基于LSTM的中文姓名性别预测
基于LSTM的中文姓名性别预测
写在前面
这是本人编写的首个基于调库的机器学习程序,算是一个简单的练手项目。
本程序可以根据输入的中文姓名推测其对应的性别
根据人的名字判断人的性别是一个很有意思的工作,我们可以用朴素贝叶斯法,SVM法或神经网络解决。Python有个第三方库叫做ngender,它采用朴素贝叶斯进行预测,然而,该模型的准确度仍有待提高。
本人基于Pytorch,采用embedding+LSTM+Linear的神经网络模型进行性别的预测,准确率达到了88%
代码已经上传至GitHub,[这是GitHub链接](AlphaINF/name2gender: Gender prediction of chinese name based on LSTM (github.com))
本人将在下文中,详细介绍模型的结构和使用方法,以及我对每一个模块的理解
运行方法
将仓库中全部文件下载到本地
直接运行main.py,输入姓名即可进行预测
训练方法
将仓库中全部文件下载到本地
调整finetune中的data=xxx_loader及其对应的文件名,选择对应的文件作为训练集
调整test中的data=xxx_loader及其对应的文件名,选择对应的文件作为测试集
调整finetune中的模型保存规则(可以查看torch.save部分)
运行finetune.py
文件结构
本程序包含以下几个文件,文件结构如下图所示
每个文件的用途如下表所示
| 文件名 | 用途 |
|---|---|
| name2gender.py | 用于保存模型的结构 |
| main.py | 直接运行即可输入名字进行性别预测 |
| test.py | 用于运行测试集的代码 |
| finetune.py | 用于训练的代码 |
| utils.py | 一些工具(比如csv的读取工具) |
| net.pth | 训练好的神经网络 |
| ccnc.csv | 数据集1(采用ccnc_loader进行读取),包含有约350w组数据,每组数据的格式为(姓氏,名字,姓名,性别),采用换行和tab间隔 |
| train.csv | 数据集2(采用csv_loader进行读取),包含有约20w组数据,每组数据的格式为(姓名,性别),采用换行和逗号间隔 |
| test.csv/ccnc-tiny.csv | 测试集 |
数据输入和预处理
笔者找到了两个数据集,一个是ccnc数据集,另一个是train.csv/test.csv 。经实测train/test效果更加
ccnc.csv
ccnc.csv,包含有365.8w条数据,ccnc-tiny是ccnc中截取的数据。其格式如下图所示
姓 名 全名 性别(第一行可以忽略)
陈 品如 陈品如 M
陈 祥旭 陈祥旭 M
陈 晓 陈晓 M
陈 东慧 陈东慧 M
陈 镇彬 陈镇彬 M
分隔符为tab
在utils.py中,笔者为其编写了数据读取代码
def ccnc_loader(file_name):
logging.info('[DataLoader]: loading data, path =' + file_name)
fp = open(file_name, "r", encoding='utf-8', errors='ignore')
next(fp)
all = fp.read().split('\n')
fp.close()
output = []
for line in all:
line_element = str(line).split('\t')
# print(line_element)
try:
label = ['F', 'M'].index(line_element[3])
output.append((line_element[2], line_element[3]))
except:
label = 0
logging.info('[DataLoader]: finished loading, len = ', len(output))
return output
注意:ccnc.csv中的性别标签包含有U(unknown),所以要进行特判
笔者将label[2]和label[3] (也就是姓名和性别)存入dataset中,大家也可以将其改成存入名字和性别。
train.csv
train.csv中包含20w条数据,test.csv中包含2w条数据,其格式如下
赵伏琴,女
钱沐杨,男
孙竹珍,女
李潮阳,男
蔡凤灿,男
范素菊,女
赵朕林,女
陆好骋,女
王舒梅,女
孙国江,男
分隔符为逗号
在utils中,笔者为其编写了数据读取代码
def csv_loader(file_name):
