
python打开文件时提示“File was loaded in the wrong encoding:’UTF-8”根因调查
问题:练习CSV文件存储时,查看文件内容时出现中文乱码,如下图所示:
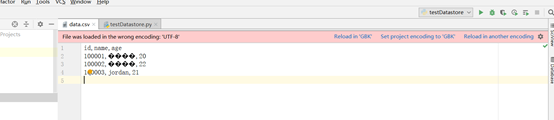
首先解决这里中文显示乱码的问题:
解决方式一:选择这里的“Reload in GBK”,然后就会发现文字正常显示了,并且pycharm当前项目的设置中,子设置项File Encoding中,这个文件的编码方式被特殊标记为了GBK。

关于File Encoding 这个子设置页的说明:
Global Encoding :全局编码方式
Project Encoding:当前项目编码方式
白色区域下面的那一段英文的意思:为了改变pycharm中一个文件、目录或者整个项目的编码方式,添加其路径并在编码列表中选择其编码方式即可。内置的文件编码(如:.JSP,.HTML,.XML)会覆盖这里的说明。如果没有说明,文件和目录会继承其父目录或者整个项目的编码方式。
这也就是为什么我们点击“reload in GBK ”后,它会被加入到白色区域中成为其中一条的原因,因为这里有特殊说明,所以这个文件以后打开的时候,不再会继承整个项目的编码方式“UTF-8”了。而我们将这里的特殊说明删除时,下次读取这个文件时,仍旧会继承Project Encoding的UTF-8,依然提示编码有误。
原因追查:
查看设置中发现pycharm中命名设置了项目和全局的编码都是UTF-8啊,想着编码都是UTF-8,而读取时却提示误用了UTF-8编码?难道文件写入不是用的UTF-8?所以用它解码才提示错误?那么提示用GBK,为什么要用GBK呢?是巧合呢还是因为写入时就是GBK,所以才有这样的提示?难道创建文件写入时,没有使用pycharm的编码设置?
既然推断文件写入可能根本没有使用pycharm的编码设置,就开始对File Encoding页进行如下各种设置,以确定写入的时候确实没有受到pycharm中编码的设置
1、全局是UTF-8,项目是GBK,打开文件时显示正常
2、全局是UTF-8,项目也是UTF-8,打开文件时提示也是使用了UTF-8,显示编码错误
3、全局是GBK,项目也是GBK,显示正常
4、全局GBK,项目是UTF-8,打开文件使用了UTF-8,显示编码错误
5、全局ShiftJIS,项目GBK,显示正常,
无论Global Encoding是什么,Project Encoding是GBK就能读取正常,其他则显示错误,就算Global Encoding和Project Encoding都设置相同,读取时仍旧显示编码错误,所以这里写入文件根本没有使用pycharm中File Encoding的设置!
继续追查问题
既然写入文件时不受IDE的影响,那么是不是问题出在open()函数呢?之后查看python官方文档关于open()函数的说明发现果然是这样,open()打开文件时,默认使用的编码方式就是依赖于系统的,官方文档如下:

意思就是:使用open()以文本模式打开文件时,如果编码未指定,则使用的编码是与平台相关的:调用locale.getpreferredencoding(False)可获取当前的本地编码。按照官方文档的提示,获取windows上系统默认编码如下:

注:CP936 就是 GBK,IBM 在发明 Code Page 的时候将 GBK 放在第 936 页,所以叫 CP936。
所以根因是:因为open()函数在没有指定编码方式时,写入文本使用的是系统默认编码,也就是GBK,所以这就是为什么我之前无论怎么修改pycharm中Global Encoding与读取时使用的Project Encoding一致,只要Project Encoding不是GBK就会显示编码错误的原因了!
posted on 2020-12-10 21:06 AlphaRobot 阅读(8019) 评论(0) 编辑 收藏 举报


