
Linux文本处理三剑客之grep
简介
grep命令,用于在一个文本文件中或者从STDIN中,根据用户给出的模式(pattern)过滤出所需要的信息。
grep以及三剑客中的另外两个工具sed和awk都是基于行处理的,它们会一行行读入数据,处理完一行之后再处理下一行。
简要语法格式如下。
grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
默认情况下,grep读取的行数据,如果整行内容中的某部分和模式相匹配的话,就会将该行内容输出。
例如,在/etc/passwd文件中找出包含“root”字符串的行。

该示例中的“root”字符串,就是模式。模式的强大之处在于它支持正则表达式。
例如,在/etc/passwd文件中找出以“root”或者“zwl”字符串开头的行。

该示例中的模式的书写就是字符串结合了正则表达式,而“^(|”字符就是正则表达式的元字符。
环境
CentOS 7.5
GNU grep 2.20
常用选项
首先我们先回顾一下语法。
grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
第一种语法是比较常用的语法,选项可以省略,如果结合管道的话,那么文件也可以省略了。上面2个示例就是使用了该种语法。
在第二种语法中,我们见到了-e和-f选项。
-e PATTERN, --regexp=PATTERN:该选项的作用在于可以指定多个模式来匹配或者当遇到模式是以“-”开始的时候起到一个保护作用。
指定多模式的语法类似如下。
grep -e 'PATTERN1' -e 'PATTERN2' FILE
从FILE中读取第一行,然后首先和PATTERN1匹配,匹配成功则显示第一行并进入下一行匹配;不成功就和PATTERN2匹配,匹配成功则显示第一行并进入下一行匹配;均不成功就进入下一行匹配。以此类推。
[root@C7 ~]# grep -e '^root' -e '^zwl' /etc/passwd

另外一个保护的功能,我暂不知是什么意思,有知道的朋友可以分享一下。
-f FILE, --file=FILE:表示模式不再在CLI中指定,而是将模式写入一个文件中,每行一个模式,然后通过-f选项读取包含模式的文件。
--help:查看帮助。罗列了大部分选项的简要描述,不过没包含元字符解释。
-V, --version:如果是向grep官方递交bug的时候,需要带上版本。
-G, --basic-regexp:将模式解释为基本正则表达式,这是grep的默认行为。
-E, --extended-regexp:将模式解释为扩展正则表达式。
-F, --fixed-strings:将模式解释为固定的字符串,即禁用正则。虽然失去了正则的功能,但是换来性能的极大提升,当遇到大文本文件的时候相当好用。
--color=auto:将被grep所匹配到的内容给予着色处理,就像上面的截图中所显示的,通过正则所匹配到的字符串会被着色。由于我使用的系统是CentOS 7,该系统上的grep启用了显示着色的别名,因此我们不使用该选项也可以显示颜色。
alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto'
然而在CentOS 6上默认是没有的,需要自行添加。
-i, --ignore-case:表示模式的匹配是忽略大小写的。
[root@C7 ~]# cat grep.txt alongdidi ALONGdidi xiamen XiaMen [root@C7 ~]# grep 'xiamen\|alongdidi' grep.txt alongdidi xiamen [root@C7 ~]# grep -i 'xiamen\|alongdidi' grep.txt alongdidi ALONGdidi xiamen XiaMen
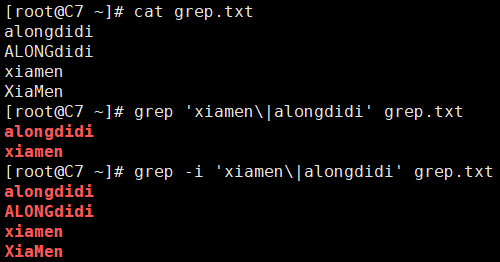
-v, --invert-match:表示反向匹配。默认是将匹配模式的行打印出来,而使用该选项的话,则是将不匹配的行打印出来。
[root@C7 ~]# cat grep.txt alongdidi ALONGdidi xiamen XiaMen [root@C7 ~]# grep -iv 'xiamen' grep.txt alongdidi ALONGdidi
