面向对象设计与构造第三单元博客作业
第一次作业总结
架构设计与分析
UML类图

架构分析
本次作业大部分内容都是基于官方接口的JML描述来实现,在My*类中实现的方法基本都是官方代码中的接口方法。因此,架构也基本和官方要求保持一致。
数据结构选择
因为作业中的各种接口实现都涉及了查询操作,为了降低复杂度,根据id唯一的特性,通过id-My*的方式以HashMap的形式进行存储。
针对作业中查找节点连通性(qci)以及最大连通子图个数(qbs)的指令,利用并查集的数据结构来实现,同时进行了路径压缩以及按照集合大小合并两个优化,确保不被极端样例tle。考虑到该数据结构的相对于官方架构的独立性,同时可能会在后续的几次作业中大量被用到(查找连通性是图问题的基本操作),创建了一个新的并查集类JoinSearchSet进行结构的维护。
并查集的创建与维护
并查集的生命周期与MyNetwork相当,作为MyNetwork的一个属性在构造时创建。
内部时刻维护两个HashMap。一个是子节点-父节点的键值对,用于实现并查集的基本特性;一个是根节点-集合元素个数的键值对,用于合并优化。
初始时为一个空的集合,每当进行ap操作时,会执行add()向并查集中添加一个节点。每当进行ar操作时,会执行link()试图更新并查集中的集合关系,并根据元素个数实现合并优化。除此二指令外,不会有任何主动更改并查集内部元素结构的指令。
并查集内部实现了路径压缩算法,调用时机在对外的两个查找操作find()和isLink()中。每次都会更新子节点让子节点指向根节点而非之前的父节点。
性能分析
ap
查询是否已经存在相同id的人,如果没有则添加此人。因为用Hashmap实现,因此查询复杂度O(1)。添加复杂度O(1)
ar
查询两人是否有关系,如果没有则两人之间添加关系。查询与添加复杂度均为O(1),因为实现了优化,维护并查集复杂度均摊后为O(1)
qv
两次查询后直接返回即可。时间复杂度O(1)
qps
直接返回大小。时间复杂度O(1)
qci
查询两人连通性。基于进行了优化的并查集,时间复杂度O(1)
qbs
查询最大连通子图的个数。直接返回并查集中的集合个数,时间复杂度O(1)
ag
查询组是否存在,不存在则增加组。时间复杂度O(1)
atg
向组内添加人。时间复杂度O(1)
dfg
删除组内的特定人。时间复杂度O(1)
测试与bug
构造了一个评测机,并与他人一起对拍比较。
测试分析
所有指令混合随机测试。主要检测各个指令是否正确实现与冲突。
指令分类。主要分为以下两类:组操作(ap,ag,atg,dfg),连通性操作(ap,ar,qci,qbs)
特殊数据构造。基于数据条数限制,可构造大量qbs测试。对于未采用并查集的方法(如深搜或广搜),其复杂度比用了并查集的要高出一个数量级。
bug分析
本地自测未发现bug。强测和互测也未被发现bug。
互测中用构造的qbs特殊数据成功测出了其他人的tle。
第二次作业总结
架构设计与分析
UML类图

架构分析
大部分内容依然基于官方接口的JML描述来实现,由于官方的新增jml描述没有对之前的接口做出什么更改,因此基本都是增量式开发。除了官方要求实现的接口类,仅新增了一个MsTree类和一个Edge类用于计算最小生成树
数据结构选择
针对MyPerson中新增的messages,基于qrm的特性选取链表来实现,方便进行头插。其余完全沿用第一次。针对最小生成树的指令(qlc),由于其不易维护,每次都会重新计算,且所求的只是权值和,所以不需要构造出实际结构,只需沿用原来的并查集实现Kruskal算法即可。
最小生成树算法
因为第一次作业已经实现了并查集并独立封装成了一个类,因此可以在此基础上直接使用Kruskal算法来运算。同时,考虑到实际实现,边的数目不会远多于点的数目的,因此Kruskal的复杂度也更优。
性能分析
qgps
直接返回组内人数,复杂度O(1)
qgvs
返回组内所有人的关系和。如果每次询问都会重新计算,则单条指令复杂度O(n2),大量该数据可能会超时。如果采用动态维护的方法,均摊到其他指令中,复杂度变为O(1)。
qgav
可以每次都重新计算,复杂度为O(n),不会超时。也可以动态维护,复杂度O(1)。
am
查询后添加。时间复杂度O(1)
sm
查询连通性后发送。基于进行了优化的并查集,时间复杂度O(1)
qsv
查询后直接返回,时间复杂度O(1)
qrm
