
HIT2019秋计算机网络->传输层一些总结
1.TCP采用端到端的拥塞控制,而不是网络辅助的拥塞控制,原因是IP层不向端系统提供显式的网络拥塞反馈。
2.TCP采用的方法:让每一个sender根据感知到的网络拥塞程度限制其能向连接发送流量的速率。
3.关注的问题:
1)一个TCPsender如何限制它向其连接发送流量的速率?
2)一个TCPsender如何感知从它到目的地之间的路径上存在拥塞?
3)当sender感知到端到端的阻塞时,采用何种算法来改变其发送速率?
4.TCP如何进行流量控制?可能存在什么问题?
糊涂窗口综合症:如果发送端为产生数据很慢的应用程序服务,例如,一次产生一个字节。这个应用程序一次将一个字节的数据写入发送端的TCP的缓存。如果发送端的TCP没有特定的指令,它就产生只包括一个字节数据的报文段。结果有很多41字节的IP数据报就在互连网中传来传去。
如果接收端为消耗数据很慢的应用程序服务,例如,一次消耗一个字节。假定发送应用程序产生了1000字节的数据块,但接收应用程序每次只吸收1字节的数据。再假定接收端的TCP的输入缓存为4000字节。发送端先发送第一个4000字节的数据。接收端将它存储在其缓存中。现在缓存满了。它通知窗口大小为零,这表示发送端必须停止发送数据。接收应用程序从接收端的TCP的输入缓存中读取第一个字节的数据。在入缓存中现在有了1字节的空间。接收端的TCP宣布其窗口大小为1字节,这表示正渴望等待发送数据的发送端的TCP会把这个宣布当作一个好消息,并发送只包括一个字节数据的报文段。这样的过程一直继续下去。一个字节的数据被消耗掉,然后发送只包含一个字节数据的报文段。
(1) 发送端引起:Nagle算法->报文段一定长度再发送
i) 发送端的TCP将它从发送应用程序收到的第一块数据发送出去,哪怕只有一个字节。
ii) 在发送第一个报文段(即报文段1)以后,发送端的TCP就在输出缓存中积累数据,并等待:或者接收端的TCP发送出一个确认,或者数据已积累到可以装成一个最大的报文段。在这个时候,发送端的TCP就可以发送这个报文段。
iii) 对剩下的传输,重复步骤2。这就是:如果收到了对报文段x的确认,或数据已积累到可以装成一个最大的报文段,那么就发送下一个报文段(x + 1)。
Nagle算法的优点就是简单,并且它考虑到应用程序产生数据的速率,以及网络运输数据的速率。若应用程序比网络更快,则报文段就更大(最大报文段)。若应用程序比网络慢,则报文段就较小(小于最大报文段)。