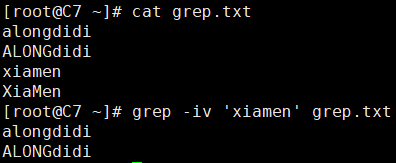
从这个示例中,我们也可以发现,--color=auto的着色,只会将模式所匹配到的内容进行着色,不匹配的不着色。
-o, --only-matching:表示仅打印出模式所匹配的字符,而不是将整行都打印出来。
[root@C7 ~]# grep '^root' /etc/passwd root:x:0:0:root:/root:/bin/bash [root@C7 ~]# grep -o '^root' /etc/passwd root
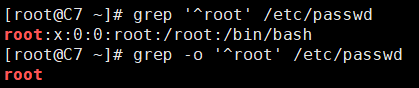
-o选项的模式匹配出来的字符串个数,不等同于文本文件中对应有那么多行匹配。
[root@C7 ~]# grep 'root' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@C7 ~]# grep -o 'root' /etc/passwd root root root root
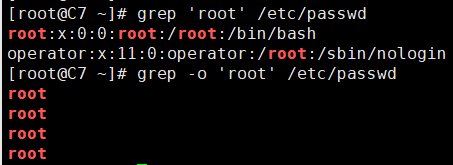
-n, --line-number:在显示出匹配的内容时,通过该选项,显示匹配模式的行在输入文件中的行号。
[root@C7 ~]# grep -n 'xiamen' grep.txt 3:xiamen

-q, --quiet, --silent:静默模式,不会输出任何信息到STDOUT,即便遇到诸如文件不存在或者文件不可读的错误情况,也不会输出。匹配成功则返回0状态码,一般用于结合$?做判断。
-A NUM, --after-context=NUM:打印匹配到的文本所在行以及其后面NUM行,NUM是一个正整数。
-B NUM, --before-context=NUM:打印匹配到的文本所在行以及其前面NUM行。
-C NUM, -NUM, --context=NUM:打印匹配到的文本所在行以及其上下NUM行。
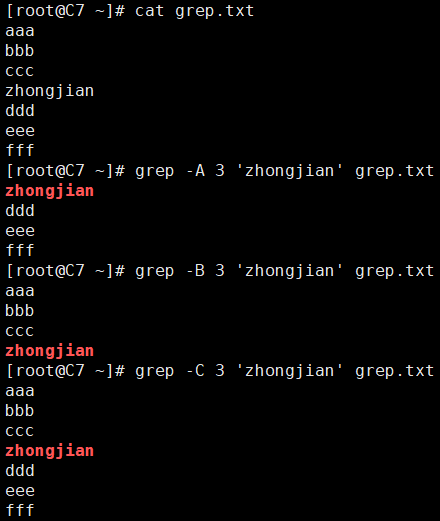
[root@C7 ~]# cat grep.txt aaa bbb ccc zhongjian ddd eee fff [root@C7 ~]# grep -A 3 'zhongjian' grep.txt zhongjian ddd eee fff [root@C7 ~]# grep -B 3 'zhongjian' grep.txt aaa bbb ccc zhongjian [root@C7 ~]# grep -C 3 'zhongjian' grep.txt aaa bbb ccc zhongjian ddd eee fff
常用选项就说到这里,基本可以满足日常需求,grep的真正强大之处在于与正则表达式的结合。
正则表达式
正则表达式可使用在grep的匹配模式当中,它由多个元字符所组成,用于匹配出用户所期望的特定的字符串。
因此正则表达式的重点就在于元字符。
元字符
字符匹配
.:匹配任意单个字符。
[]:匹配任意范围内的单个字符,这里的范围,支持类似glob的机制(详见man 7 glob),支持字符类(character classes),如下。
[:alnum:]:字母和数字。
[:alpha:]:字母。
[:digit:]:数字。
[:lower:]:小写字母。
[:upper:]:大写字母。
[:space:]:空白字符,例如空格或者制表符。
[:punct:]:标点符号。
[:graph:]:非空字符。
等等。
[^]:匹配任意范围外的单个字符。
次数匹配
*:匹配前面的字符任意次(0次、1次或者多次)。一般是结合“.”使用,例如“.*”表示匹配任意长度的任意字符,即等同于glob中的通配符“*”。
?:匹配前面的字符0次或1次,即前面的字符可有可无。
+:匹配前面的字符1次或多次,即前面的字符至少出现1次。
{m}:匹配前面的字符m次。
{m,n}:匹配前面的字符,至少m次,至多n次。
{0,n}或者{,n}:匹配前面的字符,至多n次。
{m,}:匹配前面的字符,至少m次。
位置锚定
^:锚定行首,表示模式必须出现在行的最左侧。
