Hadoop+Hbase分布式集群架构“完全篇”

本文收录在Linux运维企业架构实战系列
前言:本篇博客是博主踩过无数坑,反复查阅资料,一步步搭建,操作完成后整理的个人心得,分享给大家~~~
1、认识Hadoop和Hbase
1.1 hadoop简单介绍
Hadoop是一个使用java编写的Apache开放源代码框架,它允许使用简单的编程模型跨大型计算机的大型数据集进行分布式处理。Hadoop框架工作的应用程序可以在跨计算机群集提供分布式存储和计算的环境中工作。Hadoop旨在从单一服务器扩展到数千台机器,每台机器都提供本地计算和存储。
1.2 Hadoop架构
Hadoop框架包括以下四个模块:
- Hadoop Common:这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的必要Java文件和脚本。
- Hadoop YARN:这是作业调度和集群资源管理的框架。
- Hadoop分布式文件系统(HDFS):提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop MapReduce: 这是基于YARN的大型数据集并行处理系统。
我们可以使用下图来描述Hadoop框架中可用的这四个组件。

自2012年以来,术语“Hadoop”通常不仅指向上述基本模块,而且还指向可以安装在Hadoop之上或之外的其他软件包,例如Apache Pig,Apache Hive,Apache HBase,Apache火花等
1.3 Hadoop如何工作?
(1)阶段1
用户/应用程序可以通过指定以下项目向Hadoop(hadoop作业客户端)提交所需的进程:
- 分布式文件系统中输入和输出文件的位置。
- java类以jar文件的形式包含了map和reduce功能的实现。
- 通过设置作业特定的不同参数来进行作业配置。
(2)阶段2
然后,Hadoop作业客户端将作业(jar /可执行文件等)和配置提交给JobTracker,JobTracker负责将软件/配置分发到从站,调度任务和监视它们,向作业客户端提供状态和诊断信息。
(3)阶段3
不同节点上的TaskTrackers根据MapReduce实现执行任务,并将reduce函数的输出存储到文件系统的输出文件中。
1.4 Hadoop的优点
- Hadoop框架允许用户快速编写和测试分布式系统。它是高效的,它自动分配数据并在机器上工作,反过来利用CPU核心的底层并行性。
- Hadoop不依赖硬件提供容错和高可用性(FTHA),而是Hadoop库本身被设计为检测和处理应用层的故障。
- 服务器可以动态添加或从集群中删除,Hadoop继续运行而不会中断。
- Hadoop的另一大优点是,除了是开放源码,它是所有平台兼容的,因为它是基于Java的。
1.5 HBase介绍
Hbase全称为Hadoop Database,即hbase是hadoop的数据库,是一个分布式的存储系统。Hbase利用Hadoop的HDFS作为其文件存储系统,利用Hadoop的MapReduce来处理Hbase中的海量数据。利用zookeeper作为其协调工具。
1.6 HBase体系架构
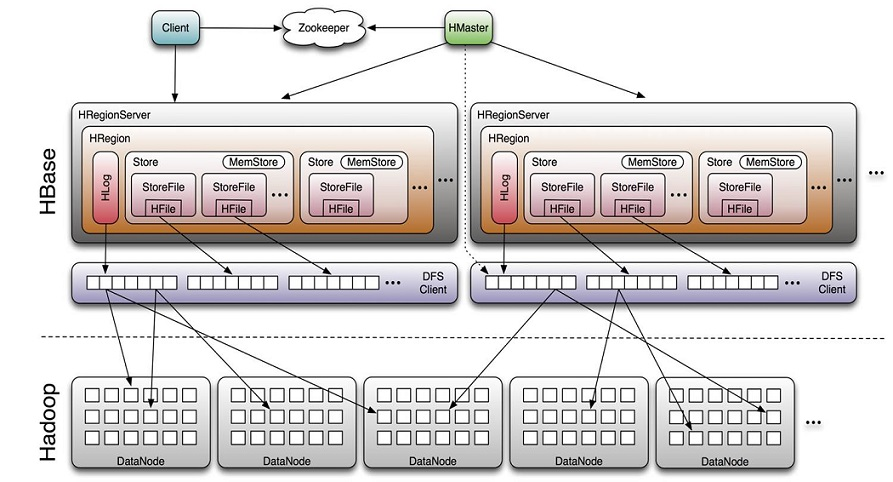
Client
- 包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
- 保证任何时候,集群中只有一个master
- 存贮所有Region的寻址入口。
- 实时监控Region server的上线和下线信息。并实时通知Master
- 存储HBase的schema和table元数据
Master
- 为Region server分配region
- 负责Region server的负载均衡
- 发现失效的Region server并重新分配其上的region
- 管理用户对table的增删改操作
RegionServer
- Region server维护region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
HLog(WAL log)
- HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是 HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和 region名字外,同时还包括sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系 统中sequence number。
- HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的 KeyValue
Region
- HBase自动把表水平划分成多个区域(region),每个region会保存一个表 里面某段连续的数据;每个表一开始只有一个region,随着数据不断插 入表,region不断增大,当增大到一个阀值的时候,region就会等分会 两个新的region(裂变);
- 当table中的行不断增多,就会有越来越多的region。这样一张完整的表 被保存在多个Regionserver上。
Memstore 与 storefile
