《深入理解计算机系统》第三版 第三章家庭作业答案
简述
相信大部分人在做这些题的时候,因为书中没有给答案,而去网上找参考答案,比如那些高阅读量的博客和git。当然,我也是这样,但他们的答案中还是有好多错误,比如3.59他们几乎都没讲清楚提示中的公式怎么来的,3.60中对移位操作中对%cl的读取,等等。。希望读者们在阅读这些文章时,要带着自己的思想和疑问去理解,而不是一味地觉得答案就肯定是对的,当然,本文有任何错误,也欢迎各位指出。
3.58
long decode2(long x,long y,long z)
{
y = y - z;
x = x * y;
y <<= 63;
y >>= 63;
return y ^ x;
}
y先左移63位,再右移63位,如果之前y是奇数,那么y的二进制全是1;y是偶数,那么y的二进制全是0.
3.59

首先讲解一下,提示里的公式,之所以可以这么写是因为符号拓展,以4位二进制int为例:
1111的补码数,为-1.将其进行符号拓展后为1111 1111,其值也为-1,但这里可以将1111 1111写为高位1111的补码数 * + 低位1111的无符号数:
即-1 * + 15 = -1.
原理:%rdx和%rax的二进制连起来表示这个数,既然连起来了,符号位就跑到了%rdx的最高位了,除符号位权值为负外,其余位的权值均为正。所以,高位寄存器%rdx当做补码数,低位寄存器%rax当做无符号数。因为符号位现在在高位寄存器那儿呢,所以高位寄存器当做补码数了;而低位寄存器的每一位的权值现在都是正的了,所以低位寄存器要当做无符号数。
所以为即x的二进制表示作为无符号数。与有相同的位级表示。
,当原数符号位为1,64位二进制位上全为1,其值为-1;当原数符号位为0时,64位二进制位上全为0,其值为0。
再讲解一下本文用到的数学公式:有和,那么有:
但这个公式其实并不陌生,它与2.3.5补码乘法(P67) 里面的公式2.18有异曲同工之妙,另外理解本题需要阅读此节。
第一项肯定溢出,双寄存器都装不下,截断后全为0,忽略。
关于第二项,这个数值是需要放在高位寄存器中的(因为这一项乘以的数为),假设分别是-1和UMAX,仅仅是它俩的乘积都会使得高位寄存器溢出(考虑补码数和无符号数的表示范围就能想到),如果溢出,放入高位寄存器时会自行截断。
第三项,直接使用双寄存器来保存结果。
下面开始讲解汇编代码:
第一个参数*dest在%rdi中,第二个参数x在%rsi中,第三个参数y在%rdx中。
store_prod:
movq %rdx, %rax # %rax = y
cqto # convert q to o,4字符号拓展到8字,假如y的符号位为1,那么%rdx所有位都是1(此时值是-1),否则,%rdx全为0(此时值是0).%rdx = yh
movq %rsi, %rcx # %rcx = x
sarq $63, %rcx # 将%rcx向右移63位,跟%rdx的含义一样,二进制位要么全是1,要么是0,%rcx = xh.
imulq %rax, %rcx # %rcx = y * xh
imulq %rsi, %rdx # %rdx = x * yh
addq %rdx, %rcx # %rcx = y * xh + x * yh,计算了第二项
mulq %rsi # 无符号计算 xl*yl,并将xl*yl的128位结果的高位放在%rdx,低位放在%rax,计算了第三项.
addq %rcx, %rdx # 将第二项计算结果加到%rdx
movq %rax, (%rdi) # 将%rax的值放到dest的低位
movq %rdx, 8(%rdi)# 将%rdx的值放到dest的高位
ret
重点讲一下6-8行,发现这里代码计算的是,而数学公式里面要求是,之所以汇编要如此计算,是利用了相同的位级向量,无论用无符号数乘法还是补码乘法,其结果的截断的位级表示肯定是一样的。
但这里有点不一样,给定和两个位级向量,固定将看作补码数,而将分别看作补码数和无符号数,那么x与y的两种乘积的截断的位级表示是一样的。接下来用个小例子来证明该结论。(注意代码是将乘积的截断的位级表示看作补码数的)
假设整数类型为3位,和分别为111和111,x的值为-1,而y的值分别为-1,7.
