线程
线程
线程,有时被称为轻量级进程,是程序执行流的最小单元。我们可以理解为,线程是属于进程的,我们平时写的简单程序,是单线程的,多线程和单线程的区别在于多线程可以同时处理多个任务,这时候我们可以理解为多线程和多进程是一样的,我可以在我的进程中开启一个线程放音乐,也可以开启另外的线程聊qq,但是进程之间的内存独立,而属于同一个进程多个线程之间的内存是共享的,多个线程可以直接对它们所在进程的内存数据进行读写并在线程间进行交换。
GIL
说到线程就不得不提一下GIL,当我们使用多进程的时候,系统会为每一个进程分配一个cpu,线程是系统执行程序的最小单位,线程属于进程,但是在执行多线程的时候,因为GIL(全局解释器锁)的存在,在同一时刻只能有一个线程在访问cpu
为什么会有GIL?
在python界一直有着一个古老的传说,那就是python的多线程是鸡肋,那么这个传说的信度到底有多少呢?如果我们的代码是CPU密集型(涉及到大量的计算),多个线程的代码很有可能是线性执行的,所以这种情况下多线程是鸡肋,效率可能还不如单线程,因为有context switch(其实就是线程之间的切换和线程的创建等等都是需要消耗时间的);但是:如果是IO密集型,多线程可以明显提高效率。例如制作爬虫,绝大多数时间爬虫是在等待socket返回数据。这个时候C代码里是有release GIL的,最终结果是某个线程等待IO的时候其他线程可以继续执行。
那么,为什么我们大python会这么不智能呢?我们都知道,python是一种解释性语言,在python执行的过程中,需要解释器一边解释一边执行,我们之前也介绍了,同一个进程的线程之间内存共享,那么就会出现内存资源的安全问题,python为了线程安全,就设置了全局解释器锁机制,既一个进程中同时只能有一个线程访问cpu。作为解释型语言,python能引入多线程的概念就已经非常不易了,目前看到的资料php和perl等多线程机制都是不健全的。解释型语言做多线程的艰难程度可以想见。
小试牛刀,写一个多线程的程序
#!/usr/bin/env python #-*-coding:utf-8-*- import threading import time def printNum(a): print 'num:',a time.sleep(1) def printStr(str1,str2): print str1,':',str2 time.sleep(1) t_0 = threading.Thread(target=printNum ,args= (999,)) #线程1 t_0.start() t_1 = threading.Thread(target=printStr ,args= ('this is the arg','string',)) #线程2 t_1.start() for a in range(10): #同时起10个线程 t = threading.Thread(target=printNum ,args= (a,)) t.start()
threading模块
提供的类
Thread, Lock, Rlock, Condition, [Bounded]Semaphore, Event, Timer, local.
提供的方法
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
Thred类中的方法
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止 - join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后执行Thread类对象的run方法
线程锁
Lock类和Rlock类:由于线程之间随机调度:某线程可能在执行n条后,CPU接着执行其他线程。为了多个线程同时操作一个内存中的资源时不产生混乱,我们使用锁。
Lock类和RLock类都可以用于锁,不同的是:无论是lock还是rlock,提供的方法都非常简单,acquire和release。但是rlock和lock的区别是什么呢?RLock允许在同一线程中被多次acquire。而Lock却不允许这种情况。注意:如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的锁。
#!/usr/bin/env python #coding:utf-8 import threading import time def run(i): print i time.sleep(2) for i in range(5): i = threading.Thread(target=run,args=(i,)) i.start()
执行结果:
使用了锁之后
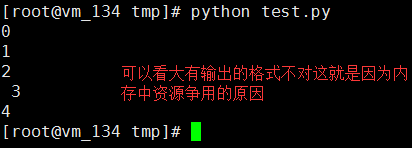
#!/usr/bin/env python
#coding:utf-8
import threading
import time
lock = threading.Lock()
def run(i):
lock.acquire()
print i
lock.release()
time.sleep(2)
for i in range(5):
i = threading.Thread(target=run,args=(i,))
i.start()
执行结果:

