使用双卡/8卡3090微调llama2-70B/13B模型
写在前面
本篇博文将会教大家如何在消费级的设备(或者各种超级便宜的洋垃圾上)实现13B/70B等无法在单张消费级显卡上加载(但可以在一台机器上的多张卡上加载)的模型的微调。
由于绝大部分做实验,仅要求实现推理,或者在微调时没有资源上到全量/13B+级别的真·大模型的微调,没有涉及到将一个模型放在多张卡上的训练,这方面可供参考的材料极少(甚至英文的都极少),下面推荐几个可以查问题的参考(但也没有直接提供今天要的东西):
1. HuggingFace原版的PEFT教程,目前绝大部分的微调都基于PEFT上进行二次开发而得来,但这些二次开发的仓库不会告诉你很多参数为何要设置,这些要设置的参数大部分源自PEFT库中。
2. LLaMA-Factory仓库,这是对PEFT仓库的二次开发,可以很方便地实现预训练,各种PEFT微调和模型推理测试,支持LLaMA,ChatGLM等模型(特别是针对这些模型制作了开头和结尾等控制信息)。但该仓库并不直接支持将一个模型放在多个GPU上进行微调。
3. LLaMA-Factory仓库的Issue列表,截止目前(2023年12月10日),里面共有1697个issue,出锅了把出锅信息复制过来看,多半能找到解答。(比直接Google要好)
常见误区
关于Deepspeed实现多卡推理
网上的多个教程称你可以用Deepspeed框架来实现多卡的训练。我也照着复现,但是发现运行速度极慢,且非常容易爆内存(测试设备有507GB内存)。
经过分析,他们的设置,实际上仅实现了Data Parallel的运行,至于为啥能够Data Parallel实现70B模型在24G显存显卡上的运行,那是因为开了ZeRO3实现了将内存虚拟化为显存实现的,8卡3090实际上每个卡上跑了单独的一个70B模型,频繁换入换出显存不慢就怪了233333。
个人认为,港科广的测试模型微调速度的论文这里面就出现了这一重大失误,在Data Parallel的框架下微调70B级别的模型,导致3090对A100仅有2%的性能,如果测试时采用了Tensor/Pipeline Parallel,那么性能相差将不会这么悬殊(当然也要感谢这一篇文章,让我意识到了这个问题)
笔者在正式部署的时候,并没有采用deepspeed,而是直接基于最基础的PEFT框架实现。
一些结论
1. 笔者实现了在两张P40显卡上基于LoRA在FP16精度(无量化)下微调LLaMA2-13B模型。这是一个成本仅需3000元的硬件平台。(缺点:在Ampere架构以下的卡,不支持BF16,可能会炸精度)
2. 笔者实现了在8张3090显卡上,基于LoRA在FP16精度(无量化)下微调LLaMA2-70B模型(根据评估,应该还可以降低到6张卡的水平)
3. 目前暂时解决了使用Deepspeed会爆显存的问题,采用256GB内存的设备足够应付LLaMA2-70B模型的微调。
4. 目前尚未解决Pipeline Parallel导致的同时只有一个GPU在运行的效率低问题,考虑后续改为Bubble。
运行环境
硬件
GPU:8卡3090
CPU:AMD EPYC 7302 64核
RAM:507GB
基础软件
下方暂时仅列举最关键的几个基础软件,对于一般的包详见下方
OS:Ubuntu 20.04.5 LTS
Python:3.8.10
CUDA:release 11.8, V11.8.89
Python CUDA(这是Python中安装的CUDA相关库):2.0.0+cu118
这里面注意Python CUDA中的版本和CUDA之间的关系,如果不匹配可能会出锅。
Python包版本
本人基于经过细微修改的LLaMA-Factory执行多卡微调任务,包版本与该仓库的requirements.txt一致
但不确定是什么原因,用torch 2.0.0版本稳定性较高?
注意下包版本的问题,比如PEFT的最新版(0.7.0)就有bug,会出现下面的报错
ValueError: Attempting to unscale FP16 gradients.