- 一个region由多个store组成,一个store对应一个CF(列族)
- store包括位于内存中的memstore和位于磁盘的storefile写操作先写入 memstore,当memstore中的数据达到某个阈值,hregionserver会启动 flashcache进程写入storefile,每次写入形成单独的一个storefile
- 当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 major compaction),在合并过程中会进行版本合并和删除工作 (majar),形成更大的storefile。
- 当一个region所有storefile的大小和超过一定阈值后,会把当前的region 分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
- 客户端检索数据,先在memstore找,找不到再找storefile
- HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表 示不同的HRegion可以分布在不同的HRegion server上。
- HRegion由一个或者多个Store组成,每个store保存一个columns family。
- 每个Strore又由一个memStore和0至多个StoreFile组成。
2、安装搭建hadoop
2.1 配置说明
本次集群搭建共三台机器,具体说明下:
| 主机名 | IP | 说明 |
| hadoop01 | 192.168.10.101 | DataNode、NodeManager、ResourceManager、NameNode |
| hadoop02 | 192.168.10.102 | DataNode、NodeManager、SecondaryNameNode |
| hadoop03 | 192.168.10.106 | DataNode、NodeManager |
2.2 安装前准备
2.2.1 机器配置说明
$ cat /etc/redhat-release CentOS Linux release 7.3.1611 (Core) $ uname -r 3.10.0-514.el7.x86_64
注:本集群内所有进程均由clsn用户启动;要在集群所有服务器都进行操作。
2.2.2 关闭selinux、防火墙
[along@hadoop01 ~]$ sestatus
SELinux status: disabled
[root@hadoop01 ~]$ iptables -F
[along@hadoop01 ~]$ systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
2.2.3 准备用户
$ id along uid=1000(along) gid=1000(along) groups=1000(along)
2.2.4 修改hosts文件,域名解析
$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.101 hadoop01 192.168.10.102 hadoop02 192.168.10.103 hadoop03
2.2.5 同步时间
$ yum -y install ntpdate $ sudo ntpdate cn.pool.ntp.org
2.2.6 ssh互信配置
(1)生成密钥对,一直回车即可
[along@hadoop01 ~]$ ssh-keygen
(2)保证每台服务器各自都有对方的公钥
---along用户 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 127.0.0.1 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop01 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop03 ---root用户 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 127.0.0.1 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop01 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02 [along@hadoop01 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop03
注:要在集群所有服务器都进行操作
(3)验证无秘钥认证登录
[along@hadoop02 ~]$ ssh along@hadoop01 [along@hadoop02 ~]$ ssh along@hadoop02 [along@hadoop02 ~]$ ssh along@hadoop03
2.3 配置jdk
在三台机器上都需要操作