(Semaphore)信号量
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading,time def run(n): semaphore.acquire() time.sleep(1) print("run the thread: %s" %n) semaphore.release() if __name__ == '__main__': num= 0 semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行 for i in range(20): t = threading.Thread(target=run,args=(i,)) t.start()
event(事件)
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- event.wait(timeout) 当Flag为‘False’时,线程将被阻塞
- clear 将“Flag”设置为False
- set 将“Flag”设置为True
- is_set 返回当前‘Flag’
#!/usr/bin/env python # -*- coding:utf-8 -*- import threading def do(event): print 'start' event.wait() print 'execute' event_obj = threading.Event() for i in range(10): t = threading.Thread(target=do, args=(event_obj,)) t.start() event_obj.clear() inp = raw_input('input:') if inp == 'true': event_obj.set()
Condition
- acquire 给线程上锁
- wait wait方法释放当前线程占用的锁,同时挂起线程,直至被唤醒或超时(需timeout参数)。当线程被唤醒并重新占有锁的时候,程序才会继续执行下去。
- notify 唤醒一个挂起的线程(如果存在挂起的线程)。此方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。注:notify()方法不会释放所占用的锁。
- notifyAll 调用这个方法将通知等待池中所有线程,这些线程都将进入锁定池尝试获得锁定。此方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。
小试牛刀
#!/usr/sbin/env python #-*- coding:utf-8 -*- import threading def run(n): con.acquire() if n in [1,3,5]: con.wait(10) //程序被挂起的时候可以设置超时时间 print("run the thread: %s" %n) con.release() if __name__ == '__main__': con = threading.Condition() for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() time.sleep(3) con.acquire() print "将会释放一个线程" con.notify(1) con.release() time.sleep(3) con.acquire() print "将会释放剩余的所有线程" con.notifyAll() con.release() 执行结果: run the thread: 0 run the thread: 2 run the thread: 4 run the thread: 6 run the thread: 7 run the thread: 8 run the thread: 9 将会释放一个线程 run the thread: 1 将会释放剩余的所有线程 run the thread: 3 run the thread:
比较经典的例子是下面这个生产者与消费者的例子,这个例子网上一搜到处都是,这里简单解释一下这段代码的意义,代码中写了两个类,Consumer和Producer,分别继承了Thread类,我们分别初始化这两个类获得了c和p对象,并启动这两个线程。则这两个线程去执行run方法(这里与Thread类内部的调度有关),定义了producer全局变量和condition对象为全局变量,当producer不大于1时,消费者线程被condition对象阻塞,不能继续消费(这里是不再递减),当producer不小于10时,生产者线程被condition对象阻塞,不再生产(这里是不再累加),代码在下面,拿去执行,断点一下就明白了。


#!/usr/bin/env python #-*-coding:utf-8-*- __author__ = 'Eva_J' import threading import time condition = threading.Condition() products = 0 class Producer(threading.Thread): def __init__(self): threading.Thread.__init__(self) def run(self): global condition, products while True: if condition.acquire(): if products < 10: products += 1; print "Producer(%s):deliver one, now products:%s" %(self.name, products) condition.notify() else: print "Producer(%s):already 10, stop deliver, now products:%s" %(self.name, products) condition.wait(); condition.release() time.sleep(2) class Consumer(threading.Thread): def __init__(self): threading.Thread.__init__(self) def run(self): global condition, products while True: if condition.acquire(): if products > 1: products -= 1 print "Consumer(%s):consume one, now products:%s" %(self.name, products) condition.notify() else: print "Consumer(%s):only 1, stop consume, products:%s" %(self.name, products) condition.wait(); condition.release() time.sleep(2) if __name__ == "__main__": for p in range(0, 2): p = Producer() p.start() for c in range(0, 10): c = Consumer() c.start() condition Code
Timer
定时器,指定n秒后执行某操作
from threading import Timer def hello(): print("hello, world") t = Timer(1, hello) t.start() # after 1 seconds, "hello, world" will be printed Python 进程
协程
线程和进程的操作是由程序触发系统接口,最后的执行者是系统;协程的操作则是程序员。
协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。
协程的适用场景:当程序中存在大量不需要CPU的操作时(IO),适用于协程;
协程中提供了两个类: greenlet,gevent
greenlet
greenlet类需要程序员自己切换,要执行的代码块
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 5 from greenlet import greenlet 6 7 8 def test1(): 9 print 12 10 gr2.switch() 11 print 34 12 gr2.switch() 13 14 15 def test2(): 16 print 56 17 gr1.switch() 18 print 78 19 20 gr1 = greenlet(test1) 21 gr2 = greenlet(test2) 22 gr1.switch()
gevent
python已经帮我们封装好的类,可以实现遇到IO操作的时候启用一个协程去执行,而继续执行下面的代码
1 import gevent 2 3 def foo(): 4 print('Running in foo') 5 gevent.sleep(0) 6 print('Explicit context switch to foo again') 7 8 def bar(): 9 print('Explicit context to bar') 10 gevent.sleep(0) 11 print('Implicit context switch back to bar') 12 13 gevent.joinall([ 14 gevent.spawn(foo), 15 gevent.spawn(bar),
遇IO操作的时候自动切换
1 from gevent import monkey; monkey.patch_all() 2 import gevent 3 import urllib2 4 5 def f(url): 6 print('GET: %s' % url) 7 resp = urllib2.urlopen(url) 8 data = resp.read() 9 print('%d bytes received from %s.' % (len(data), url)) 10 11 gevent.joinall([ 12 gevent.spawn(f, 'https://www.python.org/'), 13 gevent.spawn(f, 'https://www.yahoo.com/'), 14 gevent.spawn(f, 'https://github.com/'), 15 ])
执行结果:

这就gevent的作用
更多参考:
http://www.cnblogs.com/Eva-J/articles/5110160.html
http://www.cnblogs.com/Eva-J/articles/5110160.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号