
RAID与其在Linux上的实现
参考资料:
本文所使用的图片来源于互联网,若有侵权,烦请联系,谢谢。
简介
RAID出现的目的是为了数据的冗余,或者性能的提升,或者两者兼顾。早期想实现这样的功能,可能需要购买一些基于大型机(mainframe)的设备,但是价格过于昂贵,后来就有些人发明了RAID技术将多块廉价的磁盘组合在了一起,实现了和大型机设备同等的功能。
RAID,早期的全称是冗余廉价磁盘阵列(Redundant Array of Inexpensive Disks),主要是相比于以往的昂贵的SLED(Single Large Expensive Disk),后改名为冗余独立磁盘阵列(Redundant Array of Independent Disks),毕竟现在的RAID控制卡也已经不便宜了。
基于不同级别的冗余和性能要求,RAID有不同的级别(level)。不同的级别也决定了可靠性(reliability)、可用性(availability)、性能(performance)和容量(capacity)的不同。
许多RAID级别采用了一种错误保护机制,叫做奇偶校验(parity)。大部分情况使用的是异或运算(XOR),不过RAID 6则使用了两种独立的奇偶校验方法。
不同的RAID级别,使用不同的数字来表示,例如RAID 0、RAID 1等等。
RAID级别按照种类划分有标准(standard)级别、嵌套/混合(nested/hybrid)级别和非标准(non-standard)级别。RAID级别是由SINA(Storage Networking Industry Association)组织所定义的。
接下来我们就来一一介绍这几种RAID。
标准级别
RAID 0
基于striping方式(data striping是一种切割逻辑上连续数据的技术,例如切割文件,使得连续的片段可以被存储在不同的物理存储设备上。)来组织数据,不具备镜像(mirror,即数据冗余)和校验的功能。如图所示。

一个文件会被切割成多个block,假设有8个,有A1~A8表示,那么会依次存入阵列中的每个磁盘当中。
优点:
- 读写性能提升,理论上有n块磁盘,就可以带来n倍的性能提升,因为读写是并行的。
- 存储容量提升,阵列总容量为n块磁盘之和。如果磁盘的容量不是相等的,则总容量为n倍的最小磁盘容量。其他RAID级别遇到磁盘容量不同的时候,也是以最小磁盘容量为准。接下来我们假设所有RAID的磁盘容量都是相同的,一般在生产环境中,阵列中的磁盘的容量、型号等也都会是一模一样的。
缺点:
- 没有数据冗余能力,1块硬盘损坏则整个RAID无法使用,数据全部丢失。并且随着阵列中磁盘数量的增加,发生损坏的概率就越大。
- 没有校验能力,无法基于校验码进行数据恢复。
其他:
- 至少需要2块硬盘。
RAID 1
基于镜像(mirroring)的方式,当写入数据的时候,会同时写入每个磁盘设备。

优点:
- 具备数据冗余能力,只要阵列中还有一块硬盘处于工作状态,那么整个阵列就依然可用。
- 读性能提升,如果RAID控制器足够强大,则读性能可接近于RAID 0,不过实际实现中,应该无法达到。
缺点:
- 写性能下降。由于同一个block的数据需要被写入阵列中的每一个磁盘中,因此写性能下降。磁盘数越多,写性能下降越多。最慢的磁盘会限制整个阵列的写性能。
- 没有校验能力,无法基于校验码进行数据恢复。
其他:
- 存储容量保持不变。总容量为单块磁盘容量。
- 至少需要2块磁盘。
RAID 2
数据的组织方式类似RAID 0,通过striping技术以位(bit)为单位将数据切割至多块磁盘上。使用汉明码(hamming-code)作为校验码,具备数据恢复能力,但是需要多块磁盘作为校验盘。所有磁盘的主轴旋转是同步的。
目前已被弃用!!!