查询后选取最靠前的几个返回。时间复杂度O(1)
qlc
在并查集的基础上使用Kruskal算法,单次查询复杂度O(mlogm)
测试与bug
测试分析
在第一次的基础上对测试器进行迭代开发。
对于组操作,新增了一系列组内查询指令:qgps,qgvs,qgav
对于连通性操作,新增:qlc
新增消息类测试,包含:ap,ar,ag,atg,dfg,am,sm,qsv,qrm,其中前三条为一些固定操作
特殊数据构造。针对组内人数限制,构造超过1111个人进入同一个组的数据;测试qgsv,组内增加1111个人后,不断查询同一组;测试qlc:构造一个90人的完全图,权值递减/递增
bug分析
本地自测发现实现最小生成树时忘记更新临时新增的并查集的bug。强测和互测未被发现bug。
互测中用构造的qgvs的特殊数据成功测出了其他人的tle。
第三次作业总结
架构设计与分析
UML类图

架构分析
大部分内容依然基于官方接口的JML描述来实现。对于新增的EmojiMessage,新增了一个HashMap维护已有的emoji以及其热度。此外,为了实现最短路算法的优化,新增了Point类用于排序时的比较
数据结构选择
本次没有需要新增的数据结构。
最短路算法
因为没有负权值的边,因此选用Dijkstra算法,同时为防止超时进行了堆优化。
性能分析
arem
与am操作无异,复杂度O(1)
anm
与am操作无异,复杂度O(1)
cn
遍历删除,复杂度O(n)
aem
与am操作无异,复杂度O(1)
sei
表情同样实现了HashMap映射,因此复杂度O(1)
qp
查询后直接返回,时间复杂度O(1)
dce
遍历表情并删除,再根据删除的表情删除对应的消息,复杂度O(n)
qm
查询后直接返回,复杂度O(1)
sim,,
朴素的Dijkstra算法复杂度O(n2),堆优化后变为O(nlogn),复杂度均符合时间要求
测试与bug
测试分析
在第一次的基础上对测试器进行迭代开发。
新增一个测试方法包括本次的新增操作。其中,降低cn、dce操作的频率,以保证有效测试的指令占绝大多数。
特殊数据构造。考虑到本次新增操作很难出现tle等情况,因此不再构造新的特殊数据
bug分析
本地自测发现组内的NoticeMessage时发送人的money会多加一次。强测和互测未被发现bug。
互测中发现其他人也产生了本地自测的这个问题。
扩展
整体设计
设计结构如下:
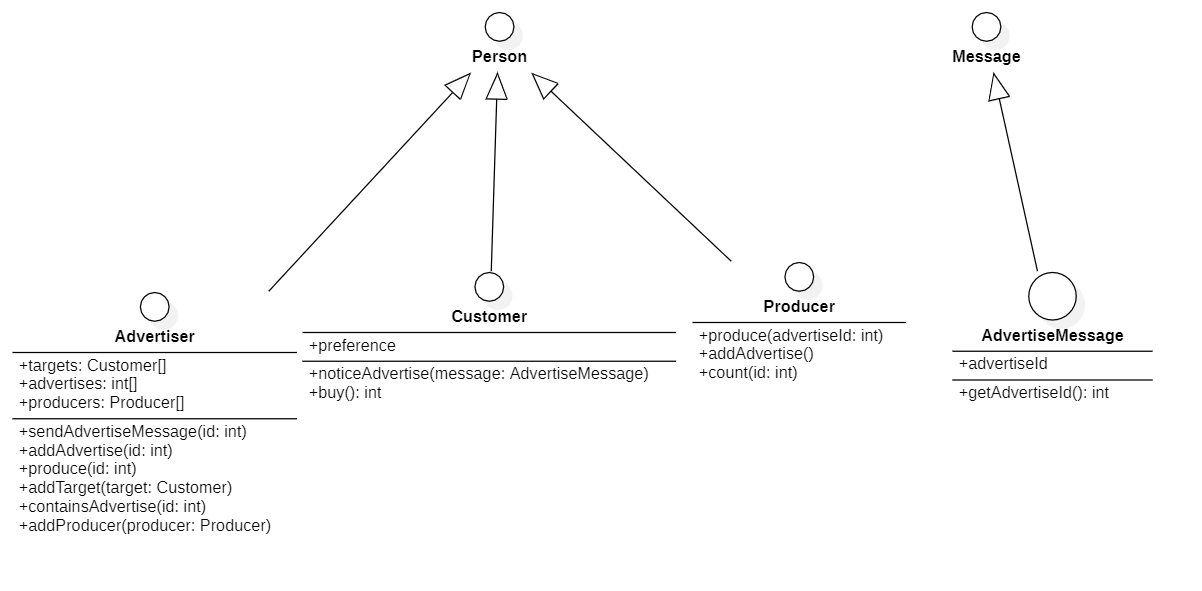
Advertiser的部分方法如下。
sendAdvertiseMessage()
/*
@ public normal_behavior
@ requires containsAdvertise(id);
@ assignable targets[*].messages
@ ensures (\forall int i; 0 <= i && i <= targets.length;
@ (\forall int j; 0 <= j && j < \old(targets[i].getMessages().size());
@ targets[i].getMessages().get(j+1) == \old(targets[i].getMessages().get(j))));
@ ensures (\forall int i; 0 <= i && i <= targets.length;
@ targets[i].getMessages().get(0) == \old(getMessage(id));
@ ensures (\forall int i; 0 <= i && i <= targets.length;
@ targets[i].getMessages().size() == \old(targets[i].getMessages().size()) + 1);
@ public exceptional_behavior
@ signals (AdvertiseIdNotFoundException e) !containsAdvertise(id);
*/
public void sendAdvertiseMessage(int id) throws AdvertiseIdNotFoundException;
addAdvertise()
/*@ public normal_behavior
