
tcptump的使用------使用JAVA与tcpdump从网络获取原始数据
从这里开始,就开始接触使用分布式系统处理大数据了。在处理大数据之前,需要有一个场景,否则技术工具无法嵌入现实当中,价值就会降低。我碰到的场景应该还是比较具有普遍性,因此大家可以在我的场景里先玩一遍,熟悉一下流程和方法,然后加以改造,加载到自己的场景和环境中。
场景:在一个大型公司内部,终端和各个业务系统之间的数据传输都通过网络进行。出于监控的要求,需要在网络上获取所有数据包,并查看数据包里是否含有某些关键字。如果含有某些关键字,证明终端和业务系统间正在进行某种操作。系统记录下这些操作,用于实时显示或统计使用。
这其实就是“行为数据”的采集和记录,是典型的大数据处理场景。
扩展一下,将该场景所使用的技术和工具加载到互联网或APP上,就可以在不改动任何业务系统、在用户无感知的情况下,采集用户的行为数据并加以利用,形成用户习惯数据。当然,也可以通过“埋点”的方式进行,但改动业务系统不要花钱嘛,能省一点是一点。
网络数据的获取。网络数据通过网络设备的“镜像口”获得。镜像口的设置可以让网管帮忙,一般可网管交换机都可以做到,思科、华三、迈普这些都没啥问题。通过镜像口获取网络数据,就可以在各个业务系统和用户无感知的情况下获取所有的数据了。当然,如果公司或者系统在传输时使用https等加密手段,这个就没办法了。不过一般公司很少在内网传输时加密。
结构如下(画功实在是感人):
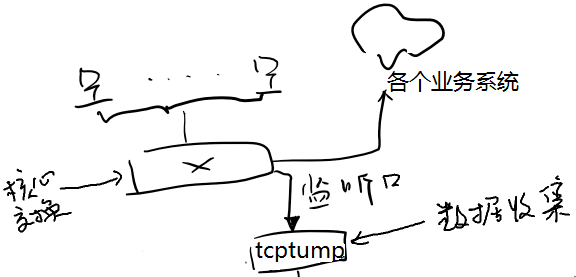
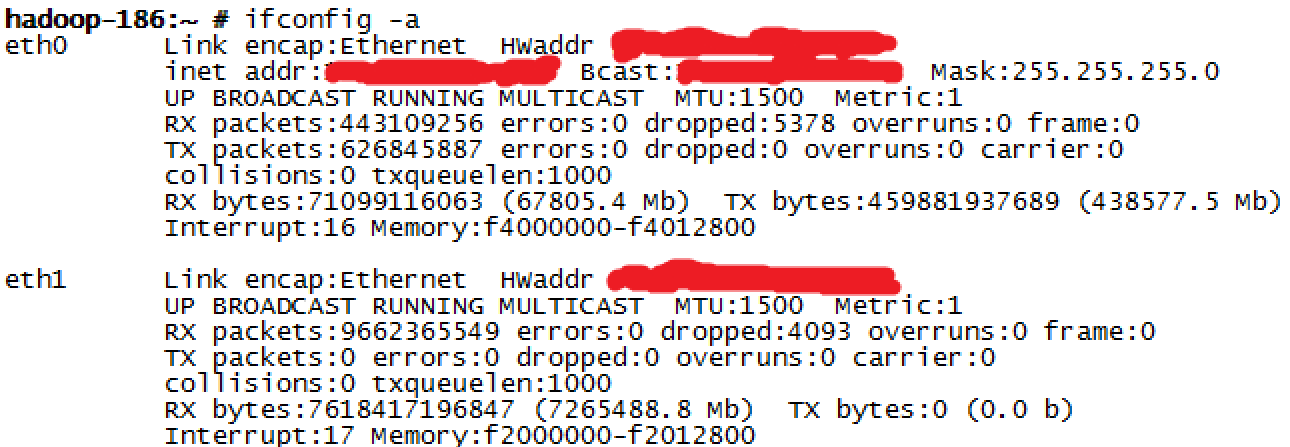
将镜像口(也就是上图的监听口)接到一台服务器的RJ45网卡上,不用配IP地址,服务器这个网卡就可以接收到所有在网络上传输的数据了。如下图,eth1就是接入镜像口的网卡。
使用 tcpdump -i eth1 可以看到网络上传输的部分数据。通过源地址、目标地址,就可以大概判断是不是公司的数据了。
tcpdump的使用很复杂,网上很多方法介绍,这里就不做解释,直接用起来。一般来说,完整的tcpdump数据包包含了很多段,每段还有标识等等。如下图:

可以看到网络包中包含有一段json,这就是在网络上传输的数据。
但直接通过tcpdump获得的这些数据是不适合直接扔给分布式系统做处理的。为什么呢?
因为分布式处理是多台设备并行处理,达到扩展数据处理能力的目的。刚刚说了,完整的tcpdump数据包包含了很多段,假设这个数据包为A,A1是第一段,A2是第二段。如果同时将A1,A2并发给分布式系统处理,并且同时出结果,把结果拼起来,这是没问题的。但现实情况是,A1比A2先处理完,先收到一个结果A1,就没法得到一个有意义的结果。更糟糕的情况时,假如此时同时出来一个B1,把A1,B1拼在一起得到一个更错误的结果。
所以,要利用分布式系统处理tcpdump的数据,就要把一个完整的数据包一次性丢给分布式处理系统,保证数据包和计算结果的完整性和对应性。也就是A1数据包进去计算,得到的是A1的计算结果。
使用tcpdump命令:
tcpdump -Anvtttt -s 0 -i eth1 tcp[20:2]=0x4745 or tcp[20:2]=0x4854 or tcp[20:2]=0x504f|sed '/ IP (tos/s/^/<<interval>>/'
需要特别说明的是,tcp[20:2]=0x4745 or tcp[20:2]=0x4854 or tcp[20:2]=0x504f 是对tcpdump数据包进行初步过滤,只需要http包,其他的比如arp、rtp包之类的不需要。
使用个命令后,tcpdump得到的数据都会在第一行留一个<<interval>>作为标志,标志这个数据包开始,到下一个<<interval>>结束。这样就可以为下一步利用JAVA清楚所有换行符做好标记。
得到的结果如下:

两个<<interval>>之间就是一个完整的tcpdump数据包。下面结合使用JAVA,将一个完整的tcpdump数据包整合成一个能被分布式大数据处理平台进行处理的数据。其实是一个简单的ETL过程。
使用JAVA对tcpdump数据包进行数据清洗,并加载到kafka中
1、使用eclipse新建一个maven工程,这里起名叫shell
2、使用pom.xml对依赖包进行管理,主要使用kafka的依赖包。


<dependencies> <!-- kafka --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.1.1</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.1.1</version> </dependency> <dependency> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-resources-plugin</artifactId> <version>2.3</version> </dependency> </dependencies>
3、在kafka中设置一个topic。这个kafka的配置和topic的配置以后再说,不难。如果不知道怎么弄,可以在JAVA程序里写到一个本地文本文件里。这算是个作业,大家自己做吧。
4、将每个tcpdump包中两个<<interval>>之间的数据进行清洗。主要是把其中的换行符替换成“|”符号,清除掉其他不想要的符号。把清洗干净的数据放到s_right变量中等待发送。接着清洗另一条数据,清洗完第二条数据后,将s_right里的数据前移到s_left中并发送到kafka里,第二条数据放在s_right中等待发送。
package shell; import java.io.*; import java.text.SimpleDateFormat; import java.util.Properties; import java.util.concurrent.ExecutionException; import java.util.Date; import java.util.Calendar; //import kafka.producer.*; //import kafka.serializer.StringEncoder; //import kafka.javaapi.producer.Producer; //import kafka.producer.Partitioner; //import kafka.producer.ProducerConfig; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; public class runShell { // private static kafka.javaapi.producer.Producer<Integer, String> producer // = null; public static void main(String[] args) throws IOException, InterruptedException, ExecutionException { String SHELL_FILE_DIR, SHELL_FILE; SHELL_FILE_DIR = "/hadoop/sh/"; //把tcpdump命令放到一个sh文件中,把文件地址写在SHELL_FILE 中,这样JAVA //程序就可以调用tcpdump命令了 SHELL_FILE = "./" + "getTcpdump.sh"; String s = null; String s_left = "", s_right = ""; int runningStatus = 0; Properties props = new Properties(); props.put("bootstrap.servers","你的kafka的地址和端口"); props.put("acks", "1"); props.put("retries", 0); props.put("linger.ms", 0); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 将props的配置放到kafka中 Producer<String, String> producer = new KafkaProducer<String, String>(props); // 设置kafka的topic String TOPIC = "netRawdata"; ProcessBuilder pb = new ProcessBuilder(SHELL_FILE); pb.directory(new File(SHELL_FILE_DIR)); Process p = pb.start(); BufferedReader stdInput = new BufferedReader(new InputStreamReader(p.getInputStream())); BufferedReader stdError = new BufferedReader(new InputStreamReader(p.getInputStream())); while ((s = stdInput.readLine()) != null) { if (s.startsWith("<<interval>>")) { s_left = s_right; s_right = s.substring(12); if (s_left != "") { s_left = s_left.replaceAll("\t", " "); s_left = s_left.replaceAll(" +", " "); producer.send(new ProducerRecord<String, String>(TOPIC, s_left)).get(); System.out.println(s_left); } } else { s_right = s_right + "|" + s; } } while ((s = stdError.readLine()) != null) { System.out.println(s); } try { runningStatus = p.waitFor(); if (s_right != "") { s_right = s_right.replaceAll("\t", " "); s_right = s_right.replaceAll(" +", " "); s_right = s_right.replaceAll("\n", " "); producer.send(new ProducerRecord<String, String>(TOPIC, s_right)).get(); System.out.println(s_right); producer.close(); } } catch (InterruptedException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号