Llama2模型预训练,推理与微调测试
官方环境要求(推理、微调):
本次部署使用单卡A100-40G显卡。
部署
虚拟环境创建:
conda create -n test python=3.10.9
conda activate test #启动虚拟环境
拉取 Llama2-Chinese
git clone https://github.com/FlagAlpha/Llama2-Chinese.git
cd Llama2-Chinese
安装依赖库:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #使用清华源安装
拉取 Llama2-Chinese-13b-Chat 模型权重及代码
git lfs install
git clone git clone https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat
执行git lfs install时如果报错
Git LFS is a command line extension and specification for managing large files with Git. The client is written in Go, with pre-compiled binaries available for Mac, Windows, Linux, and FreeBSD. Check out the website for an overview of features.先安装
apt-get install git-lfs
查看文件详情 ls -l
-rw-r--r-- 1 root root 683 Aug 7 17:02 config.json
-rw-r--r-- 1 root root 175 Aug 7 17:02 generation_config.json
-rw-r--r-- 1 root root 9948728430 Aug 7 17:34 pytorch_model-00001-of-00003.bin
-rw-r--r-- 1 root root 9904165024 Aug 7 17:34 pytorch_model-00002-of-00003.bin
-rw-r--r-- 1 root root 6178983625 Aug 7 17:28 pytorch_model-00003-of-00003.bin
-rw-r--r-- 1 root root 33444 Aug 7 17:02 pytorch_model.bin.index.json
-rw-r--r-- 1 root root 1514 Aug 7 17:02 README.md
-rw-r--r-- 1 root root 414 Aug 7 17:02 special_tokens_map.json
-rw-r--r-- 1 root root 749 Aug 7 17:02 tokenizer_config.json
-rw-r--r-- 1 root root 499723 Aug 7 17:02 tokenizer.model
如果文件大小和数量不正确,说明权重文件下载失败,执行 rm -rf Llama2-Chinese-13b-Chat,再重新拉取(需要多试几次)。或者可以单独下载模型:
wget https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat/resolve/main/pytorch_model-00001-of-00003.bin
wget https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat/resolve/main/pytorch_model-00002-of-00003.bin
