Java 遍历目录下的所有文件(深度优先遍历,宽度优先遍历)
递归方法
import java.io.File;
import java.util.*;
public class test3 {
public static List<File> recurseDirs(String start,String regex) {
return recurseDirs(new File(start), regex);
}
public static List<File> recurseDirs(String start) {
return recurseDirs(new File(start), ".*");
}
public static List<File> recurseDirs(File startDir) {
return recurseDirs(startDir, ".*");
}
public static List<File> recurseDirs(File startDir, String regex) {
List<File> result = new ArrayList<File>();
if (startDir.listFiles() == null) {//防止主函数调用时给出路径不是一个有效的目录
System.out.println("这不是一个有效的目录");
return result;//直接返回空的list
}
for(File item : startDir.listFiles()) {
if(item.isDirectory()) {
result.add(item);
result.addAll(recurseDirs(item));
} else {
if(item.getName().matches(regex))
result.add(item);
}
}
return result;
}
public static void main(String[] args) {
List<File> files = recurseDirs("E:/影视作品");
for(File i:files) {
System.out.println(i);
}
}
}
其实这个例子来自JAVA编程思想——18.1.2目录实用工具——Directory类。看了书中代码着实觉得这种递归实现太优雅了,所以我改了改变成了自己的实现。
public static List<File> recurseDirs(File startDir, String regex)这个签名的方法才是主要的函数,其他的都是重载版本,regex参数就是你要设置的正则表达式,如果你设置了regex形参,那么只有符合该regex的File才会返回。- 关于递归设计,书中用的是一个作者自己写的一个TreeInfo静态内部类,它实现了一个addAll方法,但实际上它内部也用到了List接口的addAll,所以我这里就改成了使用ArrayList来存储File对象。
这个递归的精妙之处:
- 首先多亏了List接口里自带addAll这个接口,要是没有这个addAll,那么result用
File[]作为类型也一样(recurseDirs的返回值也改成File[]),然后单独写一个静态方法,可以是这样的签名public static File[] addAll(File[] a, File[] b),然后这句result.addAll(recurseDirs(item));改成result = addAll(result, recurseDirs(item))。 - 只要是调用了递归方法体,传进来的startDir必定是一个目录(isDirectory返回true),这是由循环中调用递归的前提判断来保证的。
- 在循环中,如果发现循环变量item是一个当前目录下的文件,那么执行else分支,不会调用到递归函数;如果发现循环变量item是一个当前目录下的子目录,那么执行if分支,会调用到递归函数,调用前先添加这个子目录。
其他:
- listFiles返回一个
File[],如果调用的File不是一个有效的目录,返回null。 if (startDir.listFiles() == null)分支只是为了防止主函数调用时给出路径不是一个有效的目录,如果不是有效目录且没有这个判断,下面的循环会抛出空指针异常。只要主函数给的有效目录,之后就不会出错了。
递归+限制目录深度
import java.io.File;
import java.util.*;
public class test4 {
public static List<File> recurseDirs(File startDir, int count) {
List<File> result = new ArrayList<File>();
if (count == 0) {
return result;//直接返回空的list
}
if (startDir.listFiles() == null) {//防止主函数调用时给出路径不是一个有效的目录
System.out.println("这不是一个有效的目录");
return result;//直接返回空的list
}
for(File item : startDir.listFiles()) {
if(item.isDirectory()) {
result.add(item);
result.addAll(recurseDirs(item, count - 1));
} else {
result.add(item);
}
}
return result;
}
public static void main(String[] args) {
List<File> files = recurseDirs(new File("E:/影视作品"),2);
for(File i:files) {
System.out.println(i);
}
}
}
给recurseDirs加一个参数代表递归目录的深度,为2时代表深度为2。主函数中,给的目录下的所有文件或子目录算是1的深度。
主函数中,给的目录是E:/影视作品,打印结果如下:
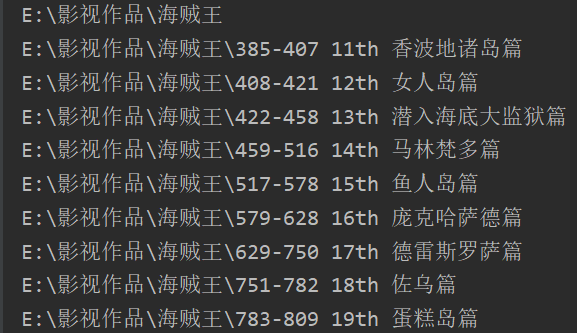
可见深度只能到2。
BFS
import java.io.File;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
public class test5 {
public static List<File> BFS(File startDir) {
List<File> result = new ArrayList<File>();
if (startDir.listFiles() == null) {//防止主函数调用时给出路径不是一个有效的目录
System.out.println("这不是一个有效的目录");
return result;//直接返回空的list
}
LinkedList<File> queue = new LinkedList<>();//用作队列
queue.addAll(Arrays.asList(startDir.listFiles()));//给队列起个头
while (!queue.isEmpty()) {//只要队列不为空
//取出队列的第一个元素
File item = queue.removeFirst();
if (item.isDirectory())//如果当前元素是目录
queue.addAll(Arrays.asList(item.listFiles()));//往队列里加入目录下的所有文件
result.add(item);//总是加入当前元素
}
return result;
}
public static void main(String[] args) {
List<File> files = BFS(new File("E:/影视作品"));
for(File i:files) {
System.out.println(i);
}
}
}
递归是深度遍历,既然深度遍历用了,那再试试宽度遍历呗。使用LinkedList用作宽度遍历中的队列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号