微调环境适配
本人微调的是TigerBot 13B/70B系列模型,采用LLaMA2架构,但是Chat模式下的开头与一般的LLaMA不一样,所以首先要修改template.py(在src/llmtuner/data中),增加适配TigerBot格式的template
1 register_template( 2 name="tigerbot", 3 prefix=[ 4 "" 5 ], 6 prompt=[ 7 "\n\n### Instruction:\n {{query}} \n\n### Response:\n" 8 ], 9 system="", 10 sep=[] 11 )
为了支持将一个模型平均塞进多个GPU的显存中,我们需要修改模型读取的部分。
在src/llmtuner/model/loader.py中,在约第180行处,修改以下的位置
1 model = AutoModelForCausalLM.from_pretrained( 2 model_to_load, 3 config=config, 4 device_map = 'auto', 5 torch_dtype=model_args.compute_dtype, 6 low_cpu_mem_usage=(not is_deepspeed_zero3_enabled()), 7 **config_kwargs 8 )
增加上面这一行红色的代码,这是本博文最关键的一个步骤!!!!!!
实际上,在transformers中,无论读取模型到推理环节,还是读取模型到训练环境,都是采用.from_pretrained来实现的,训练时设置该部分,则可以让一个模型被平均在2张/多张卡上。
(不过,由于该仓库的特性,启用该仓库执行推理时记得注释掉这一行)
运行微调
这里执行微调时,采用的命令与单卡微调一致,不要用deepspeed!!!
1 python src/train_bash.py \ 2 --stage sft \ 3 --model_name_or_path /hy-tmp/tigerbot-70b-chat-v4-4k \ 4 --do_train True \ 5 --finetuning_type lora \ 6 --template tigerbot \ 7 --dataset_dir data \ 8 --dataset self_cognition_golden \ 9 --cutoff_len 1024 \ 10 --learning_rate 1e-4 \ 11 --num_train_epochs 8.0 \ 12 --per_device_train_batch_size 8 \ 13 --gradient_accumulation_steps 1 \ 14 --lr_scheduler_type cosine \ 15 --logging_steps 1 \ 16 --save_steps 100 \ 17 --lora_rank 256 \ 18 --lora_dropout 0.1 \ 19 --lora_target q_proj,v_proj \ 20 --output_dir saves \ 21 --fp16 True \ 22 --plot_loss True \ 23 --overwrite_output_dir
与LLaMA-Factory官方微调脚本中不一样地方主要有下面几个:
1. template这里改为了刚刚设置的TigerBot格式
2. 在一些老卡上(比如超级便宜的P40显卡),他们是Ampere架构前的显卡,不支持bf16,所以不要开这个。
3. 虽然是多卡微调,但是在这个运行脚本中看不到对应的设置。
注意:需要额外上传self_cognition_golden这个数据集,以及修改dataset_info.json这个文件。
然后就可以微调了
一些奇技淫巧
由于VLLM框架,暂时不适配lora,要微调只适合用freeze算法实现。
然而,想要采用freeze算法,微调某一层的显存消耗极大,在初始布置模型的时候,我们应该将每一层的分布不均匀化,给需要微调的层所在的显卡释放尽可能多的空间
举个例子:一个70B模型有80层,2卡A100-80G环境下每个卡放40层,但是每调一个层就需要+10G的显存放优化器等部分。
于是,我们可以调节一下,在第0张卡放47层,第1张卡放33层,这样可以让全量微调的层数+1.