wget https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat/resolve/main/pytorch_model-00003-of-00003.bin
注:由于权重文件较大,且是hf是境外网站,经常会出现下载失败或者网速比较慢的情况,甚至会导致下载的模型文件缺失、运行时出现错误。正确的模型文件已上传至oss,可通过oss直接下载,速度快。
在Llama2-Chinese目录下创建一个python文件 generate.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('Llama2-Chinese-13b-Chat',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('Llama2-Chinese-13b-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下华南理工大学\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
运行测试
执行 python generate.py,看到输出结果:
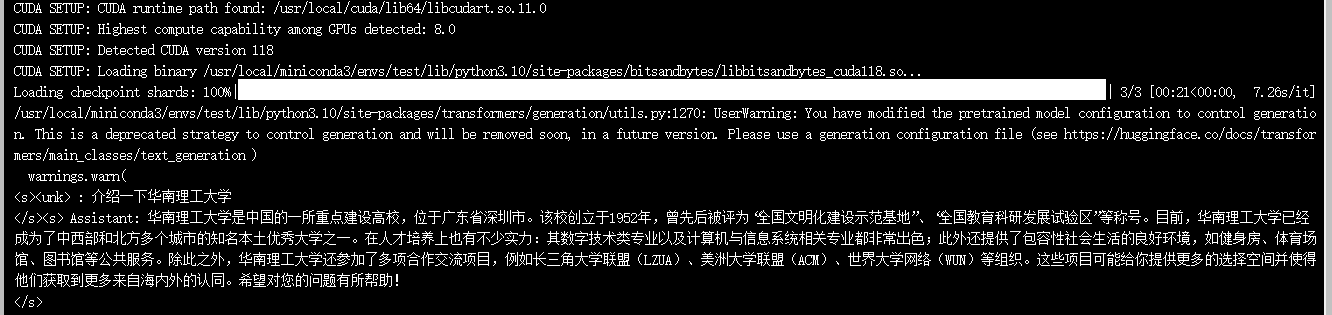

可见该模型存在许多事实性错误,中文组织能力弱。
微调
数据准备
首先准备自己的训练数据和验证数据(csv格式):
每个csv文件中包含一列“text”,每一行为一个训练样例,每个训练样例按照以下格式将问题和答案组织为模型输入
按照以下格式自定义训练和验证数据集:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案
例如,
<s>Human: 你是谁?</s><s>Assistant: 我是Llama-Chinese-13B-chat,一个由小明在2023年开发的人工智能助手。</s>
将数据上传至特定的文件夹内。
然后修改微调的脚本 train/sft/finetune.sh参数,主要修改模型输出路径、原始模型路径、训练数据与验证数据路径:
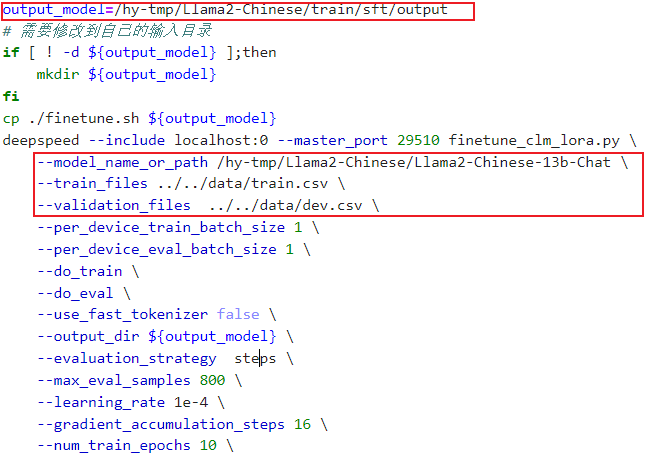
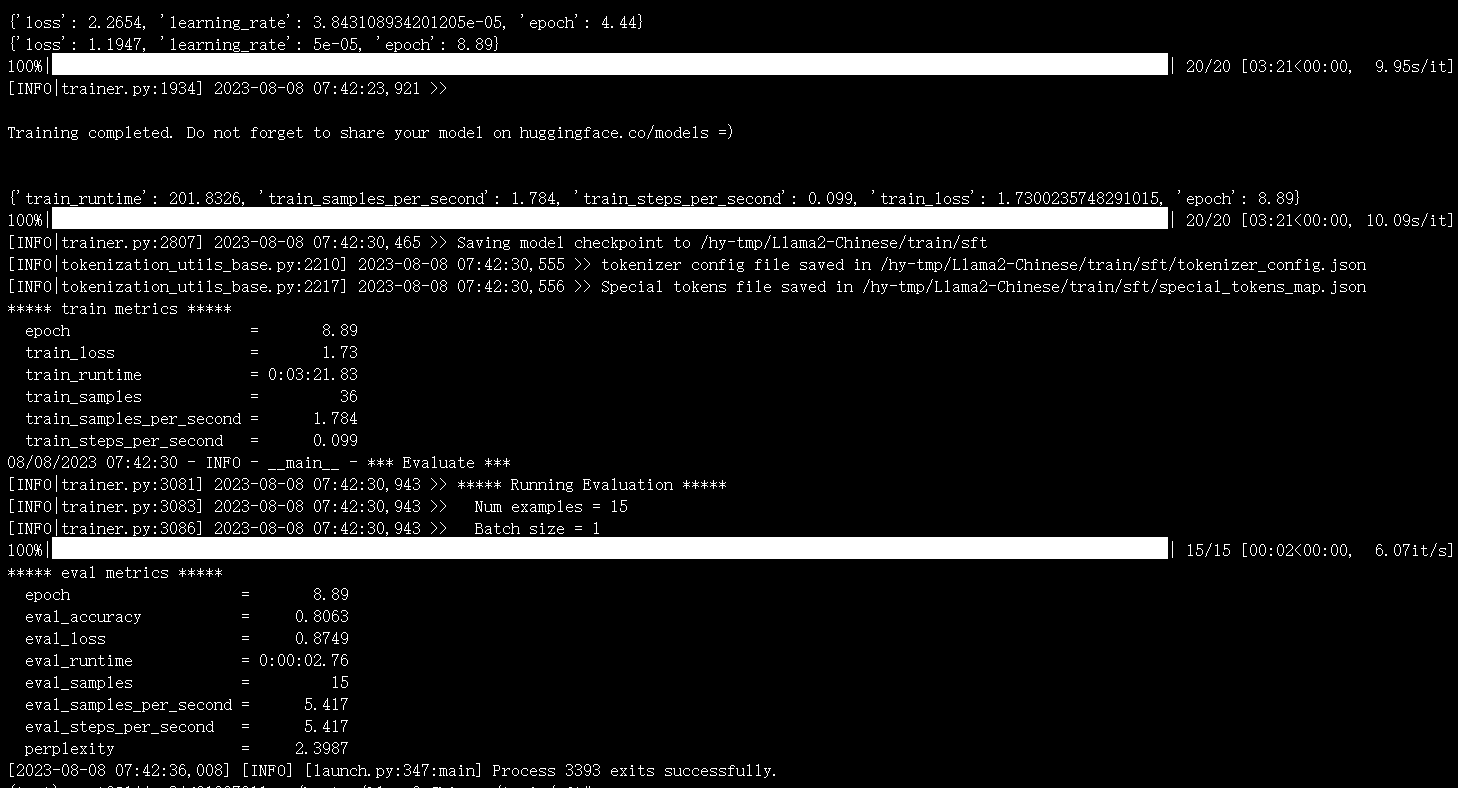
执行
bash finetune.sh
开始微调训练,得到微调后的模型:
合并模型
得到生成模型后,新建一个python文件:merge.py,用于融合原模型和新生成的模型文件(参考代码附于文末)
import argparse
import json
import os
import gc
import torch
import sys
sys.path.append("./")
import peft
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer
from huggingface_hub import hf_hub_download
parser = argparse.ArgumentParser()
parser.add_argument('--base_model', default=None, required=True,
type=str, help="Please specify a base_model")
parser.add_argument('--lora_model', default=None, required=True,
type=str, help="Please specify LoRA models to be merged (ordered); use commas to separate multiple LoRA models.")