[root@hadoop01 ~]# tar -xvf jdk-8u201-linux-x64.tar.gz -C /usr/local [root@hadoop01 ~]# chown along.along -R /usr/local/jdk1.8.0_201/ [root@hadoop01 ~]# ln -s /usr/local/jdk1.8.0_201/ /usr/local/jdk [root@hadoop01 ~]# cat /etc/profile.d/jdk.sh export JAVA_HOME=/usr/local/jdk PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH [root@hadoop01 ~]# source /etc/profile.d/jdk.sh [along@hadoop01 ~]$ java -version java version "1.8.0_201" Java(TM) SE Runtime Environment (build 1.8.0_201-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
2.4 安装hadoop
[root@hadoop01 ~]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz [root@hadoop01 ~]# tar -xvf hadoop-3.2.0.tar.gz -C /usr/local/ [root@hadoop01 ~]# chown along.along -R /usr/local/hadoop-3.2.0/ [root@hadoop01 ~]# ln -s /usr/local/hadoop-3.2.0/ /usr/local/hadoop
3、配置启动hadoop
3.1 hadoop-env.sh 配置hadoop环境变量
[along@hadoop01 ~]$ cd /usr/local/hadoop/etc/hadoop/
[along@hadoop01 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
3.2 core-site.xml 配置HDFS
[along@hadoop01 hadoop]$ vim core-site.xml
<configuration>
<!-- 指定HDFS默认(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
</configuration>
[root@hadoop01 ~]# mkdir /data/hadoop
3.3 hdfs-site.xml 配置namenode
[along@hadoop01 hadoop]$ vim hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
[root@hadoop01 ~]# mkdir /data/hadoop/name -p
[root@hadoop01 ~]# mkdir /data/hadoop/datanode -p
3.4 mapred-site.xml 配置框架
[along@hadoop01 hadoop]$ vim mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
3.5 yarn-site.xml 配置resourcemanager
[along@hadoop01 hadoop]$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
</configuration>
3.6 配置masters & slaves
[along@hadoop01 hadoop]$ echo 'hadoop02' >> /usr/local/hadoop/etc/hadoop/masters [along@hadoop01 hadoop]$ echo 'hadoop03 hadoop01' >> /usr/local/hadoop/etc/hadoop/slaves
3.7 启动前准备
3.7.1 准备启动脚本
启动脚本文件全部位于 /usr/local/hadoop/sbin 文件夹下:
(1)修改 start-dfs.sh stop-dfs.sh 文件添加:
[along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/start-dfs.sh [along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/stop-dfs.sh HDFS_DATANODE_USER=along HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=along HDFS_SECONDARYNAMENODE_USER=along
(2)修改start-yarn.sh 和 stop-yarn.sh文件添加:
[along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/start-yarn.sh [along@hadoop01 ~]$ vim /usr/local/hadoop/sbin/stop-yarn.sh YARN_RESOURCEMANAGER_USER=along HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=along
