Spark读取txt , 并结构化后执行 SQL操作
1.准备 idea , 配置好scala ,需要有 Spark sql包 !注意:如果自己Spark能跑 ,就不要复制我的POM了,代码能直接用.

---------------贴一下POM , 我用的是Spark版本是 2.4.3, Spark_core以及sql是2.11
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.alpha3</groupId> <artifactId>Scala008</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <!-- https://mvnrepository.com/artifact/org.scala-lang/scala-library --> <!-- 以下dependency都要修改成自己的scala,spark,hadoop版本--> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.11.12</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.2.0</version> <exclusions> <exclusion> <artifactId>hadoop-common</artifactId> <groupId>org.apache.hadoop</groupId> </exclusion> <exclusion> <artifactId>netty-all</artifactId> <groupId>io.netty</groupId> </exclusion> </exclusions> </dependency> <!--<!– https://mvnrepository.com/artifact/org.apache.hbase/hbase-server –>--> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.2.0</version> <exclusions> <exclusion> <artifactId>hadoop-client</artifactId> <groupId>org.apache.hadoop</groupId> </exclusion> <exclusion> <artifactId>netty-all</artifactId> <groupId>io.netty</groupId> </exclusion> <exclusion> <artifactId>hadoop-common</artifactId> <groupId>org.apache.hadoop</groupId> </exclusion> </exclusions> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.4.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql-kafka-0-10 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.6</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>0.13.0</version> </dependency> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> </dependencies> <build> <!--程序主目录,按照自己的路径修改,如果有测试文件还要加一个testDirectory--> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <!--<transformers>--> <!--<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">--> <!--<mainClass></mainClass>--> <!--</transformer>--> <!--</transformers>--> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <useUniqueVersions>false</useUniqueVersions> <classpathPrefix>lib/</classpathPrefix> <!--修改为自己的包名.类名,右键类->copy reference--> <mainClass>com.me.Scala008</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build> </project>
2. 第二步 ,创建伴生类 , 何谓伴生类 , 就是此类可以直接执行main方法
import org.apache.spark.sql.types.{StringType, StructField, StructType} import org.apache.spark.sql.{Row, SparkSession} object Spark_File_to_SQL { def main(args: Array[String]): Unit = { import org.apache.log4j.{Level, Logger} Logger.getLogger("org").setLevel(Level.OFF) val ss = SparkSession .builder() .appName("Scala009") .master("local") .getOrCreate() //获取 SparkContext val sc = ss.sparkContext val rdd = sc.textFile("D:\\aa.txt") val mapRDD= rdd.map(line=>Row(line.split(" ")(0),line.split(" ")(1))) val sf1=new StructField("ip",StringType,true) //这里是列1 信息是 IP val sf2=new StructField("user",StringType,true) //这里是列2 信息是user val table_sch=new StructType(Array(sf1,sf2)) //生成表结构 , 由两列叫IP和user的列组成的表 ,可以为空 val df=ss.createDataFrame(mapRDD,table_sch) //用mapRDD的分列数据去映射到 结构表里面,生成具有列信息的表 df.createTempView("cyber") //创建视图 cyber ss.sql("select * from cyber").show() //打印视图(表) println("执行完毕") } }
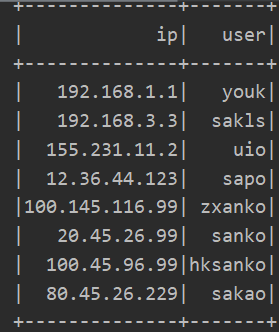
运行结果
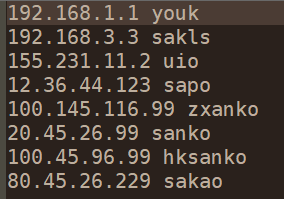
PS:我在D:\\aa.txt 目录下新建了文本文档 , 组合方式为 IP+ 空格 +用户名
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号