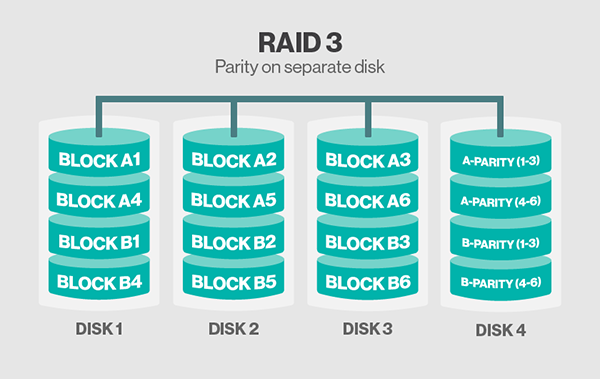
RAID 3
类似RAID 2。区别在于RAID 3是基于字节(byte)级别,使用非汉明码的校验码,所以校验码只需存储在一块磁盘中。
目前已被弃用!!!
RAID 4
类似于RAID 2和3。区别在于RAID 4是基于块(block)级别,校验码存储在一块磁盘上。RAID 4相对于2和3的最大优点在于I/O并行性(parallelism):在2和3中,一次简单的读操作会从阵列中的所有磁盘读取数据,而4则不需要。
由于只有一块校验盘,每次写入数据的时候需要计算校验码,随着磁盘数的增加,校验盘的性能会成为整个阵列的瓶颈。
目前RAID 4的实现大部分已被私有技术RAID DP所取代,RAID DP使用了两块校验盘。
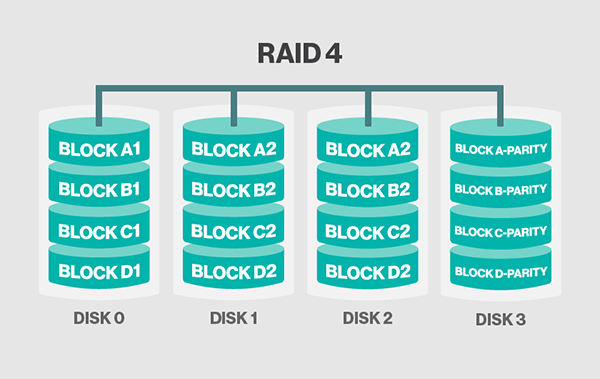
注意:图片可能有点错误,DISK 2中存储的应该是BLOCK A3、B3、C3和D3的数据。
优点:
- 读写性能提升,读性能理论为n倍的数据盘,写性能理论小于n倍的数据盘且随着数据盘的增加,写性能越来越受制于校验盘。
- 具有数据恢复能力。
- 存储容量提升,为磁盘总容量减去校验盘容量(n-1)。
缺点:
- 无镜像能力,虽然存在数据恢复能力,但是数据盘损坏后,基于校验码恢复数据会有额外的计算开销。
- 校验盘瓶颈问题。
其他:
- 至少需要3块磁盘。
RAID 5
类似于RAID 4,RAID 5基于块(block)级别切割数据至多个磁盘,同样具备校验码。但是,最大的区别在于RAID 5的校验码不是存放在专门的磁盘上,而是分布式地存储在阵列中的每个磁盘中,这就解决了RAID 4的写性能受制于校验盘的问题了。截止目前,涉及校验的RAID,它们的校验码都是只计算一次并保留一份,这也叫做“单校验概念”(single-parity concept)。像这类单校验的设计,当阵列越来越庞大的时候,容易受到系统故障的影响,这里的系统故障指的是磁盘损坏阵列重建(rebuild)时间以及重建期二次磁盘损坏几率。详见:Increasing rebuild time and failure probability
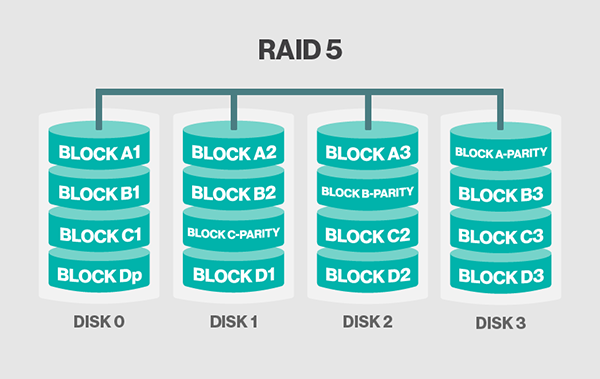
优点:
- 读写性能提升,理论为n倍的磁盘,解决了RAID 4中的校验盘瓶颈问题。
- 具有数据恢复能力。
- 存储容量提升,为磁盘总容量减去校验码占用容量(n-1),校验码占用的容量约为一个磁盘容量。