3.7.2 授权
[root@hadoop01 ~]# chown -R along.along /usr/local/hadoop-3.2.0/ [root@hadoop01 ~]# chown -R along.along /data/hadoop/
3.7.3 配置hadoop命令环境变量
[root@hadoop01 ~]# vim /etc/profile.d/hadoop.sh [root@hadoop01 ~]# cat /etc/profile.d/hadoop.sh export HADOOP_HOME=/usr/local/hadoop PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
3.7.4 集群初始化
[root@hadoop01 ~]# vim /data/hadoop/rsync.sh
#在集群内所有机器上都创建所需要的目录
for i in hadoop02 hadoop03
do
sudo rsync -a /data/hadoop $i:/data/
done
#复制hadoop配置到其他机器
for i in hadoop02 hadoop03
do
sudo rsync -a /usr/local/hadoop-3.2.0/etc/hadoop $i:/usr/local/hadoop-3.2.0/etc/
done
[root@hadoop01 ~]# /data/hadoop/rsync.sh
3.8 启动hadoop集群
3.8.1 第一次启动前需要格式化,集群所有服务器都需要;
[along@hadoop01 ~]$ hdfs namenode -format ... ... /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop01/192.168.10.101 ************************************************************/ [along@hadoop02 ~]$ hdfs namenode -format /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop02/192.168.10.102 ************************************************************/ [along@hadoop03 ~]$ hdfs namenode -format /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop03/192.168.10.103 ************************************************************/
3.8.2 启动并验证集群
(1)启动namenode、datanode
[along@hadoop01 ~]$ start-dfs.sh [along@hadoop02 ~]$ start-dfs.sh [along@hadoop03 ~]$ start-dfs.sh [along@hadoop01 ~]$ jps 4480 DataNode 4727 Jps 4367 NameNode [along@hadoop02 ~]$ jps 4082 Jps 3958 SecondaryNameNode 3789 DataNode [along@hadoop03 ~]$ jps 2689 Jps 2475 DataNode
(2)启动YARN
[along@hadoop01 ~]$ start-yarn.sh [along@hadoop02 ~]$ start-yarn.sh [along@hadoop03 ~]$ start-yarn.sh [along@hadoop01 ~]$ jps 4480 DataNode 4950 NodeManager 5447 NameNode 5561 Jps 4842 ResourceManager [along@hadoop02 ~]$ jps 3958 SecondaryNameNode 4503 Jps 3789 DataNode 4367 NodeManager [along@hadoop03 ~]$ jps 12353 Jps 12226 NodeManager 2475 DataNode
3.9 集群启动成功
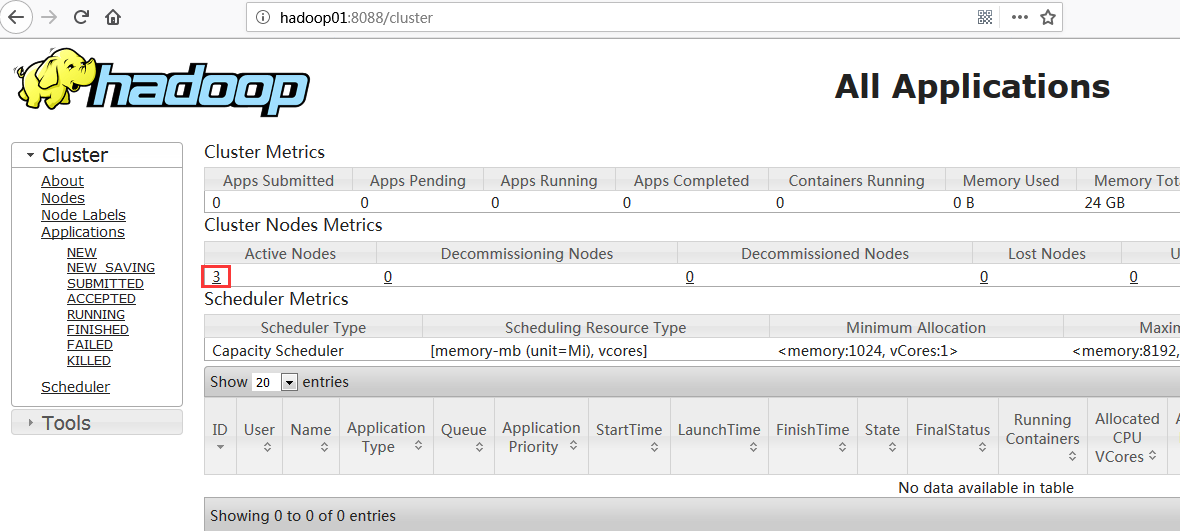
(1)网页访问:http://hadoop01:8088
该页面为ResourceManager 管理界面,在上面可以看到集群中的三台Active Nodes。
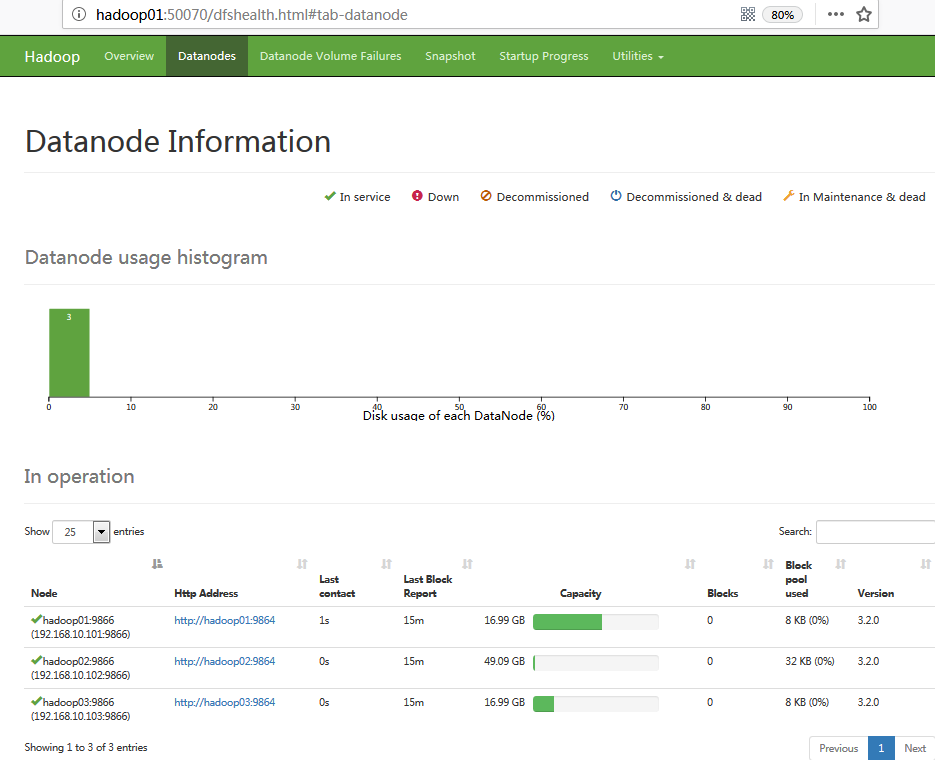
(2)网页访问:http://hadoop01:50070/dfshealth.html#tab-datanode
该页面为NameNode管理页面
到此hadoop集群已经搭建完毕!!!