首先看-1 * -1 = 1,那么位级表示为001
再看-1 * 7 = -7,那么位级表示为1001,截断后为001
证毕。
考虑下第9行是否会溢出,无符号数最大为,所以两个无符号数的乘积最大为等于.而128位的补码数的最大范围为.
而 = > 0,所以可能溢出。
3.60
long loop(long x,int n)
{
long result = 0;
long mask;
for(mask = 1;maks != 0;mask=mask << (n % 64))//如果这里不能保证是正余数(0-63)的话,就用下面的写法
{
result |= (x & mask);
}
return result;
}
这里难点主要在于salq %cl, %rdx这里的移位量到底是多少,根据移位操作中的解释,因为被移位数为64位二进制(),所以只看%cl的低6位,或者循环的执行可以改为mask=mask<<(n & 0x3F)
3.61

首先看上图c语句与其汇编语句的对应(3.6.6节),题目要求新函数对应的汇编代码也会用到条件传送,即要求有三目表达式。对于第4行,看起来可能是多余的,但3.6.6节讲到条件传送中,第一个操作数可以是源寄存器或者内存地址,所以立即数是不可以,所以这里多了一步。
如果函数改成long cread_alt(long *xp) { return (!xp ? 0 : *xp); },那么汇编代码可能是:
cread_alt:
movl $0, %eax
testq %rdi, %rdi
cmovne (%rdi), %rax #直接传送
ret
当然也可以改成如下:
long cread_alt(long *xp)
{
long t = 0;
long *p = xp ? xp : &t; //得到xp指针或者0的地址,这句转换为条件传送语句后,也不会可能去读取空指针
return *p; //解引用,现在读取指针指向值肯定不会出错
}
为了验证汇编代码,本人用MinGW进行了编译,使用命令gcc -Og -S test.c,c文件内容为long cread(long *xp) { return (xp ? *xp : 0); },发现不管优化程度是多少,生成汇编基本都是(发现并没有使用条件传送,且没怎么看懂):
LFB0:
movl 4(%esp), %eax #得到了xp指针
testl %eax, %eax
je L3
movl (%eax), %eax #指针不为空,读取指针指向的值
ret
L3:
xorl %eax, %eax
ret
3.62
锻炼你的反向工程能力。注意有的语句可以简化,不用非得照着汇编原封不动翻译。
long switch3(long *p1, long *p2, mode_t action) {
long result = 0;
switch(action) {
case MODE_A:
result = *p2;
*p2 = *p1;
break;
case MODE_B:
*p1 = *p1 + *p2;
result = *p1;
break;
case MODE_C:
*p1 = 59;
result = *p2;
break;
case MODE_D:
*p1 = *p2;
result = 27;
break;
case MODE_E:
result = 27;
break;
default:
result = 12;
break;
}
return result;
}
3.63

0000000000400590<switch_prob>:
400590: 48 83 ee 3c sub $0x3c, %rsi #n -= 60,说明最后n的实际数要加60
400594: 48 83 fe 05 cmp $0x5, %rsi #比较n > 5
400598: 77 29 ja 4005c3 <switch_prob+0x33> #如果n > 5那么跳转到default
# 所以n <= 5的情况就只有交给跳转表处理
40059a: ff 24 f5 f8 06 40 00 jmpq *0x4006f8(,%rsi,8) #间接跳转到0x4006f8 + 8*n
# 跳到跳转表对应的位置,从跳转表来看,n的取值只能是0-5,因为只有6个八字节
# 0和2会跳到这个位置
4005a1: 48 8d 04 fd 00 00 00 lea 0x0(,%rdi,8),%rax
4005a8: 00
400593: c3 retq
# 3会跳到这个位置
4005aa: 48 89 f8 mov %rdi, %rax
4005ad: 48 c1 f8 03 sar $0x3, %rax
4005b1: c3 retq
# 4会跳到这个位置
4005b2: 48 89 f8 mov %rdi, %rax
4005b5: 48 c1 e0 04 shl $0x4, %rax
4005b9: 48 29 f8 sub %rdi, %rax
4005bc: 48 89 c7 mov %rax, %rdi
# 5会跳到这个位置
4005bf: 48 0f af ff imul %rdi, %rdi
# 大于5和1会跳到这个位置
4005c3: 48 8d 47 4b lea 0x4b(%rdi), %rax
4005c7: c3 retq
而且从汇编代码来看,如果n的值是<60,那么n-60<0,那么汇编代码就会执行到jmpq *0x4006f8(,%rsi,8),本来应该跳转到这6个八字节,但最终间接跳转到非法的八字节。但也许此题重点不在于此,应假设n>=60.
