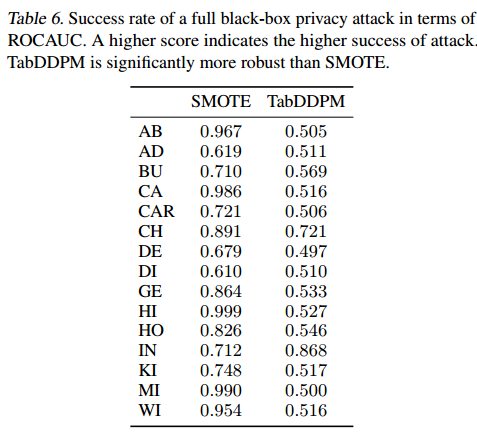
- 下面衡量一个完整黑箱隐私攻击的成功率(见表6)。
![]()
- 攻击的目的是推断一条记录是否属于其原始训练数据。结果表明:TabDDPM比SMOTE更能抵抗这种完整的黑盒攻击。所有这些实验都证实,TabDDPM在涉及隐私的场景中显著优于SMOTE,并且仍然提供最先进的机器学习效率。
- 研究TabDDPM在涉及隐私的设置中,例如,在不泄露个人或敏感信息的情况下共享数据。在这些设置中,人们对不显示原始数据集记录的高质量合成数据感兴趣。
- 💡Experiments
- 【内容6】
- 💡Limitations and discussion
- 本文所提出的方法并没有假装是一个提供高隐私和高ML实用性的一体化解决方案。实验表明,TabDDPM比“浅”SMOTE更隐私,但TabDDPM的数据是否能满足现实世界中涉及隐私的应用,没有给出明确的答案。因此,DDPM生成的数据的隐私问题需要进一步研究。此外,本文中使用的DCR并不是一种最终的隐私措施,也没有涵盖一些关键的用例。例如,记录之间的L2距离没有考虑单个特征的重要性,如果某些敏感特征重合,则无法检测泄漏。
- 此外,在本文的工作中,使用多项扩散来处理分类特征。然而,也存在其他方法,例如(Chen et al ., 2022; Campbell et al, 2022; Zheng & Charoenphakdee, 2022)。这些技术中的每一种都适用于TabDDPM,并且可能是一个有趣的研究方向。对于数值特征,TabDDPM的可能扩展可以从(Nazabal et al, 2020)中得到启发,该特征区分了不同类型的数值变量,即实值、正实值或序数。
- 本文所提出的方法并没有假装是一个提供高隐私和高ML实用性的一体化解决方案。实验表明,TabDDPM比“浅”SMOTE更隐私,但TabDDPM的数据是否能满足现实世界中涉及隐私的应用,没有给出明确的答案。因此,DDPM生成的数据的隐私问题需要进一步研究。此外,本文中使用的DCR并不是一种最终的隐私措施,也没有涵盖一些关键的用例。例如,记录之间的L2距离没有考虑单个特征的重要性,如果某些敏感特征重合,则无法检测泄漏。
- 💡Limitations and discussion
- 【内容1】
- 总结
- 本文探讨了扩散建模框架在表格数据领域的应用前景。特别地,描述了可以处理由数值特征和分类特征组成的混合数据类型的DDPM设计。对于大多数考虑的基准,与基于GAN/VAE的竞争对手相比,TabDDPM生成的合成数据始终具有更高的质量。有趣的是,像SMOTE这样的浅插值技术已经证明了有竞争力的ML实用程序,需要被视为简单而有效的基线。然而,在必须确保数据隐私的设置中,TabDDPM优于SMOTE。
- 本文探讨了扩散建模框架在表格数据领域的应用前景。特别地,描述了可以处理由数值特征和分类特征组成的混合数据类型的DDPM设计。对于大多数考虑的基准,与基于GAN/VAE的竞争对手相比,TabDDPM生成的合成数据始终具有更高的质量。有趣的是,像SMOTE这样的浅插值技术已经证明了有竞争力的ML实用程序,需要被视为简单而有效的基线。然而,在必须确保数据隐私的设置中,TabDDPM优于SMOTE。
- 附录
- A. MLP evaluation and tuning
- B. Additional results
- C. Additional visualizations
- D. Distance to Closest Record using pretrained MLP features
- E. Hyperparameters Search Spaces
- F. Datasets
- G. Environment and Runtime
- A. MLP evaluation and tuning
- 论文名称 TabDDPM: Modelling Tabular Data with Diffusion Models


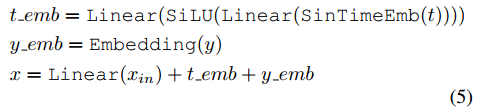
To see I can not see,
to know I do not know.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号