(2) 接收端引起:Clark解决方法->0窗口确认 -> 只要有数据到达就发送确认,但宣布的窗口大小为零,直到或者缓存空间已能放入具有最大长度的报文段,或者缓存空间的一半已经空了。
延迟确认->阻止发送窗口滑动 -> 当一个报文段到达时并不立即发送确认。接收端在确认收到的报文段之前一直等待,直到入缓存有足够的空间为止。延迟的确认防止了发送端的TCP滑动其窗口。当发送端的TCP发送完其数据后,它就停下来了。
迟延的确认还有另一个优点:它减少了通信量。接收端不需要确认每一个报文段。它也有一个缺点,就是迟延的确认有可能迫使发送端重传其未被确认的报文段。
可以用协议来*衡这个优点和缺点,例如现在定义了确认的延迟不能超过500毫秒。
5.TCP的公*性:
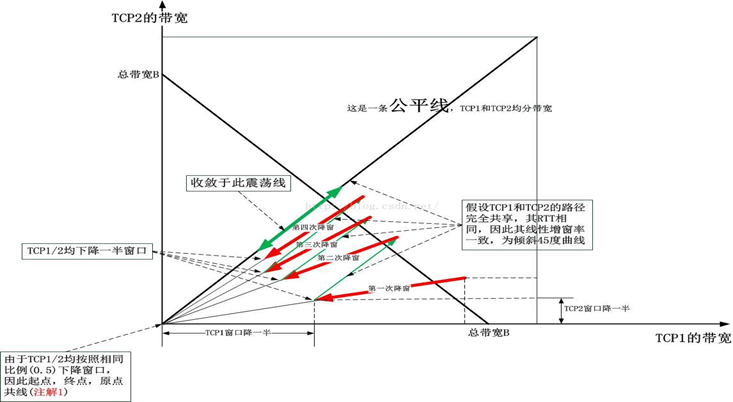
在公*线的下方,红色的减窗线的斜率是恒小于公*线(45°角)的斜率的,两个连接的每一次降窗,其降窗线的斜率都会原来越接*公*线的斜率,即收敛到公*,最终,它将在绿色粗线上震荡,保持公*(利用率不高)。
此时,TCP1和TCP2等比例降窗,图中均为0.5[但不一定要0.5]。只要保持等比例,收敛就会永远成立,不同的仅仅是最终收敛时绿色粗线的长度和范围。按照最初的Reno TCP,保持0.5的降窗比例较为合理;但还需考虑现实中各种复杂的实际情况。
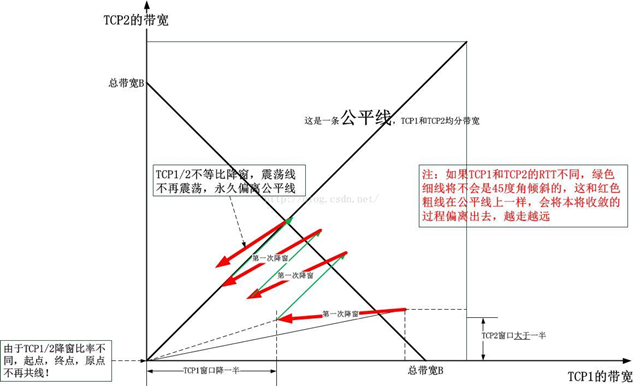
可以看到,竞争者中降窗比例最小的,最终会抢用所有带宽。如图,即会将所有的竞争者向左上角挤,最终归零。
那么,如果我们想要使自己的TCP连接具有侵略性,只要降低降窗比例即可?错。上述讨论过程中,规定的条件是所有TCP连接的RTT相同。如果RTT相同,例如它们的源和目的地点都相同,那么大概率为合作关系,而非竞争关系。
而实际的运行中,RTT的波动也会非常大,这也是一个有意义的信号,它让端系统看到了中间路由器交换机的排队行为,因此会出现RTT所谓的“噪点”。现实中的TCP几乎完全改进了Reno的指导,除Reno几乎没有什么拥塞算法在发现丢包时,把ssthresh降为当前窗口的一半。
6.
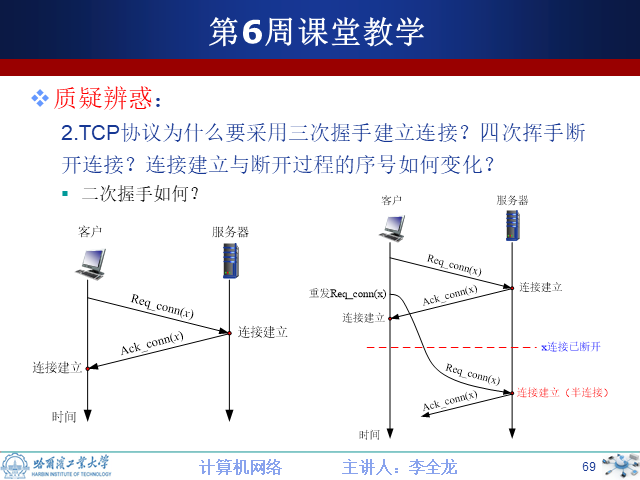
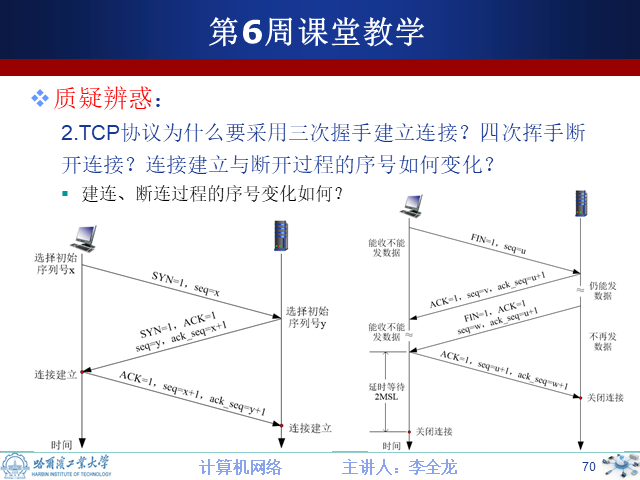
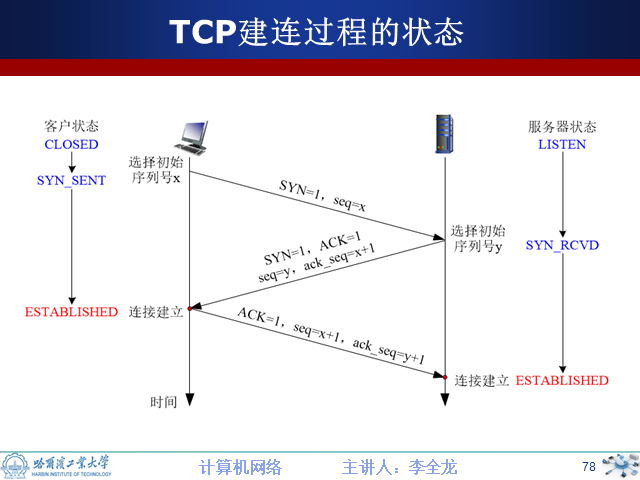
7.