fp = open(file_name, "r", encoding='utf-8', errors='ignore')
all = fp.read().split('\n')
fp.close()
output = []
for line in all:
line_element = str(line).split(',')
# print(line_element)
try:
label = ['女', '男'].index(line_element[1])
output.append((line_element[0], ['F', 'M'][label]))
except:
label = 0
logging.info('[DataLoader]: finished loading, len = ', len(output))
return output
注意:性别的存储进行了转换,转换为了ccnc的格式
Dataset和DataLoader
DataLoader是Pytorch自带的数据读取器,需要传入dataset(一个数据集)参数和batch_size参数,DataLoader会对数据进行自动切分为多份,每一份中包含batch_size组数据。
dataset必须是类Dataset的派生类,用于装填自己及需要的数据。它的作用是:只要告诉它数据在哪里(初始化),就可以像使用iterator一样去拿到数据,继承该类后,需要重载__len__()以及__getitem__
笔者在学习的过程中,曾认为自己写一个加载数据的工具似乎也没有多“困难”,为何大费周章要继承pytorch中类,按照它的规则加载数据呢?总结一下就是:
当数据量很大的时候,单进程加载数据很慢
一次全加载过来,会占用很大的内存空间(因此dataloader是一个生成器,惰性加载)
在进行训练前,往往需要一些数据预处理或数据增强等操作,pytorch的dataloader已经封装好了,避免了重复造轮子
笔者的Dataset类定义代码如下:
class NameDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, item):
data = self.data[item]
name = data[0]
label = ['F', 'M'].index(data[1])
return name, label
def __len__(self):
return len(self.data)
笔者调用数据读取,创建Dataset和DataLoader的代码如下:
data = csv_loader('dataset/train.csv')
data_set = NameDataset(data)
batch_size = 64
data_loader = DataLoader(data_set, batch_size=batch_size, shuffle=True)
数据格式转换
存入DataLoader中的数据,DataLoader会对数据进行一些预处理。
比如说某一批数据中,性别的标签为[0,1,0,0,0,1,1],经过DataLoader后,数据会变成tensor([0, 1, 0, 0, 0, 1, 1]),tensor类型的数据才能送入神经网络中进行训练。
但对于存储姓名的字符串,DataLoader并不会进行处理,需要我们手动转换
下方的函数,输入是姓名表names和性别表labels,输出是tensor格式的names表,labels表和长度表。
def name_to_list(name):
character_list = []
for ch in name:
try:
val = ch.encode(encoding='ansi')
character_list.append((val[0] - 128) << 8 | val[1])
except:
character_list.append(0)
return character_list
def value_to_tensor(names, labels):
name_list = []
for name in names:
name_list.append(name_to_list(name))
lengths = np.array([len(name) for name in name_list])
max_len = max(lengths)
name_tensors = torch.zeros(len(names), max_len)
for i, idx in enumerate(name_list):
for j, e in enumerate(idx):