$:锚定行尾,表示模式必须出现在行的最右侧。
^PATTERN$:整行锚定,表示模式必须刚好匹配整行的内容。
^$:匹配空行。
\<或者\b:锚定词首。
\>或者\b:锚定词尾。
一般是不使用\b,因为它不能明确表示词首或者词尾。
\<PATTERN\>:整词锚定。
分组及引用
():表示分组,可用于将某个模式或字符串包裹,用于次数匹配,例如“xy+”和“(xy)+”的区别。不过主要的作用是用于后向引用。
\n:表示引用,n是一个正整数,表示引用第几个分组的内容。例如“^(root).*\1$”。分组之后可以不引用,而如果涉及了引用,那么必定存在分组。
基本正则与扩展正则
正则表达式又分为基本正则表达式(BRE)和扩展正则表达式(ERE)。
它们的区别在于元字符支持的不同。ERE在包含了BRE的元字符的基础上又进行了扩展。
BRE的元字符:.、[]、[^]、*、^、$、\b、\<、\>、\n(引用)。
ERE的元字符:?、+、{}、()、|。
对于Linux中的GNU grep工具来说,两种正则是都支持的,区别在于元字符的书写方式不同。
默认情况下,grep命令支持的是BRE,因此在书写BRE元字符的时候不改变,在书写ERE元字符的时候,需要在元字符前面加上转义字符“\”。
如果通过-E选项开启支持ERE的话,那么在书写BRE和ERE元字符的时候,都不需要改变。如下所示。
# grep "^\(root\)\?" /PATH/TO/FILE # grep -E "^(root)?" /PATH/TO/FILE
因此可以每次都使用-E选项来书写模式。
在开启-E选项支持ERE的前提下,如果想要匹配ERE的元字符自身,例如想匹配一个问号“?”,那么就需要加上转义“\?”。
仅仅解释每个元字符的作用,不好理解,通过一些示例来体会一下。
示例
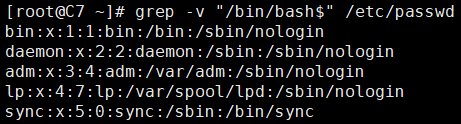
1、找出/etc/passwd中不以“/bin/bash”结尾的行。
[root@C7 ~]# grep -v "/bin/bash$" /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync ...
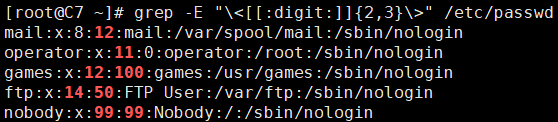
2、找出/etc/passwd中含有两位数或三位数作为字段信息的行。
[root@C7 ~]# grep -E "\<[[:digit:]]{2,3}\>" /etc/passwd mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin ...
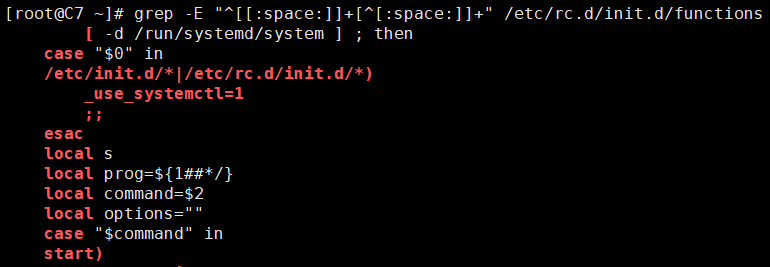
3、找出/etc/rc.d/init.d/functions中,至少一个空白开头并且后面跟着至少一个非空白字符的行。
[root@C7 ~]# grep -E "^[[:space:]]+[^[:space:]]+" /etc/rc.d/init.d/functions
4、找出netstat -atn命令结果中以LISTEN后跟任意个空白字符的行。
[root@C7 ~]# netstat -atn | grep "LISTEN[[:space:]]*" tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN tcp6 0 0 :::111 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:631 :::* LISTEN tcp6 0 0 ::1:25 :::* LISTEN
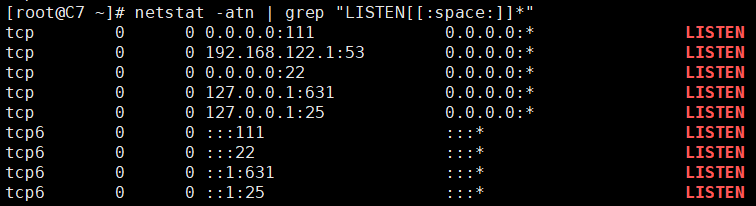
5、找出示例文件中,前后都包like或者love的行。
[root@C7 ~]# cat test.txt He likes his lover. He loves his lover. She likes her liker. She lovers her liker. [root@C7 ~]# grep -E "(l..e).*\1" test.txt He loves his lover. She likes her liker.