long switch_prob(long x, long n){
long result = x;
switch(n):{
case 60:
case 62:
result = x * 8;
break;
case 63:
result = result >> 3;
break;
case 64:
result = (result << 4) - x;
x = result;
case 65:
x = x * x;//注意64,65后面没有break
default:
result = x + 75;
}
}
3.64
假设有数组,等式3.1为,这里T明显为列数,更加深入的说,代表第一维度中每个维度的元素个数。
假设有数组,等式3.1应为,ST为第一维度中每个维度的元素个数。
store_ele:
leaq (%rsi, %rsi, 2), %rax # %rax = 3 * j
leaq (%rsi, %rax, 4), %rax # %rax = j + 4(3j) = 13 * j
leaq %rdi, %rsi # %rsi = i
salq $6, %rsi # %rsi * = 64
addq %rsi, %rdi # %rdi = 65 * i
addq %rax, %rdi # %rdi = 65 * i + 13 * j
addq %rdi, %rdx # %rdx = 65 * i + 13 * j + k
movq A(, %rdx, 8), %rax # %rax = A + 8 * (65 * i + 13 * j + k)
movq %rax, (%rcx) # *dest = A[65 * i + 13 * j + k]
movl $3640, %eax # sizeof(A) = 3640
ret
则有:
S * T = 65
T = 13
S * T * R * 8 = 3640
得到:R = 7 ; S = 5 ; T = 13
3.65
.L6:
movq (%rdx), %rcx # t1 = A[i][j]
movq (%rax), %rsi # t2 = A[j][i]
movq %rsi, (%rdx) # A[i][j] = t2
movq %rcx, (%rax) # A[j][i] = t1
addq $8, %rdx # A[i][j] -> A[i][j+1]
addq $120, %rax # A[j][i] -> A[j+1][i], 120 == 8*M
cmpq %rdi, %rax
jne .L6 # if A[j][i] != A[M][M]
A.从第6行就能看出来%rdx是A[i][j],因为每次只加8,即一个元素大小。
B.因为寄存器%rdx是A[i][j],所以另一个寄存器%rax是A[j][i]。
C.根据公式,120 == 8*M,所以M为15.
3.66
sum_col:
leaq 1(, %rdi, 4), %r8 # %r8 = 4 * n + 1
leaq (%rdi, %rdi, 2), %rax # result = 3 * n
movq %rax, %rdi # %rdi = 3 * n
testq %rax, %rax
jle .L4 # if %rax <= 0, goto L4
salq $3, %r8 # %r8 = 8 * (4 * n + 1)
leaq (%rsi, %rdx, 8), %rcx # %rcx = A[0][j]的地址