缺点:
- 无镜像能力,虽然存在数据恢复能力,但是数据盘损坏后,基于校验码恢复数据会有额外的计算开销。
- 单校验问题,此前的所有具备校验能力的RAID亦均有此问题。
其他:
- 至少需要3块磁盘。
RAID 6
类似于RAID 5,RAID 6基于块(block)级别切割数据至多个磁盘,具备分布式校验码。只不过是使用了双校验码(double-parity)机制。双校验支持损坏至多2块磁盘。这使得更大的RAID阵列更加实用,尤其对于高可用系统,因为大容量的阵列需要更长的时间重建。至少需要4块磁盘。和RAID 5一样,单块磁盘故障会降低整体阵列性能,直到故障盘被替换。如果磁盘的容量和阵列的容量越大的话,那么越应该考虑使用RAID 6来替代RAID 5。RAID 10同样也最小化了这些问题。

优点:
- 读写性能提升,写性能可能稍微逊色于RAID 5,因为要计算2种校验码。
- 具备数据恢复能力,允许损坏至多2块磁盘。
- 存储容量提升,n-1。
- 新增双校验机制,解决单校验的问题,此类设计更适合支持大容量阵列并提高其可用性。
缺点:
- 必须牺牲2块磁盘的容量存放校验码。
- 无镜像能力,虽然存在数据恢复能力,但是数据盘损坏后,基于校验码恢复数据会有额外的计算开销。不过双校验应该可以加快数据恢复的时间。
其他:
- 至少需要4块磁盘。
嵌套级别
RAID中的每个元素(组成成分),可以是独立磁盘,也可以是一个RAID阵列。对于后者,我们称之为RAID嵌套。
RAID 01
也叫作RAID 0+1或者RAID 0&1,先将磁盘制作成RAID 0,再将每个RAID 0组合成RAID 1。如图所示。
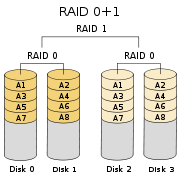
任何一块磁盘损坏都会导致其中一个stripe(基于striping技术的RAID 0,也可叫stripe)不可用,此时整个RAID 01阵列实际上就降级为RAID 0阵列了。该阵列相比RAID 10在重建期会遭遇更高的风险,因为它需要读取剩下的stripe中的所有磁盘的所有数据而不是其中一块盘上的所有数据,增加了URE(Unrecoverable Rear Error)的概率并且明显扩大了重建窗口。
至少需要4块磁盘。可以采用更多的磁盘,但是这意味着磁盘故障率也会随之增加,如果阵列只有2个stripe,并且刚好每个stripe各损坏1块磁盘,那么整个阵列就完了。
按照此图示的存储容量为n/2。
因此,RAID 01是不好的,不建议使用。建议使用RAID 10来替代它!!!
