JDK8 HashMap源码 putMapEntries解析
putMapEntries函数会被HashMap的拷贝构造函数public HashMap(Map<? extends K, ? extends V> m)或者Map接口的putAll函数(被HashMap给实现了)调用到。该函数由于是默认的包访问权限,所以一般情况下用户无法调用。
putMapEntries全解析
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {//m的类型参数是? extends,所以只能使用泛型代码的出口,比如get函数
int s = m.size();
if (s > 0) {//前提是传入map的大小不为0,
if (table == null) { // 说明是拷贝构造函数来调用的putMapEntries,或者构造后还没放过任何元素
//先不考虑容量必须为2的幂,那么下面括号里会算出来一个容量,使得size刚好不大于阈值。
//但这样会算出小数来,但作为容量就必须向上取整,所以这里要加1
float ft = ((float)s / loadFactor) + 1.0F;
//如果小于最大容量,就进行截断;否则就赋值为最大容量
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
//虽然上面一顿操作猛如虎,但只有在算出来的容量t > 当前暂存的容量(容量可能会暂放到阈值上的)时,才会用t计算出新容量,再暂时放到阈值上
if (t > threshold)
threshold = tableSizeFor(t);
}
//说明table已经初始化过了;判断传入map的size是否大于当前map的threshold,如果是,必须要resize
//这种情况属于预先扩大容量,再put元素
else if (s > threshold)
resize();
//循环里的putVal可能也会触发resize
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {//下面的Entry泛型类对象,只能使用get类型的函数
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
注释里已经解释得很清楚了,这里再提几点重要的。
if (table == null)分支,说明是HashMap的拷贝构造函数来调用的putMapEntries,或者是构造以后还没有放过任何元素,然后再调用putAll。float ft = ((float)s / loadFactor) + 1.0F这里的加1是因为,size / loadFactor = capacity,但如果算出来的capacity是小数,却又向下取整,会造成容量不够大,所以,如果是小数的capacity,那么必须向上取整。- 算出来的容量必须小于最大容量
MAXIMUM_CAPACITY,否则直接让capacity等于MAXIMUM_CAPACITY。 if (t > threshold)这里的threshold成员实际存放的值是capacity的值。因为在table还没有初始化时(table还是null),用户给定的capacity会暂存到threshold成员上去(毕竟HashMap没有一个成员叫做capacity,capacity是作为table数组的大小而隐式存在的)。else if (s > threshold)说明传入map的size都已经大于当前map的threshold了,即当前map肯定是装不下两个map的并集的,所以这里必须要执行resize操作。- 最后循环里的
putVal可能也会触发resize操作。
关于float ft = ((float)s / loadFactor) + 1.0F
这句代码最后的加1操作虽然我已经解释过了,但它也是有可能有“坏处”的。下面这段代码,如果你debug后,会看到下图:
import java.util.*;
public class test1 {
public static void main(String[] args) {
HashMap<String,Integer> oldMap = new HashMap<String,Integer>();
for(int i=0;i<12;i++){
oldMap.put(""+i,i);
}
HashMap<String,Integer> newMap = new HashMap<String,Integer>(oldMap);
System.out.println();//此处打断点
}
}
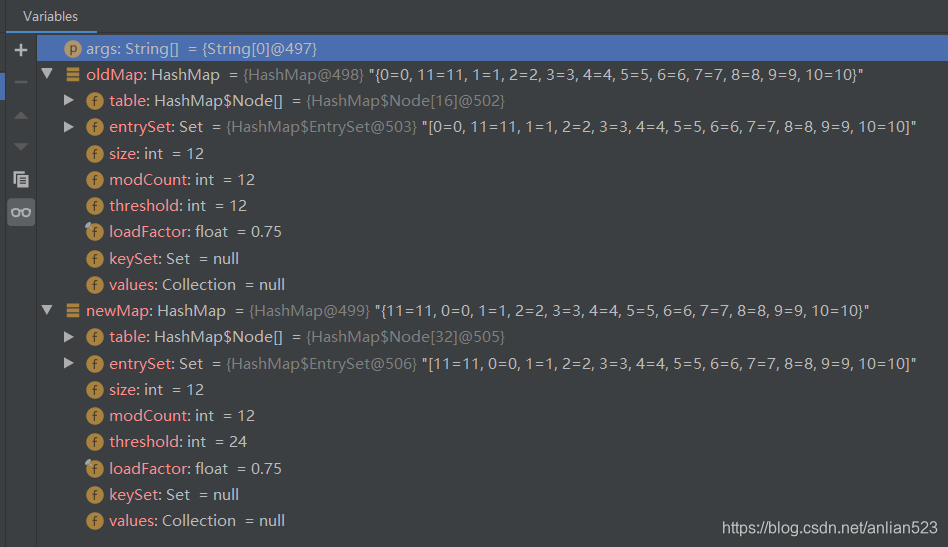
- oldMap使用的无参构造器(会使用到HashMap的默认值),所以容量是16,装载因子是0.75,阈值是12。而newMap使用的拷贝构造器,然后会调用putMapEntries,由于传入map的size是12,那么12 / 0.75=16, 16 + 1 = 17, tableSizeFor(17) = 32,所以最终造成newMap的容量是32,阈值是24。
- 这就是我说的“坏处”,newMap的size明明和oldMap的size一样,但是其容量和阈值都是oldMap的二倍了(变成了应有的二倍)。
- 可能你会想,这是为了保护另一种特例,这种特例如果不做加1操作,就会导致分配的容量不够大,所以我这种特例就得牺牲一下了。但你就算把s的值(传入map的size)从6试到12,也会发现,就算不做加1操作,分配的容量也会够大。
- 其实我们忽略了一点,就是loadfactor可能会被用户给一个奇怪的小数,因为在HashMap里,容量必须为2的幂,且默认的loadfactor又是0.75,所以算出来的阈值肯定是整数了。如果用户给一个小数,使得 capacity * loadfactor = 小数,那么这个阈值必须向下取整(反过来想,如果阈值向上取整,那岂不是使得size可能会大于了真正的threshold而不用resize,详见
resize()函数的newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);,这里的(int)ft就是向下取整)。所以反过来想,用 size / loadfactor 算出的capacity,肯定也要向上取整了。
关于else if (s > threshold) resize()
这句代码充分体现了HashMap的“懒汉模式”,因为resize是一个极其expensive的操作,应该是只在需要的时候做。
- 当s > threshold时,传入map和当前map的并集的映射数量(即size)肯定会大于当前map的阈值的,所以在循环放置新元素(最后循环的
putVal操作)之前就应该resize,因为我们已经提前知道当前map不够放的。 - 当s <= threshold时,就不会进入这个if判断,也就不会resize了。这是因为,如果传入map是当前map的子集的话,那么就肯定不需要resize的了。但这是极端情况,所以这里触发resize的任务交给
putVal。总之,这种情况最终需不需要resize是一件不确定的事情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号