movl $0, %eax # result = 0
movl $0, %edx # i = 0
.L3:
addq (%rcx), %rax # result += A[i][j]
addq $1, %rdx # i += 1
addq %r8, %rcx # 这里每次+8*(4n+1),说明每一行有4n+1个,因此NC(n)为4*n+1
cmpq %rdi, %rdx
jne .L3 # 当%rdx等于3*n才循环结束,所以可以说明一共有3n行,因此NR(n)为3*n
rep; ret
.L4:
movl $0, %eax
ret
所以有NR(n) = 3 * n; NC(n) = 4 * n + 1;
3.67
# strB process(strA s)
# s in %rdi
process:
movq %rdi, %rax #第一个参数作为返回值,即要返回的结构体的开始地址
movq 24(%rsp), %rdx #栈指针开始的第4个八字节的内容,存入%rdx,内容为结构体A的第二个成员:指针p
movq (%rdx), %rdx #读取指针p指向的long型对象,再存入%rdx
movq 16(%rsp), %rcx #栈指针开始的第3个八字节的内容,内容为结构体A的成员数组的第2个元素:D[1]
movq %rcx, (%rdi) #将D[1],存入返回结构体的第1个八字节
movq 8(%rsp), %rcx #栈指针开始的第2个八字节的内容,内容为结构体A的成员数组的第1个元素:D[0]
movq %rcx, 8(%rdi) #将D[0],存入返回结构体的第2个八字节
movq %rdx, 16(%rdi) #将long型对象,存入返回结构体的第3个八字节
#栈指针开始的第1个八字节,这里并没有使用,因为存的是调用后的返回地址
ret
# long eval(long x, long y, long z)
# x in %rdi, y in %rsi, z in %rdx
eval:
subq $104, %rsp #为栈分配了13*8字节空间,即13个八字节
movq %rdx, 24(%rsp) #z存入栈指针开始的第4个八字节
leaq 24(%rsp), %rax #栈指针开始的第4个八字节中的第一个字节的地址,存入%rax,作为结构体A的指针成员p
movq %rdi, (%rsp) #x存入栈指针开始的第1个八字节
movq %rsi, 8(%rsp) #y存入栈指针开始的第2个八字节
movq %rax, 16(%rsp) #p存入栈指针开始的第3个八字节
leaq 64(%rsp), %rdi #栈指针开始的第9个八字节,的开始地址
call process #这里有隐藏操作,分配八字节栈空间,存入返回地址,即下一行代码地址
movq 72(%rsp), %rax #这三行汇编执行加法
addq 64(%rsp), %rax
addq 80(%rsp), %rax
addq $104, %rsp #回收栈空间
ret
A.
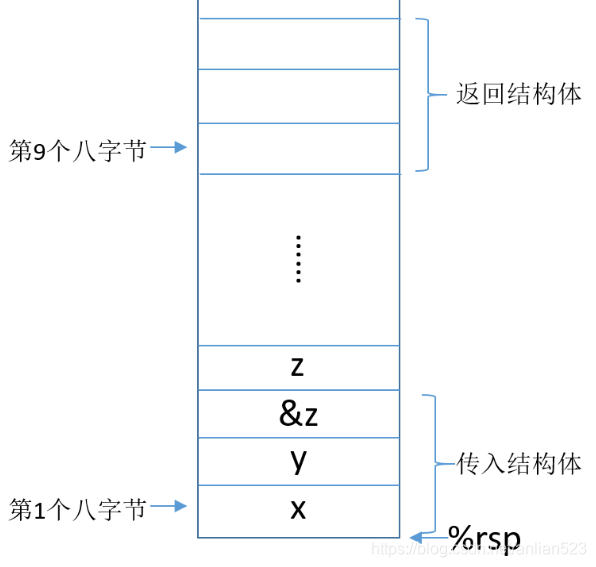
注意此图中,从下往上是地址增加方向。
B.
传递了%rsp+64,即栈指针开始的第9个八字节,的开始地址。
C.
因为结构参数s存在栈空间里,所以用%rsp+偏移量来访问的。
D.
r的空间是分配在栈空间里,所以也是%rsp+偏移量来设置的。
E.
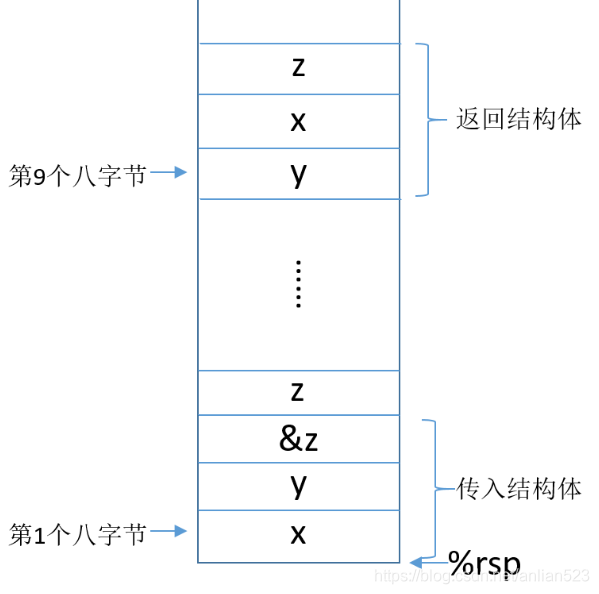
F.