@ requires !containsAdvertise(id);
@ assignable advertises;
@ ensures advertises.length == \old(advertises.length) + 1;
@ ensures (\forall int i; 0 <= i && i < \old(advertises.length);
@ (\exists int j; 0 <= j && j < advertises.length; advertises[j].equals(\old(advertises[i]))));
@ ensures (\exists int i; 0 <= i && i < advertises.length; advertises[i].equals(id));
@ also
@ public exceptional_behavior
@ signals (EqualMessageIdException e) containsAdvertise(int id);
*/
public void addAdvertise(int id) throws EqualAdvertiseIdException;addTarget()
/*@ public normal_behavior
@ requires !(\exists int i; 0 <= i && i < targets.length; targets[i].equals(customer));
@ assignable targets;
@ ensures targets.length == \old(targets.length) + 1;
@ ensures (\forall int i; 0 <= i && i < \old(targets.length);
@ (\exists int j; 0 <= j && j < targets.length; targets[j].equals(\old(targets[i]))));
@ ensures (\exists int i; 0 <= i && i < targets.length; targets[i].equals(customer));
@ also
@ public normal_behavior
@ requires (\exists int i; 0 <= i && i < targets.length; targets[i].equals(customer));
@ assignable nothing;
*/
public void addTarget(Customer customer);
}心得体会
通过本单元的学习,我发现jml的特点就是用极其复杂的一段话来严谨的描述一个实现起来很简单的操作。在和一起对拍的同学在针对课下作业的讨论中,一个十几二十几行的jml规格描述我们可以用一两句话就描述清楚,而且很少产生歧义。这是jml的缺点,晦涩难懂。但如果两个人一旦产生不同,又能够通过jml的描述给出一个严谨的唯一答案,而不需要通过举例等其他方法来说明要实现的规格。
针对jml语言的阅读,主要应该分为如下几个阶段:
1. 确定正常操作和异常操作
2. 确定操作下的前置条件requires以及对应的后置条件ensures
3. 根据操作的输入状态与输出状态,构造出一个有限状态机的形式
在jml描述中,也有一些比较固定的特征性描述。比如给数组添加一个元素,往往就存在这样的三段:数组的大小(.ength)是原数组(\old)的大小+1、所有原数组的元素(\forall)都存在于新数组中(\exist)、新添加元素存在于新数组中。
相比于前两个单元,本单元要简单了不少。整体架构完全不需要自己实现,最多只考虑下元素的存储方式(ArrayList、HashMap)即可,唯一的复杂点也只在三次的算法设计上。前两单元的代码编写时间是远超本地测试的时间的,但本次作业里构造评测机的时间和编写时间大致相当。
从互测上看,明显大家的兴致都降了不少。除了第二次作业有人在群里广播了qgsv的tle导致大家几乎都提交了一遍数据,剩下的两次刀人频率都很低。而这两次作业组里也都是能找到bug的。大概是因为os的难度上来了oo都想摆了吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号