进程
什么是进程?
进程,是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。前面的话我也没懂,用非官方的白话来解释就是——执行中的程序是进程,比如qq不是进程,但是当我们双击qq开始使用它的时候,它就变成了一个进程。我们写的python程序,只有当我们执行它的时候,它才是进程。我们正在执行的IE浏览器,QQ,pycharm都是进程,从操作系统的角度来讲,每一个进程都有它自己的内存空间,进程之间的内存是独立的。
举个例子:进程就像是工厂中的一个车间,在计算机中这个车间就是一块内存空间,车间中有很多工人,每一个工人就相当于一个线程,车间中的资源对于多有的工人来讲都是共享的(内存共享)。
牛刀小试,写一个多进程的程序
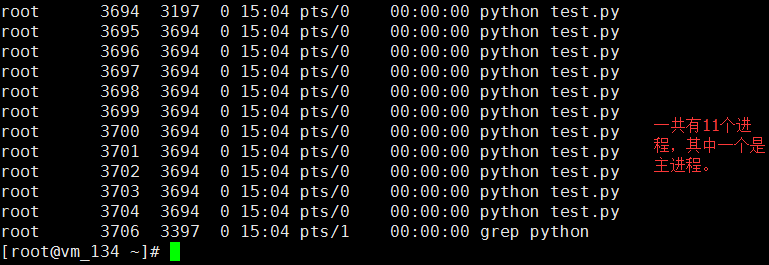
#!/usr/bin/env python # -*- coding: utf-8 -*- import time from multiprocessing import Process def run(i): time.sleep(5) print i if __name__ == "__main__": for i in range(10): i = Process(target=run,args=(i,)) i.start()
执行结果:![]()
![]()

join()方法
join()方法会阻塞程序,只有当一个进程执行完了之后才会执行下一个进程,使得多进程失去了并发执行的意义。
#!/usr/bin/env python # -*- coding: utf-8 -*- import time from multiprocessing import Process def run(i): time.sleep(5) print i if __name__ == "__main__": for i in range(10): i = Process(target=run,args=(i,)) i.start() i.join() #会阻塞程序
执行结果![]()


那么问题来了,join()存在的意义是什么呢?
应用场景:当我们起了多个进程帮我们完成了一些任务之后,提示我们这些任务完成了,应该怎么做?
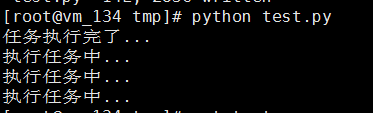
#!/usr/bin/env python # -*- coding: utf-8 -*- import time from multiprocessing import Process def run(): time.sleep(3) print "执行任务中..." if __name__ == "__main__": for i in range(3): i = Process(target=run,args=()) i.start() print "任务执行完了..."
执行结果:
结果并不是我们想要的....
这个时候join()方法就派上用场了
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time
from multiprocessing import Process
def run():
time.sleep(3)
print "执行任务中..."
if __name__ == "__main__":
for i in range(3):
i = Process(target=run,args=())
i.start()
i.join()
print "任务执行完了..."
执行结果:

顺序对了,但是没有并发呀.....
ok,了解到join()方法用到哪里之后,我们再来解决并发的问题
#!/usr/bin/env python # -*- coding: utf-8 -*- import time from multiprocessing import Process def run(): print "执行任务中..." time.sleep(3) if __name__ == "__main__": plist = [] for i in range(3): i = Process(target=run,args=()) plist.append(i) for j in plist: j.start() for k in plist: j.join() print "任务执行完了..." 执行结果:

有一条流水线横跨了两个车间
不同的进程都有自己独立的内存块,相互之间是不能访问的。但是有一条牛逼的流水线需要多个车间协同完成,即在计算机中有一个任务需要多个进程协同完成,那如何让进程间进行数据共享呢?


#!/usr/bin/env python #coding:utf-8 from multiprocessing import Process from multiprocessing import Manager import time li = [] def foo(i): li.append(i) print 'say hi',li for i in range(10): p = Process(target=foo,args=(i,)) p.start() print 'ending',li
#方法一,Array from multiprocessing import Process,Array temp = Array('i', [11,22,33,44]) def Foo(i): temp[i] = 100+i for item in temp: print i,'----->',item for i in range(2): p = Process(target=Foo,args=(i,)) p.start() #方法二:manage.dict()共享数据 from multiprocessing import Process,Manager manage = Manager() dic = manage.dict() def Foo(i): dic[i] = 100+i print dic.values() for i in range(2): p = Process(target=Foo,args=(i,)) p.start() p.join()
multiprocessing模块中提供的数据结构是进程安全的的:虽然对个进程都可以对它进行操作,但是在同一时刻只有一个进程在进行读写数据,所以不会造成脏数据。ok,这是multiprocessing模块提供的这些数据结构本身的特性,但是普通的操作,比如多个进程同时修改MySQL中的某一个数据,是不是就会造成脏数据,那怎么办?----> 进程锁来了....
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Process, Array, RLock 当创建进程时(非使用时),共享数据会被拿到子进程中,当进程中执行完毕后,再赋值给原值。 def Foo(lock,temp,i): """ 将第0个数加100 """ lock.acquire() temp[0] = 100+i for item in temp: print i,'----->',item lock.release() lock = RLock() temp = Array('i', [11, 22, 33, 44]) for i in range(20): p = Process(target=Foo,args=(lock,temp,i,)) p.start()
注意:
from multiprocessing import Pool import time def r(i): time.sleep(10) print i pool = Pool(15) #起15个进程,当不指定参数的时候,默认会起和cpu核数一样的进程数 for i in range(19): pool.apply(r,(i,)) #apply方法会顺序执行,不是并发的 pool.apply_async(r,(i,)) #是异步执行的,是并发的 pool.close() #关闭进场池,进场池中的进程不在接收任务了 pool.join() #主进程等待子进程执行完了之后再退出
pool.terminate() #该方法和join()方法相反,当程序执行到这里的时候就会直接退出,而不会管子进程有没有执行完。
print "end..."
多进程的时候获取进程的执行结果
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Pool import time def run(i): print i return i pool = Pool() result = [] for i in range(5): r = pool.apply_async(run,(i,)) result.append(r) pool.close() pool.join() print "----------------------------" for i in result: print i.get() print "end..."
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Pool import time def run(i): print i return i global relist relist = [] def last(i): relist.append(i) pool = Pool() result = [] for i in range(5): pool.apply_async(run,(i,),callback=last) pool.close() pool.join() print "----------------------------" print relist

 浙公网安备 33010602011771号
浙公网安备 33010602011771号