结构体作为参数传入和返回时,都是以指针来传递。
3.68
从汇编movslq 8(%rsi), %rax中,可以看出结构体str2中int t是从第2个八字节开始:
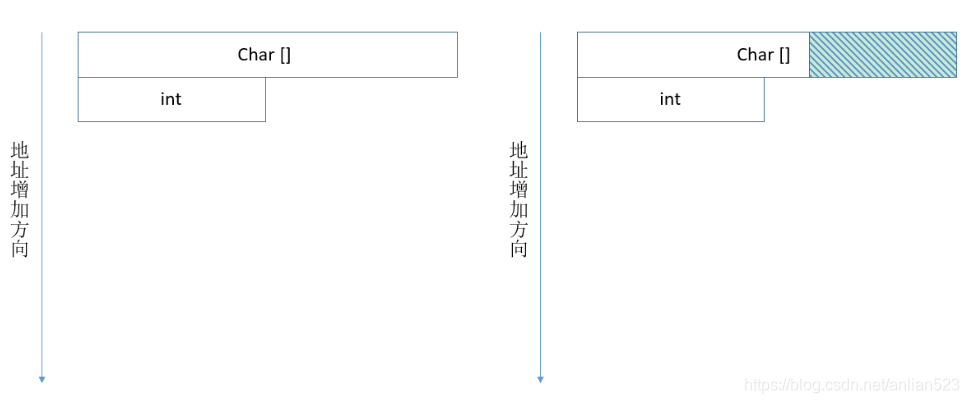
左边为最大情况,右边为最小情况。在最小情况中,如果数组再少一个元素,即数组大小由5字节变成4字节,那么int变量就会跑到第1个八字节中去了。
所以5<=B<=8.
从汇编addq 32(%rsi), %rax中,可以看出结构体str2中long u是从第5个八字节开始:
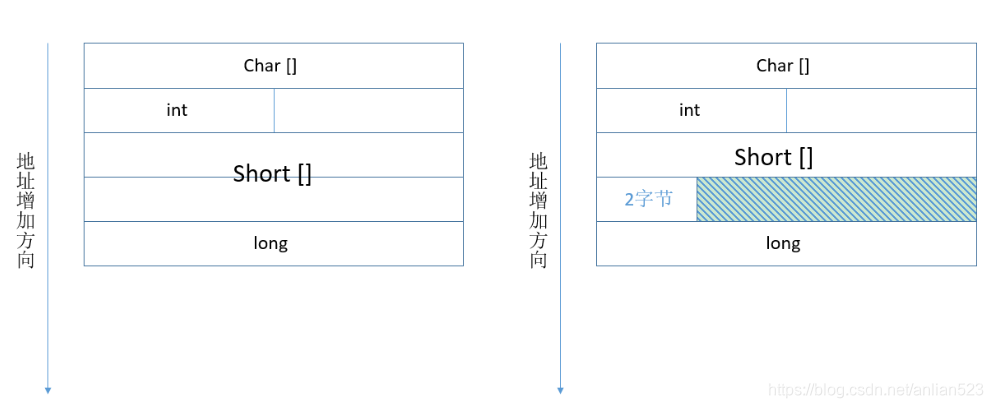
左边为最大情况,右边为最小情况。
所以7<=A<=10.
从汇编movq %rax, 184(%rdi)中,184既可能是最大情况,也可能是8字节补齐情况。
所以184-8<A*B*4<=184.