4、安装配置Hbase
4.1 安装Hbase
[root@hadoop01 ~]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.4.9/hbase-1.4.9-bin.tar.gz [root@hadoop01 ~]# tar -xvf hbase-1.4.9-bin.tar.gz -C /usr/local/ [root@hadoop01 ~]# chown -R along.along /usr/local/hbase-1.4.9/ [root@hadoop01 ~]# ln -s /usr/local/hbase-1.4.9/ /usr/local/hbase
注:当前时间2018.03.08,hbase-2.1版本有问题;也可能是我配置的问题,hbase会启动失败;所以,我降级到了hbase-1.4.9版本。
4.2 配置Hbase
4.2.1 hbase-env.sh 配置hbase环境变量
[root@hadoop01 ~]# cd /usr/local/hbase/conf/ [root@hadoop01 conf]# vim hbase-env.sh export JAVA_HOME=/usr/local/jdk export HBASE_CLASSPATH=/usr/local/hbase/conf
4.2.2 hbase-site.xml 配置hbase
[root@hadoop01 conf]# vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<!-- hbase存放数据目录 -->
<value>hdfs://hadoop01:9000/hbase/hbase_db</value>
<!-- 端口要和Hadoop的fs.defaultFS端口一致-->
</property>
<property>
<name>hbase.cluster.distributed</name>
<!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<!-- zookooper 服务启动的节点,只能为奇数个 -->
<value>hadoop01,hadoop02,hadoop03</value>
</property>
<property>
<!--zookooper配置、日志等的存储位置,必须为以存在 -->
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/hbase/zookeeper</value>
</property>
<property>
<!--hbase master -->
<name>hbase.master</name>
<value>hadoop01</value>
</property>
<property>
<!--hbase web 端口 -->
<name>hbase.master.info.port</name>
<value>16666</value>
</property>
</configuration>
注:zookeeper有这样一个特性:
- 集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。
- 也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;
- 同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;
- 再多列举几个:2->0 ; 3->1 ; 4->1 ; 5->2 ; 6->2 会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper
4.2.3 指定集群节点
[root@hadoop01 conf]# vim regionservers hadoop01 hadoop02 hadoop03
5、启动Hbase集群
5.1 配置hbase命令环境变量
[root@hadoop01 ~]# vim /etc/profile.d/hbase.sh export HBASE_HOME=/usr/local/hbase PATH=$HBASE_HOME/bin:$PATH
5.2 启动前准备
[root@hadoop01 ~]# mkdir -p /data/hbase/zookeeper
[root@hadoop01 ~]# vim /data/hbase/rsync.sh
#在集群内所有机器上都创建所需要的目录
for i in hadoop02 hadoop03
do
sudo rsync -a /data/hbase $i:/data/
sudo scp -p /etc/profile.d/hbase.sh $i:/etc/profile.d/
done
#复制hbase配置到其他机器
for i in hadoop02 hadoop03
do
sudo rsync -a /usr/local/hbase-2.1.3 $i:/usr/local/
done
[root@hadoop01 conf]# chown -R along.along /data/hbase
[root@hadoop01 ~]# /data/hbase/rsync.sh
hbase.sh 100% 62 0.1KB/s 00:00
hbase.sh 100% 62 0.1KB/s 00:00
5.3 启动hbase
注:只需在hadoop01服务器上操作即可。
(1)启动
[along@hadoop01 ~]$ start-hbase.sh hadoop03: running zookeeper, logging to /usr/local/hbase/logs/hbase-along-zookeeper-hadoop03.out hadoop01: running zookeeper, logging to /usr/local/hbase/logs/hbase-along-zookeeper-hadoop01.out hadoop02: running zookeeper, logging to /usr/local/hbase/logs/hbase-along-zookeeper-hadoop02.out ... ...