RAID 10
也叫作RAID 1+0或者RAID 1&0,先将磁盘制作成RAID 1,再将每个RAID 1组合成RAID 0。如图所示。
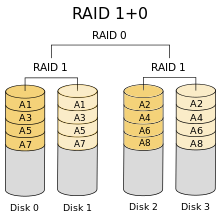
这种阵列相对RAID 01可以承受更多的设备损坏,特别是在单个镜像卷中的磁盘数量较多的情况下。
按照此图示的存储容量为n/2。
非RAID架构
关于RAID的常用级别基本已经说明完毕,除了以上几个RAID级别,还有一些并不是基于RAID技术但是也可以将磁盘数据集合起来的技术,这些技术通常只是简单地将磁盘堆叠起来使用而已,并不一定具备像RAID一样的数据冗余和性能提升的功能。
- JBOD:Just a Bunch Of Disks。
- SPAN or BIG:字面意义,非缩略词。
- MAID:Massive Array of Idle Drives。
详见:Non-RAID drive architectures
实现
RAID的实现主要有两种,一种是基于硬件俗称硬RAID,另一种是基于软件俗称软RAID。
硬RAID需要硬件(RAID卡,即RAID控制器)支持,一般是在OS启动之前,在BIOS中进行RAID的相关配置,并且在OS启动之后,会有对应RAID卡厂商的私有软件工具可以进行配置。因为本人没有相关硬RAID配置经验以及这只是实验环境,因此没有硬RAID相关实现的介绍。
软RAID的实现方式也有很多种,一般是基于操作系统的某些特性,例如基于Linux内核的md(Multiple Device)或者OpenBSD的softraid。
本文主要阐述如何基于Linux操作系统实现软RAID。
mdadm
基于Linux的md实现的命令是mdadm,它所支持的RAID级别:LINEAR(类似JBOD)、RAID 0、RAID 1、RAID 4、RAID 5、RAID 6和RAID 10。
OS:CentOS 7.5
mdadm:v4.0
我们的目标是,使用4块1GB的磁盘,创建RAID 5阵列,其中3块作为有效(active)盘,1块作为备用(spare)盘。
创建4块磁盘,分区,文件系统类型为Linux的RAID(ID:fd)。
[root@C7 ~]# fdisk -l | grep -i "raid" /dev/sdb1 2048 2097151 1047552 fd Linux raid autodetect /dev/sdc1 2048 2097151 1047552 fd Linux raid autodetect /dev/sde1 2048 2097151 1047552 fd Linux raid autodetect /dev/sdd1 2048 2097151 1047552 fd Linux raid autodetect
查看内核识别到的分区信息,确保我们刚才所创建的四个磁盘的分区已经被内核识别。
[root@C7 ~]# cat /proc/partitions major minor #blocks name 8 0 20971520 sda 8 1 1048576 sda1 8 2 19921920 sda2 8 16 1048576 sdb 8 17 1047552 sdb1 8 32 1048576 sdc 8 33 1047552 sdc1 11 0 4365312 sr0 8 64 1048576 sde 8 65 1047552 sde1 8 48 1048576 sdd 8 49 1047552 sdd1 253 0 17821696 dm-0 253 1 2097152 dm-1
如果未识别到,则使用partprobe告知内核。警告信息可以忽略。
[root@C7 ~]# partprobe Warning: Unable to open /dev/sr0 read-write (Read-only file system). /dev/sr0 has been opened read-only.
创建磁盘阵列。
[root@C7 ~]# mdadm -C /dev/md0 -l 5 -n 3 -x 1 /dev/sd{b,c,d,e}1 mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.
查看阵列状态信息
方法一
[root@C7 ~]# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid5 sdd1[4] sde1[3](S) sdc1[1] sdb1[0] 2091008 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
阵列创建的过程需要时间,例如写入RAID元数据之类的,想动态查看的话,可以通过watch命令
[root@C7 ~]# watch -n 1 cat /proc/mdstat
方法二
[root@C7 ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Apr 3 14:15:55 2019 Raid Level : raid5 # RAID级别 Array Size : 2091008 (2042.00 MiB 2141.19 MB) # 4块磁盘,各1GB,1块备用盘,还有1块盘的容量为校验码,因此阵列可用容量为2GB。 Used Dev Size : 1045504 (1021.00 MiB 1070.60 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Wed Apr 3 14:16:00 2019 State : clean # 阵列的状态,clean表示干净状态,即阵列处于健康工作状态 Active Devices : 3 Working Devices : 4 Failed Devices : 0 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Consistency Policy : resync Name : C7:0 (local to host C7) UUID : ebf794e8:8f01958a:f004744b:7be7a8cf # 系统重启后,阵列的设备名称可能不再是/dev/md0,因此可使用UUID来代替设备名称写入/etc/fstab。 Events : 18 Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 1 8 33 1 active sync /dev/sdc1 4 8 49 2 active sync /dev/sdd1 3 8 65 - spare /dev/sde1
格式化RAID设备并挂载使用
[root@C7 ~]# mkfs -t xfs /dev/md0 meta-data=/dev/md0 isize=512 agcount=8, agsize=65408 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=0, sparse=0 data = bsize=4096 blocks=522752, imaxpct=25 = sunit=128 swidth=256 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=8 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 [root@C7 ~]# mkdir /raid_data [root@C7 ~]# mount /dev/md0 /raid_data
创建一个测试的文本文件,输入一些信息。在下文标记阵列中磁盘为faulty状态时,我们可以通过测试此文件是否内容可读取来判断RAID是否可用。
[root@C7 ~]# cat /raid_data/raid.txt this is a test file for RAID 5 !!!