答案唯一解为:A=9; B=5;。
3.69
从c语句ap->x[ap->idx] = n;知道a_struct的两个成员分别是数组和整数类型。
# void test(long i, b_struct *bp)
# i in %rdi, bp in %rsi
test:
mov 0x120(%rsi), %ecx # bp+288 匹配bp->last
add (%rsi), %ecx # bp->first + bp->last
lea (%rdi,%rdi,4), %rax # %rax = i*5
lea (%rsi,%rax,8), %rax # %rax = bp+i*40
# ap = &bp->a[i] = bp+8+i*40, +8意味着从bp开始的第1个八字节里面只有int,且a_struct大小必为8字节或更大,若为4字节,就不是+8而是+4了
# 因为是i*40,所以a_struct大小为40字节
# 此句很明显取出了一个数,再结合倒数第二条指令mov %rcx, 0x10(%rax,%rdx,8),所以%rdx为ap->idx
# 而且在结构体a_struct中,第一个成员为整数类型的idx
mov 0x8(%rax), %rdx
movslq %ecx, %rcx # mov时符号拓展成4字8字节
# 先看0x10(%rax,)部分,是bp+16+i*40,比ap多了8字节,这里是a_struct数组成员的开始地址,也说明了idx大小为8字节
# 再看(,%rdx,8)部分,是idx*8,所以说明了a_struct数组成员的大小为8字节
# 合起来看就是bp+8+i*40+8 +idx*8,第二个+8跳过了a_struct的整数成员idx
mov %rcx, 0x10(%rax,%rdx,8)
# a_struct大小为40字节,第一个成员idx为long,8字节,还剩32字节
# 第二个成员是long型数组,按照剩余字节,数组大小为4
retq
A.
因为7*40 + 8 = 288 = 0x120,所以CNT=7,要推出CNT必须先推理出a_struct的大小。
B.
typedef struct {
long idx;
long x[4];
} a_struct;
3.70
proc:
movq 8(%rdi), %rax #偏移量为8,存的是up->e1.y或者是up->e2.next
movq (%rax), %rdx #用作内存引用,所以上面是up->e2.next,取出*(up->e2.next)的偏移量为0的内容,也有两种情况
movq (%rdx), %rdx #用作内存引用,所以上面是*(up->e2.next).e1.p,取出*( *(up->e2.next).e1.p )的内容,为long型
subq 8(%rax), %rdx #取出*(up->e2.next)的偏移量为8的内容,因为要作为减数,所以减数是*(up->e2.next).e1.y
movq %rdx, (%rdi) #将减法之差存入,up->e2.x
ret
A.
e1.p 0
e1.y 8
e2.x 0
e2.next 8
B.
16
C.
up->e2.x = *( *(up->e2.next).e1.p ) - *(up->e2.next).e1.y,具体看注释。
3.71
这道题主要需要了解fgets函数(char * fgets ( char * str, int num, FILE * stream );)。下面将fgets函数的api文档进行翻译。
Reads characters from stream and stores them as a C string into str until (num-1) characters have been read or either a newline or the end-of-file is reached, whichever happens first.
A newline character makes fgets stop reading, but it is considered a valid character by the function and included in the string copied to str.
A terminating null character is automatically appended after the characters copied to str.
Notice that fgets is quite different from gets: not only fgets accepts a stream argument, but also allows to specify the maximum size of str and includes in the string any ending newline character.
从流中读取字符,并将它们作为C string存储进str参数中,直到num-1个字符已经被读取,或者是到达新行或者EOF,这三个条件谁先到达都会使得读取停止。
换行字符使得fgets函数停止读取,不过换行符也会被当做一个合法字符来读取。
一个空字符将会自动加在读取的字符后,然后再复制给str。
On success, the function returns str.
If the end-of-file is encountered while attempting to read a character, the eof indicator is set (feof). If this happens before any characters could be read, the pointer returned is a null pointer (and the contents of str remain unchanged).
If a read error occurs, the error indicator (ferror) is set and a null pointer is also returned (but the contents pointed by str may have changed).