name_tensors[i][j] = e
name_tensors = name_tensors.to(torch.long)
lengths = torch.from_numpy(lengths).to(torch.long)
return name_tensors, labels, lengths
笔者采用的姓名转码方式为:对于姓名'刘子晶',先将其视为字符数组['刘','子','晶'],然后对于每个字,获得在ANSI编码下的数值[0xC1F5,0xD7D3,0xBEA7],然后对每个数值减去0x8000,即完成转码,输出对应的数值[0x41F5,0x57D3,0x3EA7]
对于输出的数值,在value_to_tensor函数中,还要将每一组姓名的长度对齐,并转化为tensor格式,否则输入神经网络的时候会报错。
模型结构
我们可以通过mane2gender.py来了解模型的结构
import torch.nn as nn
class name2gender(nn.Module):
def __init__(self, input_size, embedding_size, rnn_hidden_size, hidden_size, output_size=2):
super(name2gender, self).__init__()
self.embeddings = nn.Embedding(input_size, embedding_size, padding_idx=0)
self.drop = nn.Dropout(p=0.1)
self.rnn = nn.LSTM(input_size=embedding_size, hidden_size=rnn_hidden_size, batch_first=True)
self.linear1 = nn.Linear(rnn_hidden_size, hidden_size)
self.activation = nn.ReLU()
self.linear2 = nn.Linear(hidden_size, output_size)
self.output_size = output_size
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, name, length):
now = self.embeddings(name)
now = self.drop(now)
input_packed = nn.utils.rnn.pack_padded_sequence(now, length, batch_first=True, enforce_sorted=False)
_, (ht, _) = self.rnn(input_packed, None)
out = self.linear1(ht)
out = self.activation(out)
out = self.linear2(out)
out = out.view(-1, self.output_size)
out = self.softmax(out)
return out
笔者构建的模型中,input_size等参数如下:
model = name2gender(32768, 256, 128, 50)
笔者采用的模型可以分为几个部分,首先是embedding层(将字转化为字向量),dropout层(随机将一些位置的数值设为0),rnn层(进行LSTM),全连接层1,激活函数,全连接层2,softmax层,最后的输出有两个节点,分别表示该名字为男或者为女的概率。
下面将对模型中每个部分进行简单的介绍
数据输入
假设输入的名字为"刘子晶",则会按照上述的过程(数据格式转换过程),将这三个字变为一个1*3的向量,并将该向量送入embedding层
embedding层
embedding层是一个将单字转化为字向量(可以理解为字具有的属性)的过程,这个过程被称为词嵌入
举个例子:琪(ANSI编码下为0xE7F7)字,具有的属性包括:部首(王),笔画数(12),右半边长相(其),用于女性的比例(我不知道)……
处理出了单字的字向量后,我们可以通过求两个向量之间的点积以获取两个字之间的相似度(比如说琪和祺之间就有较高的相似度)
从单字到字的属性的过程,就是embedding层的用途
embedding层有一个很神奇的地方:字的属性是可以通过学习得到的,不需要我们手动设置
笔者采用的embedding层大小为32768*256,表示输入的汉字最多有32768个,对于输入的每一个字,将会输出一个包含256个float的向量,用于表示这个字的属性。
至于汉字如何转化为[0,32767]间的整数,可以看下方的“数据输入”,由于字库较小,输入非常非常生僻的字可能导致信息丢失。