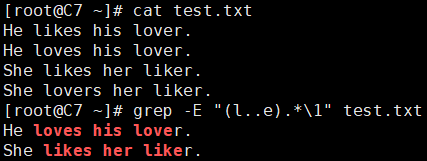
6、找出/proc/meminfo文件中,所有以Mem或者mem开头的行。
[root@C7 ~]# grep -E '^[Mm]em' /proc/meminfo MemTotal: 997980 kB MemFree: 168996 kB MemAvailable: 354096 kB [root@C7 ~]# grep -E '^(M|m)em' /proc/meminfo MemTotal: 997980 kB MemFree: 168996 kB MemAvailable: 354096 kB
7、查找/etc/passwd中root、postfix和haimianbb用户的相关信息。
[root@C7 ~]# grep -E "^(root|postfix|haimianbb)\>" /etc/passwd root:x:0:0:root:/root:/bin/bash postfix:x:89:89::/var/spool/postfix:/sbin/nologin haimianbb:x:1004:1005::/home/haimianbb:/bin/bash

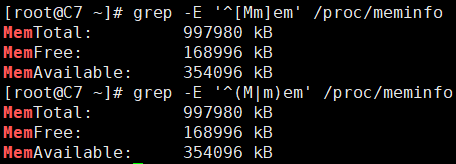
8、找出/etc/init.d/functions文件中的函数名(可以含括号)。
留意函数名的特征(数字字母下划线)。留意-o选项的作用。启用ERE之后,()有分组的含义,因此如果模式要匹配出字面意义上的()就需要使用转义“\(\)”。
[root@C7 ~]# grep -Eo "[_[:alnum:]]+\(\)" /etc/init.d/functions checkpid() __kill_pids_term_kill_checkpids() __kill_pids_term_kill() __pids_var_run() __pids_pidof() daemon() ...
9、通过grep实现basename命令的功能。
[root@C7 ~]# basename /etc/init.d/functions functions [root@C7 ~]# basename /etc/init.d/functions/ functions [root@C7 ~]# echo "/etc/init.d/functions" | grep -Eo "[^/]+/?$" | grep -Eo "[[:alnum:]]+" functions [root@C7 ~]# echo "/etc/init.d/functions/" | grep -Eo "[^/]+/?$" | grep -Eo "[[:alnum:]]+" functions
10、通过grep实现dirname命令的功能。
不知道如何实现,期待各位博友的分享。
11、找出ifconfig命令结果中,以独立单词形式存在的1000以内的数字。
[root@C7 ~]# ifconfig | grep -E "\<([1-9]|[1-9][0-9]|[1-2][0-9][0-9])\>" [root@C7 ~]# ifconfig | grep -Eo "\<([1-9]|[1-9][0-9]|[1-2][0-9][0-9])\>"

12、找出ifconfig命令结果中的IP地址。
这种判断方式比较鲁莽,并没有针对IP地址的特性,例如每个字节的最大十进制数是255。
[root@C7 ~]# ifconfig | grep -Eo "[[:digit:]]{,3}(\.[[:digit:]]{,3}){3}" 192.168.17.7 255.255.255.0 192.168.17.255 127.0.0.1 255.0.0.0 192.168.122.1 255.255.255.0 192.168.122.255
13、查找/etc/passwd中,用户名等同于shell名称的用户信息。
[root@C7 ~]# grep -E "(^[[:alnum:]-]+\>).*\1$" /etc/passwd sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt bash:x:1005:1006::/home/bash:/bin/bash nologin:x:1008:1009::/home/nologin:/sbin/nologin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号