具体来说,我们可以通过手动设置上文中的device_map来实现
1 maps = { 2 "lm_head": 0, 3 "model.embed_tokens": 0, 4 "model.layers.0": 0, 5 "model.layers.1": 0, 6 "model.layers.2": 0, 7 "model.layers.3": 0, 8 "model.layers.4": 0, 9 "model.layers.5": 0, 10 "model.layers.6": 0, 11 "model.layers.7": 0, 12 "model.layers.8": 0, 13 "model.layers.9": 0, 14 "model.layers.10": 0, 15 "model.layers.11": 0, 16 "model.layers.12": 0, 17 "model.layers.13": 0, 18 "model.layers.14": 0, 19 "model.layers.15": 0, 20 "model.layers.16": 0, 21 "model.layers.17": 0, 22 "model.layers.18": 0, 23 "model.layers.19": 0, 24 "model.layers.20": 0, 25 "model.layers.21": 0, 26 "model.layers.22": 0, 27 "model.layers.23": 0, 28 "model.layers.24": 0, 29 "model.layers.25": 0, 30 "model.layers.26": 0, 31 "model.layers.27": 0, 32 "model.layers.28": 0, 33 "model.layers.29": 0, 34 "model.layers.30": 0, 35 "model.layers.31": 0, 36 "model.layers.32": 0, 37 "model.layers.33": 0, 38 "model.layers.34": 0, 39 "model.layers.35": 0, 40 "model.layers.36": 0, 41 "model.layers.37": 0, 42 "model.layers.38": 0, 43 "model.layers.39": 0, 44 "model.layers.40": 0, 45 "model.layers.41": 0, 46 "model.layers.42": 0, 47 "model.layers.43": 0, 48 "model.layers.44": 0, 49 "model.layers.45": 0, 50 "model.layers.46": 0, 51 "model.layers.47": 1, 52 "model.layers.48": 1, 53 "model.layers.49": 1, 54 "model.layers.50": 1, 55 "model.layers.51": 1, 56 "model.layers.52": 1, 57 "model.layers.53": 1, 58 "model.layers.54": 1, 59 "model.layers.55": 1, 60 "model.layers.56": 1, 61 "model.layers.57": 1, 62 "model.layers.58": 1, 63 "model.layers.59": 1, 64 "model.layers.60": 1, 65 "model.layers.61": 1, 66 "model.layers.62": 1, 67 "model.layers.63": 1, 68 "model.layers.64": 1, 69 "model.layers.65": 