(2)验证
---主hbase [along@hadoop01 ~]$ jps 4480 DataNode 23411 HQuorumPeer # zookeeper进程 4950 NodeManager 24102 Jps 5447 NameNode 23544 HMaster # hbase master进程 4842 ResourceManager 23711 HRegionServer ---2个从 [along@hadoop02 ~]$ jps 12948 HRegionServer # hbase slave进程 3958 SecondaryNameNode 13209 Jps 12794 HQuorumPeer # zookeeper进程 3789 DataNode 4367 NodeManager [along@hadoop03 ~]$ jps 12226 NodeManager 19559 Jps 19336 HRegionServer # hbase slave进程 19178 HQuorumPeer # zookeeper进程 2475 DataNode
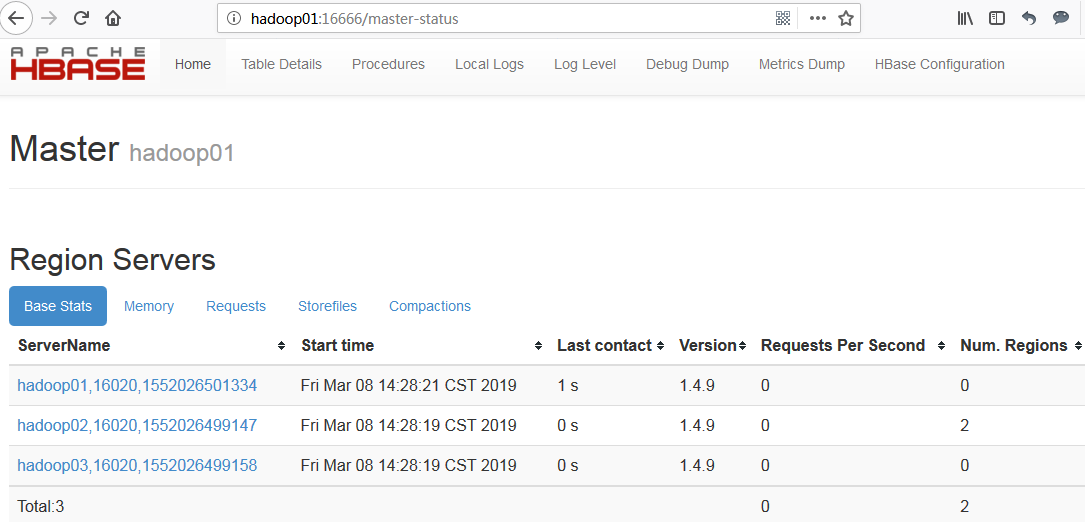
5.4 页面查看hbase状态
6、简单操作Hbase
6.1 hbase shell基本操作命令
|
名称 |
命令表达式 |
|
创建表 |
create '表名称','列簇名称1','列簇名称2'....... |
|
添加记录 |
put '表名称', '行名称','列簇名称:','值' |
|
查看记录 |
get '表名称','行名称' |
|
查看表中的记录总数 |
count '表名称' |
|
删除记录 |
delete '表名',行名称','列簇名称' |
|
删除表 |
①disable '表名称' ②drop '表名称' |
|
查看所有记录 |
scan '表名称' |
|
查看某个表某个列中所有数据 |
scan '表名称',['列簇名称:'] |
|
更新记录 |
即重写一遍进行覆盖 |
6.2 一般操作
(1)启动hbase 客户端
[along@hadoop01 ~]$ hbase shell #需要等待一些时间 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hbase-1.4.9/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell Use "help" to get list of supported commands. Use "exit" to quit this interactive shell. Version 1.4.9, rd625b212e46d01cb17db9ac2e9e927fdb201afa1, Wed Dec 5 11:54:10 PST 2018 hbase(main):001:0>
(2)查询集群状态
hbase(main):001:0> status 1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
(3)查询hive版本
hbase(main):002:0> version 1.4.9, rd625b212e46d01cb17db9ac2e9e927fdb201afa1, Wed Dec 5 11:54:10 PST 2018
6.3 DDL操作
(1)创建一个demo表,包含 id和info 两个列簇
hbase(main):001:0> create 'demo','id','info' 0 row(s) in 23.2010 seconds => Hbase::Table - demo
(2)获得表的描述
hbase(main):002:0> list
TABLE
demo
1 row(s) in 0.6380 seconds
=> ["demo"]
---获取详细描述
hbase(main):003:0> describe 'demo'
Table demo is ENABLED
demo
COLUMN FAMILIES DESCRIPTION
{NAME => 'id', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS =>
'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '
0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS =
> 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS =>
'0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.3500 seconds
(3)删除一个列簇
注:任何删除操作,都需要先disable表
hbase(main):004:0> disable 'demo'
0 row(s) in 2.5930 seconds
hbase(main):006:0> alter 'demo',{NAME=>'info',METHOD=>'delete'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 4.3410 seconds
hbase(main):007:0> describe 'demo'
Table demo is DISABLED
demo
COLUMN FAMILIES DESCRIPTION
{NAME => 'id', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'F
ALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0',
BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.1510 seconds
(4)删除一个表
要先disable表,再drop