当函数执行成功,返回str。
当读取字符时遇到一个EOF时,EOF标识符被设置。如果在任何字符都没有进行读取时,就发生了这样的事,那么返回空指针(str指向的文本保持不变)。如果发生了读取错误,那么error标识符被设置,也返回空指针(但str指向的文本可能会改变)。
#include <stdio.h>
#include <assert.h>
#define BUF_SIZE 12
void good_echo(void) {
char buf[BUF_SIZE];
while(1) {
char* p = fgets(buf, BUF_SIZE, stdin);
if (p == NULL) {//这里需要改
break;
}
printf("%s", p);
}
return;
}
1.根据翻译得知,使用fgets函数便可以保证“当输入字符超过缓冲区空间大小时,也能正常工作”。
2.关于“你的代码还应该检查错误条件,在遇到错误条件时返回”这点,其实判断条件if (p == NULL)太笼统了,可以通过ferror函数(int ferror ( FILE * stream );)来判断(stdin的类型是FILE *),当读取出错时,调用ferror函数返回非0值,上述代码应写成if ( (p == NULL) & (ferror(stdin) != 0) )。
3.72
此题与练习题3.49几乎一模一样,具体讲解请看此篇博客。
注意c语句long **p = alloca(n * sizeof(long*));,p的类型为long **即long指针的指针,可以这么理解,分配long型数组时,返回long *指针;当分配long *型数组时,返回long **指针。

第5行%rax存的是30+8n。
第6行分为两种情况:(and -16解释为向下取整到16的倍数)
a.当为偶数时,分成8n和30两部分,8n and -16得8n,30 and -16得16.
b.当为奇数时,分成8(n-1)和38两部分,8(n-1) and -16得8(n-1),38 and -16得32.
第8行加上偏置15(),第9行 and -16,执行完这两行,就相当于向上取整到16的倍数。注意在练习题3.49中,andq $-16, %r8这句是通过两句汇编来实现的(先右移再左移,而本题是直接and -16)。
A.
,根据上面的分析:
当n为偶数时,
当n为奇数时,
B.
C.
大方向分为,当为16的倍数(这种情况p数组就直接从开始分配),和不为16的倍数(这种情况p数组还需要向地址增加方向滑动1-15个字节)。
1.因为e1和e2是用来滑动的,所以当e2为0,即为16的倍数时,当e1就会最大。再看当n为奇数时,分配数组空间为8 * n + 24,多出来24字节空间作为e1。e1最大为24,此时为16的倍数,且n为奇数。
2.当不为16的倍数时,p数组空间需要滑动来16对齐,当%16=1时,向地址增加方向滑动15个字节,此时达到最大滑动距离了,即e2=15。而e1=可滑动空间-e2,当n为偶数时,滑动空间为16字节,则e1=可滑动空间-e2=16-15=1。e1最小为1,此时%16=1,且n为偶数。
D.
p数组空间是16对齐的。
是容下8 * n字节的最小的16的倍数再加16。
3.73
原书中的汇编即图3-51中的汇编,确实很乱,这样改完之后清爽多了。
find_range:
vxorps %xmm1, %xmm1, %xmm1
vucomiss %xmm1, %xmm0
jp .L1
ja .L2
jb .L3
je .L4
.L2:
movl $2, %eax
ret
.L3:
movl $0, %eax
ret
.L4:
movl $1, %eax
ret
.L1:
movl $3, %eax
rep; ret
3.74
这样的话,连cmovp都不需要用了。
find_range:
vxorps %xmm1, %xmm1, %xmm1
movq $0, %r8
movq $1, %r9
movq $2, %r10
movq $3, %rax
vucomiss %xmm1, %xmm0
cmovb %r8, %rax
cmove %r9, %rax
cmova %r10, %rax
ret
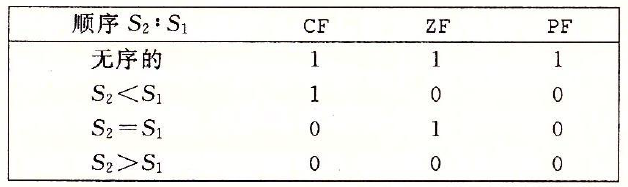

可以看出在比较大于小于时,有两套指令可以用,但因为比较浮点数用到的标志位为CF和ZF,所以再看上表,则应该使用下面这套指令。
3.75
A.
| 第n个参数 | real | img |
|---|---|---|
| 1 | %xmm0 | %xmm1 |
| 2 | %xmm2 | %xmm3 |
| 3 | %xmm4 | %xmm5 |
| n | %xmm(2n-2) | %xmm(2n-1) |
B.
imag部分返回值在%xmm1, real部分返回值在%xmm0.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号