parser.add_argument('--offload_dir', default=None, type=str,
help="(Optional) Please specify a temp folder for offloading (useful for low-RAM machines). Default None (disable offload).")
parser.add_argument('--output_type', default='pth',choices=['pth','huggingface'], type=str,
help="save the merged model in pth or huggingface format.")
parser.add_argument('--output_dir', default='./', type=str)
emb_to_model_size = {
4096 : '7B',
5120 : '13B',
6656 : '30B',
8192 : '65B',
}
num_shards_of_models = {'7B': 1, '13B': 2}
params_of_models = {
'7B':
{
"dim": 4096,
"multiple_of": 256,
"n_heads": 32,
"n_layers": 32,
"norm_eps": 1e-06,
"vocab_size": -1,
},
'13B':
{
"dim": 5120,
"multiple_of": 256,
"n_heads": 40,
"n_layers": 40,
"norm_eps": 1e-06,
"vocab_size": -1,
},
}
def transpose(weight, fan_in_fan_out):
return weight.T if fan_in_fan_out else weight
# Borrowed and modified from https://github.com/tloen/alpaca-lora
def translate_state_dict_key(k):
k = k.replace("base_model.model.", "")
if k == "model.embed_tokens.weight":
return "tok_embeddings.weight"
elif k == "model.norm.weight":
return "norm.weight"
elif k == "lm_head.weight":
return "output.weight"
elif k.startswith("model.layers."):
layer = k.split(".")[2]
if k.endswith(".self_attn.q_proj.weight"):
return f"layers.{layer}.attention.wq.weight"
elif k.endswith(".self_attn.k_proj.weight"):
return f"layers.{layer}.attention.wk.weight"
elif k.endswith(".self_attn.v_proj.weight"):
return f"layers.{layer}.attention.wv.weight"
elif k.endswith(".self_attn.o_proj.weight"):
return f"layers.{layer}.attention.wo.weight"
elif k.endswith(".mlp.gate_proj.weight"):
return f"layers.{layer}.feed_forward.w1.weight"
elif k.endswith(".mlp.down_proj.weight"):
return f"layers.{layer}.feed_forward.w2.weight"
elif k.endswith(".mlp.up_proj.weight"):
return f"layers.{layer}.feed_forward.w3.weight"
elif k.endswith(".input_layernorm.weight"):
return f"layers.{layer}.attention_norm.weight"
elif k.endswith(".post_attention_layernorm.weight"):
return f"layers.{layer}.ffn_norm.weight"
elif k.endswith("rotary_emb.inv_freq") or "lora" in k:
return None
else:
print(layer, k)
raise NotImplementedError
else:
print(k)
raise NotImplementedError
def unpermute(w):
return (
w.view(n_heads, 2, dim // n_heads // 2, dim).transpose(1, 2).reshape(dim, dim)
)
def save_shards(model_sd, num_shards: int):
# Add the no_grad context manager
with torch.no_grad():
if num_shards == 1:
new_state_dict = {}
for k, v in model_sd.items():
new_k = translate_state_dict_key(k)
if new_k is not None:
if "wq" in new_k or "wk" in new_k:
new_state_dict[new_k] = unpermute(v)
else:
new_state_dict[new_k] = v
os.makedirs(output_dir, exist_ok=True)
print(f"Saving shard 1 of {num_shards} into {output_dir}/consolidated.00.pth")
torch.save(new_state_dict, output_dir + "/consolidated.00.pth")
with open(output_dir + "/params.json", "w") as f:
json.dump(params, f)
else:
new_state_dicts = [dict() for _ in range(num_shards)]
for k in list(model_sd.keys()):
v = model_sd[k]
new_k = translate_state_dict_key(k)
if new_k is not None:
if new_k=='tok_embeddings.weight':
print(f"Processing {new_k}")
assert v.size(1)%num_shards==0
splits = v.split(v.size(1)//num_shards,dim=1)
elif new_k=='output.weight':
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif new_k=='norm.weight':
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'ffn_norm.weight' in new_k:
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'attention_norm.weight' in new_k:
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'w1.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'w2.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'w3.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'wo.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'wv.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif "wq.weight" in new_k or "wk.weight" in new_k:
print(f"Processing {new_k}")
v = unpermute(v)
splits = v.split(v.size(0)//num_shards,dim=0)
else:
print(f"Unexpected key {new_k}")
raise ValueError
for sd,split in zip(new_state_dicts,splits):
sd[new_k] = split.clone()
del split
del splits
del model_sd[k],v
gc.collect() # Effectively enforce garbage collection
os.makedirs(output_dir, exist_ok=True)
for i,new_state_dict in enumerate(new_state_dicts):
print(f"Saving shard {i+1} of {num_shards} into {output_dir}/consolidated.0{i}.pth")
torch.save(new_state_dict, output_dir + f"/consolidated.0{i}.pth")
with open(output_dir + "/params.json", "w") as f:
print(f"Saving params.json into {output_dir}/params.json")
json.dump(params, f)
if __name__=='__main__':
args = parser.parse_args()
base_model_path = args.base_model
lora_model_paths = [s.strip() for s in args.lora_model.split(',') if len(s.strip())!=0]
output_dir = args.output_dir
output_type = args.output_type
offload_dir = args.offload_dir
print(f"Base model: {base_model_path}")
print(f"LoRA model(s) {lora_model_paths}:")
if offload_dir is not None:
# Load with offloading, which is useful for low-RAM machines.
# Note that if you have enough RAM, please use original method instead, as it is faster.
base_model = LlamaForCausalLM.from_pretrained(
base_model_path,
load_in_8bit=False,
torch_dtype=torch.float16,
offload_folder=offload_dir,
offload_state_dict=True,
low_cpu_mem_usage=True,
device_map={"": "cpu"},
)
else:
# Original method without offloading
base_model = LlamaForCausalLM.from_pretrained(
base_model_path,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
print(base_model)
## infer the model size from the checkpoint
embedding_size = base_model.get_input_embeddings().weight.size(1)
model_size = emb_to_model_size[embedding_size]
print(f"Peft version: {peft.__version__}")
print(f"Loading LoRA for {model_size} model")
lora_model = None
lora_model_sd = None
for lora_index, lora_model_path in enumerate(lora_model_paths):
print(f"Loading LoRA {lora_model_path}")
tokenizer = LlamaTokenizer.from_pretrained(lora_model_path)
assert base_model.get_input_embeddings().weight.size(0) == len(tokenizer)
# if base_model.get_input_embeddings().weight.size(0) != len(tokenizer):
# base_model.resize_token_embeddings(len(tokenizer))
# print(f"Extended vocabulary size to {len(tokenizer)}")
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
if hasattr(peft.LoraModel, 'merge_and_unload'):
lora_model = PeftModel.from_pretrained(
base_model,
lora_model_path,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
assert torch.allclose(first_weight_old, first_weight)
print(f"Merging with merge_and_unload...")
base_model = lora_model.merge_and_unload()
else:
base_model_sd = base_model.state_dict()
try:
lora_model_sd = torch.load(os.path.join(lora_model_path,'adapter_model.bin'),map_location='cpu')
except FileNotFoundError:
print("Cannot find lora model on the disk. Downloading lora model from hub...")
filename = hf_hub_download(repo_id=lora_model_path,filename='adapter_model.bin')
lora_model_sd = torch.load(filename,map_location='cpu')
lora_config = peft.LoraConfig.from_pretrained(lora_model_path)
lora_scaling = lora_config.lora_alpha / lora_config.r
fan_in_fan_out = lora_config.fan_in_fan_out
lora_keys = [k for k in lora_model_sd if 'lora_A' in k]
non_lora_keys = [k for k in lora_model_sd if not 'lora_' in k]
for k in non_lora_keys:
print(f"merging {k}")
original_k = k.replace('base_model.model.','')
base_model_sd[original_k].copy_(lora_model_sd[k])
for k in lora_keys:
print(f"merging {k}")
original_key = k.replace('.lora_A','').replace('base_model.model.','')
assert original_key in base_model_sd
lora_a_key = k
lora_b_key = k.replace('lora_A','lora_B')
base_model_sd[original_key] += (
transpose(lora_model_sd[lora_b_key].float() @ lora_model_sd[lora_a_key].float(),fan_in_fan_out) * lora_scaling
)
assert base_model_sd[original_key].dtype == torch.float16
# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)
tokenizer.save_pretrained(output_dir)
if output_type=='huggingface':
print("Saving to Hugging Face format...")