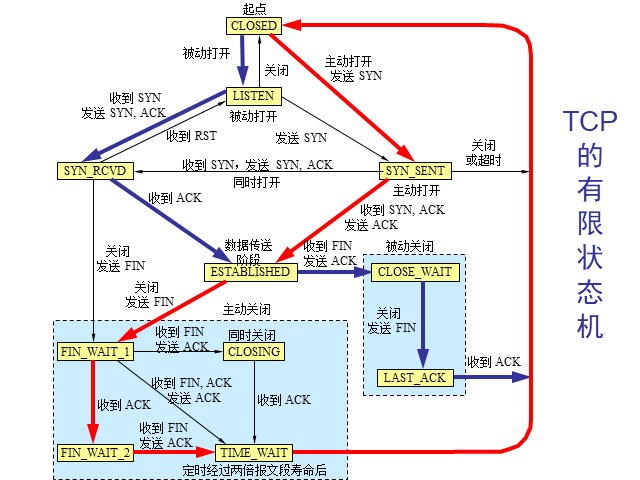
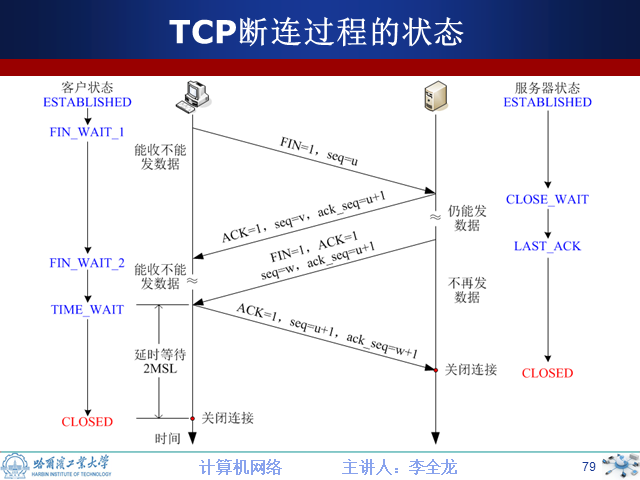
8.
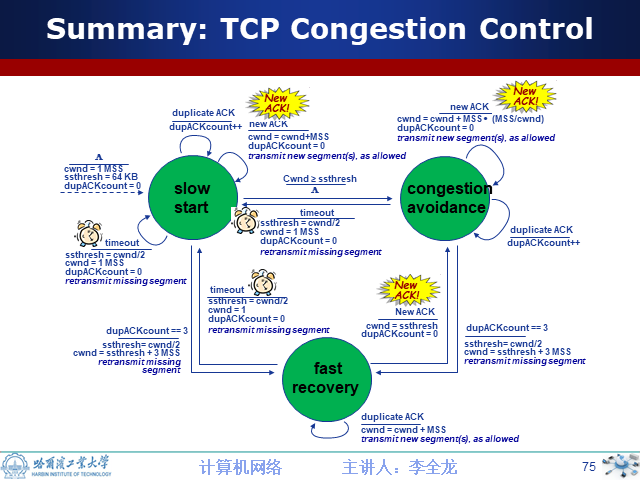
9.快速恢复算法
TCP Reno这个算法定义在RFC5681。快速重传和快速恢复算法一般同时使用。快速恢复算法是认为,你还有3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈,并不需要重新回到慢启动进行,这样可能降低效率。所以协议栈会做如下工作
1) cwnd = cwnd/2
2) sshthresh = cwnd
然后启动快速恢复算法:
1) 设置cwnd = ssthresh+ACK个数*MSS(一般情况下会是3个dup ACK)
2) 重传丢失的数据包(对于重传丢失的那个数据包,可以参考TCP-IP详解:SACK选项)
3) 如果只收到Dup ACK,那么cwnd = cwnd + 1, 并且在允许的条件下发送一个报文段
4) 如果收到新的ACK, 设置cwnd = ssthresh, 进入拥塞避免阶段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号