1, 70 "model.layers.66": 1, 71 "model.layers.67": 1, 72 "model.layers.68": 1, 73 "model.layers.69": 1, 74 "model.layers.70": 1, 75 "model.layers.71": 1, 76 "model.layers.72": 1, 77 "model.layers.73": 1, 78 "model.layers.74": 1, 79 "model.layers.75": 1, 80 "model.layers.76": 1, 81 "model.layers.77": 1, 82 "model.layers.78": 1, 83 "model.layers.79": 1, 84 "model.norm": 1 85 } 86 # Load pre-trained models (without valuehead) 87 model = AutoModelForCausalLM.from_pretrained( 88 model_to_load, 89 config=config, 90 device_map = maps, 91 torch_dtype=model_args.compute_dtype, 92 low_cpu_mem_usage=(not is_deepspeed_zero3_enabled()), 93 **config_kwargs 94 )
我们手动设置的device_map如上所示
生成device_map可以用下面的代码实现(一般的llama架构都可以)
answer= {} answer ['lm_head'] = 0 answer ['model.embed_tokens'] = 0 for i in range(80): device = i // 45 answer['model.layers.{}'.format(i)] = device answer ['model.norm'] = 1 import json print(json.dumps(answer, indent=4))
这个每一层的情况,我们可以在模型结构中看到
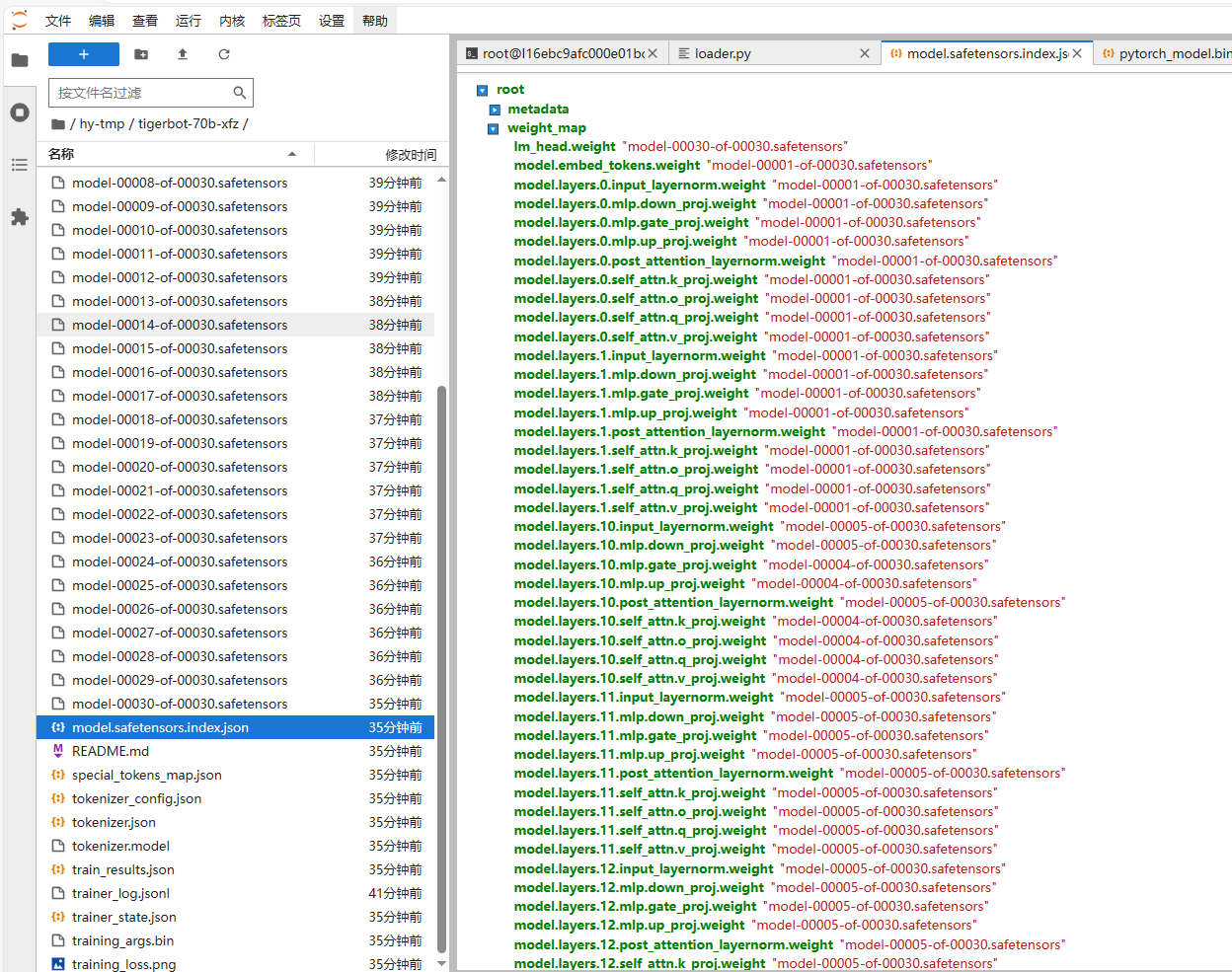
由于不明原因,配置device_map时和图示会有一定的区别(比如上面删掉了.weight),不然会报tensor must be on same device.
最后,笔者新增一个freeze的配置信息在下面
1 python src/train_bash.py \ 2 --stage sft \ 3 --model_name_or_path /hy-tmp/tigerbot-70b-chat-v4-4k \ 4 --do_train True \ 5 --finetuning_type freeze \ 6 --num_layer_trainable 2 \ 7 --template tigerbot \ 8 --dataset_dir data \ 9 --dataset self_cognition_golden \ 10 --cutoff_len 4096 \ 11 --learning_rate 1e-4 \ 12 --num_train_epochs 4.0 \ 13 --per_device_train_batch_size 1 \ 14 --gradient_accumulation_steps 8 \ 15 --logging_steps 1 \ 16 --save_steps 10000 \ 17 --output_dir /hy-tmp/tigerbot-70b-xfz \ 18 --fp16 True \ 19 --plot_loss True \ 20 --overwrite_output_dir

 浙公网安备 33010602011771号
浙公网安备 33010602011771号