手动标记阵列中的一块有效磁盘为faulty状态,并观察备用盘是否自动顶替。
[root@C7 ~]# mdadm /dev/md0 -f /dev/sdd1 mdadm: set /dev/sdd1 faulty in /dev/md0
再次查看状态会发现一些变化。
[root@C7 ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Apr 3 14:15:55 2019 Raid Level : raid5 Array Size : 2091008 (2042.00 MiB 2141.19 MB) Used Dev Size : 1045504 (1021.00 MiB 1070.60 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Wed Apr 3 14:45:28 2019 State : clean, degraded, recovering # 由于磁盘损坏了1块,且存在备用盘。备用盘自动顶替,阵列进入重建期,在重建完成前,阵列处于降级模式工作。重建完毕后,状态又会变回clean了。 Active Devices : 2 Working Devices : 3 Failed Devices : 1 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Consistency Policy : resync Rebuild Status : 65% complete # 数据重建进度。 Name : C7:0 (local to host C7) UUID : ebf794e8:8f01958a:f004744b:7be7a8cf Events : 30 Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 1 8 33 1 active sync /dev/sdc1 3 8 65 2 spare rebuilding /dev/sde1 4 8 49 - faulty /dev/sdd1
待阵列重建完毕,再标记一块磁盘为faulty状态。
[root@C7 ~]# mdadm /dev/md0 -f /dev/sdc1 mdadm: set /dev/sdc1 faulty in /dev/md0
此时我们的阵列,就只能工作于降级模式而无法恢复clean了。
[root@C7 ~]# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Apr 3 14:15:55 2019 Raid Level : raid5 Array Size : 2091008 (2042.00 MiB 2141.19 MB) Used Dev Size : 1045504 (1021.00 MiB 1070.60 MB) Raid Devices : 3 Total Devices : 4 Persistence : Superblock is persistent Update Time : Wed Apr 3 14:47:55 2019 State : clean, degraded Active Devices : 2 Working Devices : 2 Failed Devices : 2 Spare Devices : 0 Layout : left-symmetric Chunk Size : 512K Consistency Policy : resync Name : C7:0 (local to host C7) UUID : ebf794e8:8f01958a:f004744b:7be7a8cf Events : 45 Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 - 0 0 1 removed 3 8 65 2 active sync /dev/sde1 1 8 33 - faulty /dev/sdc1 4 8 49 - faulty /dev/sdd1
无论阵列处于重建期或者降级模式,测试文件都是可读的。
如果该阵列不使用了,那么我们应该先卸载阵列,再关闭它。
[root@C7 ~]# umount /dev/md0 [root@C7 ~]# mdadm -S /dev/md0 mdadm: stopped /dev/md0 [root@C7 ~]# mdadm -D /dev/md0 mdadm: cannot open /dev/md0: No such file or directory
关闭后,阵列设备文件消失。
总结
- 实际生产环境中,数据的完整性和性能是重要的,因此不应该使用软RAID,而应该采用硬RAID。
- 不同的RAID卡厂商的配置方式不同,万变不离其宗,了解RAID原理各级别特性比RAID实现更重要。
- 本文关于Linux上的软RAID实现只是简单阐述,切勿直接拿来在生产环境使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号