hbase(main):008:0> list TABLE demo 1 row(s) in 0.1010 seconds => ["demo"] hbase(main):009:0> disable 'demo' 0 row(s) in 0.0480 seconds hbase(main):010:0> is_disabled 'demo' #判断表是否disable true 0 row(s) in 0.0210 seconds hbase(main):013:0> drop 'demo' 0 row(s) in 2.3270 seconds hbase(main):014:0> list #已经删除成功 TABLE 0 row(s) in 0.0250 seconds => [] hbase(main):015:0> is_enabled 'demo' #查询是否存在demo表 ERROR: Unknown table demo!
6.4 DML操作
(1)插入数据
hbase(main):024:0> create 'demo','id','info' 0 row(s) in 10.0720 seconds => Hbase::Table - demo hbase(main):025:0> is_enabled 'demo' true 0 row(s) in 0.1930 seconds hbase(main):030:0> put 'demo','example','id:name','along' 0 row(s) in 0.0180 seconds hbase(main):039:0> put 'demo','example','id:sex','male' 0 row(s) in 0.0860 seconds hbase(main):040:0> put 'demo','example','id:age','24' 0 row(s) in 0.0120 seconds hbase(main):041:0> put 'demo','example','id:company','taobao' 0 row(s) in 0.3840 seconds hbase(main):042:0> put 'demo','taobao','info:addres','china' 0 row(s) in 0.1910 seconds hbase(main):043:0> put 'demo','taobao','info:company','alibaba' 0 row(s) in 0.0300 seconds hbase(main):044:0> put 'demo','taobao','info:boss','mayun' 0 row(s) in 0.1260 seconds
(2)获取demo表的数据
hbase(main):045:0> get 'demo','example' COLUMN CELL id:age timestamp=1552030411620, value=24 id:company timestamp=1552030467196, value=taobao id:name timestamp=1552030380723, value=along id:sex timestamp=1552030392249, value=male 1 row(s) in 0.8850 seconds hbase(main):046:0> get 'demo','taobao' COLUMN CELL info:addres timestamp=1552030496973, value=china info:boss timestamp=1552030532254, value=mayun info:company timestamp=1552030520028, value=alibaba 1 row(s) in 0.2500 seconds hbase(main):047:0> get 'demo','example','id' COLUMN CELL id:age timestamp=1552030411620, value=24 id:company timestamp=1552030467196, value=taobao id:name timestamp=1552030380723, value=along id:sex timestamp=1552030392249, value=male 1 row(s) in 0.3150 seconds hbase(main):048:0> get 'demo','example','info' COLUMN CELL 0 row(s) in 0.0200 seconds hbase(main):049:0> get 'demo','taobao','id' COLUMN CELL 0 row(s) in 0.0410 seconds hbase(main):053:0> get 'demo','taobao','info' COLUMN CELL info:addres timestamp=1552030496973, value=china info:boss timestamp=1552030532254, value=mayun info:company timestamp=1552030520028, value=alibaba 1 row(s) in 0.0240 seconds hbase(main):055:0> get 'demo','taobao','info:boss' COLUMN CELL info:boss timestamp=1552030532254, value=mayun 1 row(s) in 0.1810 seconds
(3)更新一条记录
hbase(main):056:0> put 'demo','example','id:age','88' 0 row(s) in 0.1730 seconds hbase(main):057:0> get 'demo','example','id:age' COLUMN CELL id:age timestamp=1552030841823, value=88 1 row(s) in 0.1430 seconds
(4)获取时间戳数据
大家应该看到timestamp这个标记
hbase(main):059:0> get 'demo','example',{COLUMN=>'id:age',TIMESTAMP=>1552030841823}
COLUMN CELL
id:age timestamp=1552030841823, value=88
1 row(s) in 0.0200 seconds