关于更多embedding层的知识可以见[这篇blog]((34条消息) [文本分类]深入理解embedding层的模型、结构与文本表示_征途黯然.的博客-CSDN博客_embedding模型)
还是以一个三字的输入举例:输入的是一个\(1\times 3\)的向量,embedding层会先将这些输入,转为\(1\times 3\times 32768\)的01向量(对于任意的\((i,j,k)\),当i,j确定时,k只有一个位置为1,即与编码对应的字符为1),随后进入embedding层进行矩阵乘法,最后输出是\(1\times 3\times 256\)的向量,也就是每个字的编码变成了这个字对应的字向量。
如果是m组三字输入数据,则输入是\(m\times 3\)的向量,输出是\(m\times 3\times 256\)的向量
注意这个256是由上文中的embedding_size确定的
dropout层
dropout的功能是:对于输入的向量,每个元素有p的概率会变为0,本代码中p设置为0.1
dropout层的功能在于:在训练时,随机让一定数量的值归零,可以提高网络的泛化能力,可以避免过拟合
注:在测试的时候,一般不会启用dropout层,笔者在这里并没有进行判断
输入dropout层的数据为\(m\times 3 \times 256\)(m含义如上文所示),输出的规模并没有出现变化
LSTM层
LSTM是一种升级的RNN神经网络,。相比一般的神经网络(比如全连接的BP)来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
如果你学过最简单的bp神经网络,你可以通过这两个视频来学习RNN和LSTM,动画做的贼好!
视频一:RNN的学习视频【循环神经网络】5分钟搞懂RNN,3D动画深入浅出_哔哩哔哩_bilibili
视频二:LSTM的学习视频【LSTM长短期记忆网络】3D模型一目了然,带你领略算法背后的逻辑_哔哩哔哩_bilibili
这里有一份c++的RNN源代码,可以用来看原理链接
对于输入数据,假设输入是\(m\times 3\times 256\)的数据(即为m组数据,每组数据有三个字,每个字由一个长度为256的字向量构成),则输出将变为\(m\times 128\),其中128由rnn_hidden_size确定,3的消失是因为:每一组数据,是按照“字”的先后顺序输入进RNN中的。其中m是数据的组数
全连接层1
从LSTM连出,我们决定连一个全连接层
通过该全连接层,数据的规模将会从\(m\times 128\)下降为\(m\times 50\),并且融合更多的信息
至于这东西为啥有用?(问就是玄学)
激活函数
激活函数可以将全连接层中的线性变换,转化为非线性变换
可以看这篇文章形象的解释神经网络激活函数的作用是什么? - 知乎 (zhihu.com)
至于为何LSTM到全连接层1不需要线性变换?这是因为LSTM内自带了激活函数(
全连接层2
从激活后的全连接层1中,对于一组数据,我们仍有50个函数(m组就是\(m\times 50\))
但是我们只需要两个输出(男性概率,女性概率)
所以我们需要再进行一次全连接,将\(m\times 50\)变为\(m\times 2\)
softmax层
对于剩下的两个数,求解一次softmax(可以去查查这个是做什么的)
softmax分类器可以扩大分数的差距,使得分类效果更加明显
经过softmax后,就是最终输出的答案了(男性概率,女性概率)
模型运行
我们首先输入个名字
然后把这个名字转成tensor格式,输入进这个模型中
模型将按照咱们的定义,依次把数据流过模型的每一层
最后的输出即为男性/女性的概率
模型训练
模型的训练过程可以这样理解
1,首先运行模型
2,根据模型的预测值和实际值进行比较,求出差值loss(一般采用交叉熵求解)
3,根据差值,乘上一个训练系数,进行反向传播(可以理解为:如果求出的值大了,就对网络进行一些调节,这样下次的输出就不会那么大了)
代码如下(详见finetune.py)
out = model(name_tensors, name_lengths).view(-1,2)
loss = loss_func(out, labels)
total_loss += loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
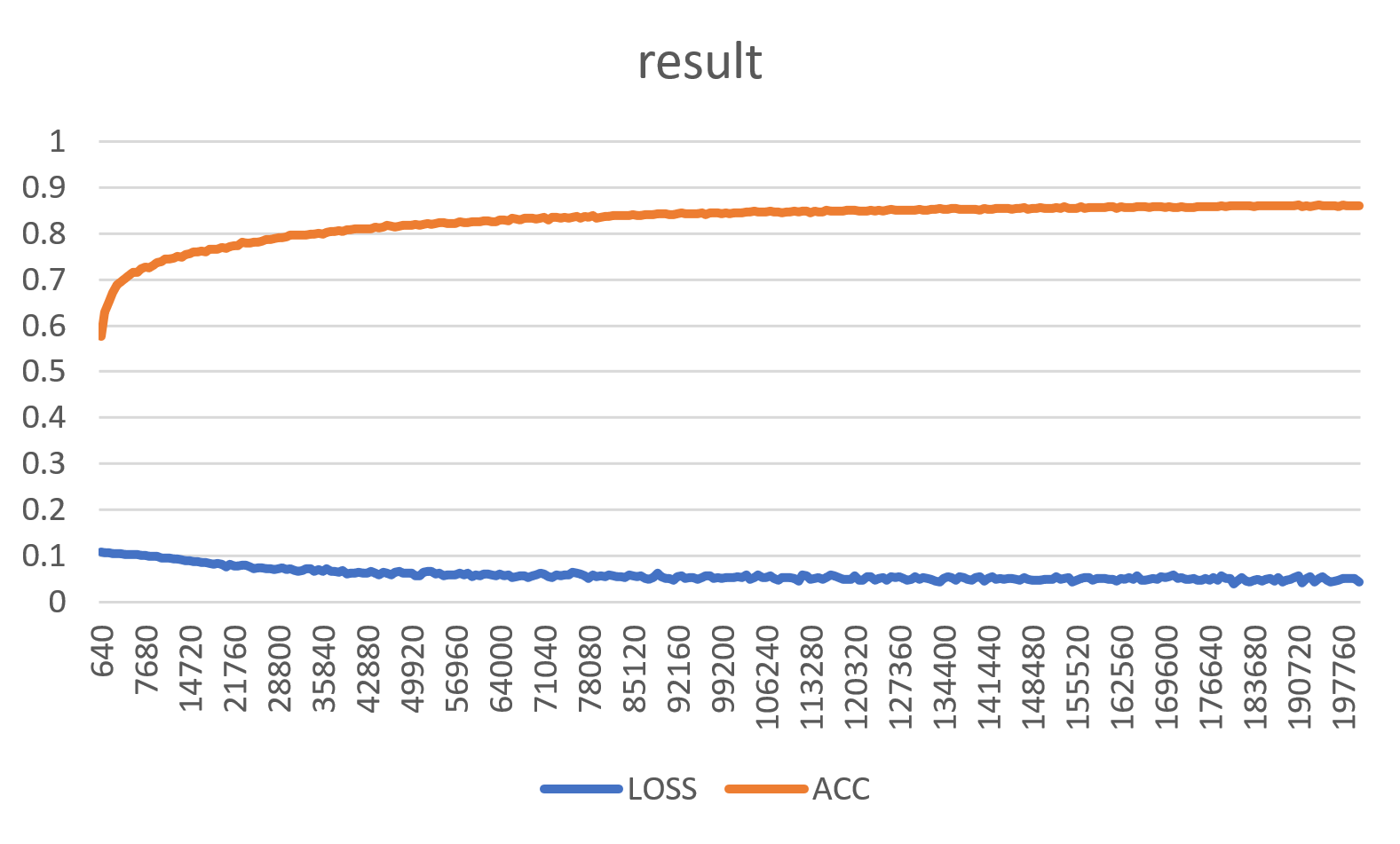
训练效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号