LlamaForCausalLM.save_pretrained(
base_model, output_dir,
max_shard_size="2GB"
) #, state_dict=deloreanized_sd)
else: # output_type=='pth
print("Saving to pth format...")
base_model_sd = base_model.state_dict()
del lora_model, base_model, lora_model_sd
params = params_of_models[model_size]
num_shards = num_shards_of_models[model_size]
n_layers = params["n_layers"]
n_heads = params["n_heads"]
dim = params["dim"]
dims_per_head = dim // n_heads
base = 10000.0
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
save_shards(model_sd=base_model_sd, num_shards=num_shards)
调用方法:
CUDA_VISIBLE_DEVICES="3" python merge.py \
--base_model /hy-tmp/Llama2-Chinese/Llama2-Chinese-13b-Chat \
--lora_model /hy-tmp/Llama2-Chinese/train/sft/output \
--output_type huggingface \
--output_dir ./output_merge
注 : base_model 为原模型路径,lora_model 为训练后生成模型了路径 , output_dir 为合并后模型生成路径
执行代码合并成功后,可以看见在输出目录出现新的模型:

测试
获得新模型后,修改 generate.py中的模型路径为 output_dir
开始运行测试:python generate.py

对比原输出,可以看出微调效果明显:

Llama2基座模型增量预训练
前言
AI模型的训练训练过程分为如下三个阶段
第一个阶段叫做无监督学习(PreTraining),就是输入大量的文本语料让GPT自己寻找语言的规律, 这样一个巨大的词向量空间就形成了,但是话说的漂亮并不一定正确。
第二个阶段叫做监督学习(Supervised Fine-Tuning,也叫微调),就是人工标注一些语料,教会GPT什 么该说,什么不该说。(训练数据集)
第三个阶段叫做强化学习(RM,也叫奖励模型训练),就是给GPT的回答进行打分,告诉他在他 的一众回答中,哪些回答更好。(验证数据集)
第一个阶段(无监督学习)分为了底座模型预训练,及增量预训练,它们都属于无监督学习,接下来基于Llama2底座模型继续使用大量文本进行增量预训练。
经测试,训练的硬件需求至少需要6张40G*A100。
1.环境准备
在提供的预训练文件夹中,下载原始模型,放入 llama_script/training/pretrained_model目录下
拉取transformers项目并安装依赖
git clone https://github.com/huggingface/transformers.git
pip install -e .
在后续的训练中,需要使用到HuggingFace格式的基座模型。如果下载了官网的PyTorch版本,需重新下载,也可使用transformers中的脚本转换为HuggingFace格式。
cd /transformers
python src/transformers/models/llama/convert_llama_weights_to_hf.py
--input_dir ./llama
--model_size 7B
--output_dir ./output
2.数据准备
将数据按照段落划分为多个txt文件,每个文件中只包含一个段落,且段落被包含在 <s> </s>内:

将上述的文本数据放入文件夹下的 dataset_dir目录下。
3.开始训练
进入项目的 train目录下,修改 pretrain脚本参数,主要修改 model_name_or_path(基座模型路径),tokenizer_name_or_path(分词器路径),dataset_dir(数据集路径)参数(若已经按照前面的步骤放在指定的文件夹下,则不需要修改。)
开始训练,默认使用单卡训练,如需使用多卡,修改脚本中 nproc_per_node参数
cd training
bash pretrain.sh
4.合并文件
训练后的LoRA权重和配置存放于output/pt_lora_model中,运行文件夹中的合并代码:
python merge_llama.py --base_model /hy-tmp/Llama-2-7b-hf --lora_model /hy-tmp/output_dir/pt_lora_model --output_dir /hy-tmp/output_merge --output_type huggingface
根据实际情况修改参数的路径以及输出类型,即可开始合并。
5.推理测试
调用生成代码进行测试,结果如下:
原始模型:

训练后:

可见经过增量预训练,模型成功学习了新知识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号