hbase(main):060:0> get 'demo','example',{COLUMN=>'id:age',TIMESTAMP=>1552030411620}
COLUMN CELL
id:age timestamp=1552030411620, value=24
1 row(s) in 0.0930 seconds
(5)全表显示
hbase(main):061:0> scan 'demo' ROW COLUMN+CELL example column=id:age, timestamp=1552030841823, value=88 example column=id:company, timestamp=1552030467196, value=taobao example column=id:name, timestamp=1552030380723, value=along example column=id:sex, timestamp=1552030392249, value=male taobao column=info:addres, timestamp=1552030496973, value=china taobao column=info:boss, timestamp=1552030532254, value=mayun taobao column=info:company, timestamp=1552030520028, value=alibaba 2 row(s) in 0.3880 seconds
(6)删除id为example的'id:age'字段
hbase(main):062:0> delete 'demo','example','id:age' 0 row(s) in 1.1360 seconds hbase(main):063:0> get 'demo','example' COLUMN CELL id:company timestamp=1552030467196, value=taobao id:name timestamp=1552030380723, value=along id:sex timestamp=1552030392249, value=male
(7)删除整行
hbase(main):070:0> deleteall 'demo','taobao' 0 row(s) in 1.8140 seconds hbase(main):071:0> get 'demo','taobao' COLUMN CELL 0 row(s) in 0.2200 seconds
(8)给example这个id增加'id:age'字段,并使用counter实现递增
hbase(main):072:0> incr 'demo','example','id:age' COUNTER VALUE = 1 0 row(s) in 3.2200 seconds hbase(main):073:0> get 'demo','example','id:age' COLUMN CELL id:age timestamp=1552031388997, value=\x00\x00\x00\x00\x00\x00\x00\x01 1 row(s) in 0.0280 seconds hbase(main):074:0> incr 'demo','example','id:age' COUNTER VALUE = 2 0 row(s) in 0.0340 seconds hbase(main):075:0> incr 'demo','example','id:age' COUNTER VALUE = 3 0 row(s) in 0.0420 seconds hbase(main):076:0> get 'demo','example','id:age' COLUMN CELL id:age timestamp=1552031429912, value=\x00\x00\x00\x00\x00\x00\x00\x03 1 row(s) in 0.0690 seconds hbase(main):077:0> get_counter 'demo','example','id:age' #获取当前count值 COUNTER VALUE = 3
(9)清空整个表
hbase(main):078:0> truncate 'demo' Truncating 'demo' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 33.0820 seconds
可以看出hbase是先disable掉该表,然后drop,最后重新create该表来实现清空该表。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【赞】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
作者:along阿龙
出处:http://www.cnblogs.com/along21/
简介:每天都在进步,每周都在总结,你的一个点赞,一句留言,就可以让博主开心一笑,充满动力!
版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
已将所有赞助者统一放到单独页面!签名处只保留最近10条赞助记录!查看赞助者列表
| 衷心感谢打赏者的厚爱与支持!也感谢点赞和评论的园友的支持! | ||
|---|---|---|
| 打赏者 | 打赏金额 | 打赏日期 |
| 微信:*光 | 10.00 | 2019-04-14 |
| 微信:小罗 | 10.00 | 2019-03-25 |
| 微信:*光 | 5.00 | 2019-03-24 |
| 微信:*子 | 10.00 | 2019-03-21 |
| 微信:云 | 5.00 | 2019-03-19 |
| 支付宝:马伏硅 | 5.00 | 2019-03-08 |
| 支付宝:唯一 | 10.00 | 2019-02-02 |
| 微信:*亮 | 5.00 | 2018-12-28 |
| 微信:流金岁月1978 | 10.00 | 2018-11-16 |
| 微信:,别输给自己, | 20.00 | 2018-11-06 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号