Java源码分析 ByteBuffer.asCharBuffer打印字符串乱码原因
当你执行如下代码时,你会发现字符串为卯浥⁴數
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
public class test2 {
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer.wrap("Some text".getBytes());
CharBuffer cb = bb.asCharBuffer();
String s = cb.toString();
System.out.print(s);
}
}

从debug视图分析

如上图可见cb对象是一个ByteBufferAsCharBufferB实例,它持有一个ByteBuffer类型的对象(实际上就是那个bb对象),也就是说,打印CharBuffer时,它的实际数据来源于它持有的那个ByteBuffer类型的对象。

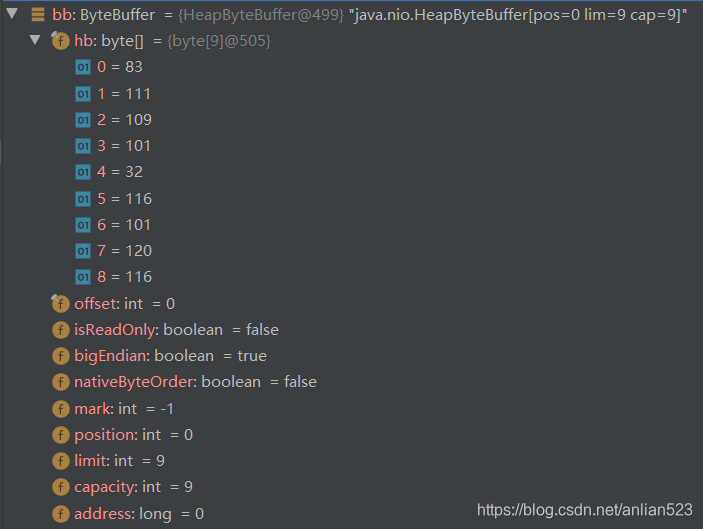
大家知道java的char类型是一个无符号的二字节整数,而s的第一个char的整数值为21359,那么它是怎么算出来的呢:
很明显是从那个bb对象持有的byte数组上算出来的,即
大端模式,是指数据的高字节保存在内存的低地址中
对于一个数组来说,0号元素相比1号元素来说肯定是低地址,而默认的是大端模式,所以83就是低地址保存着的高字节的数据。char类型是二字节大小,所以83就是那个char类型的高字节数据,进而111则是char类型的低字节数据。
从源码分析
cb对象打印出来的乱码字符串是调试器隐式调用了cb对象的toString方法,所以我们观察String s = cb.toString()的运行过程就可以了。
- bb对象是一个HeapByteBuffer实例,调用它的asCharBuffer方法后,返回一个CharBuffer类型的ByteBufferAsCharBufferB实例(最后的B代表是大端模式)。
//Buffer.java
public final int remaining() {
return limit - position;
//从上面截图可以看出,这里结果为9(limit代表一个不可能的位置,而position为0,所以是从0到8,一共9个元素)
}
//HeapByteBuffer.java
public CharBuffer asCharBuffer() {
int size = this.remaining() >> 1;//这里除以2,因为char总是2字节的,所以字节数9除以2就是字符数4
int off = offset + position();//offset代表偏移位置
return (bigEndian//默认是大端,所以三目代表式进入前者
? (CharBuffer)(new ByteBufferAsCharBufferB(this,
-1,
0,
size,//size为4
size,
off))
: (CharBuffer)(new ByteBufferAsCharBufferL(this,
-1,
0,
size,
size,
off)));
}
- cb对象是一个CharBuffer类型的ByteBufferAsCharBufferB实例,它的toString方法(继承自CharBuffer)源码如下:
//CharBuffer.java
public String toString() {
return toString(position(), limit());//它调用了一个重载的toString方法,参数分别为0和4
}
方法体中调用了一个重载的toString方法,但这个重载版本的toString方法还是一个抽象方法,所以它必定是被子类实现了的:
//CharBuffer.java
abstract String toString(int start, int end); // package-private
这个重载版本的toString方法果然在ByteBufferAsCharBufferB类里进行了实现:
//ByteBufferAsCharBufferB.java
public String toString(int start, int end) {
if ((end > limit()) || (start > end))
throw new IndexOutOfBoundsException();
try {
int len = end - start;
char[] ca = new char[len];//这里会创建一个4大小的char数组
CharBuffer cb = CharBuffer.wrap(ca);
CharBuffer db = this.duplicate();
db.position(start);//改变复制对象的position索引
db.limit(end);//改变复制对象的limit索引
cb.put(db);
return new String(ca);
} catch (StringIndexOutOfBoundsException x) {
throw new IndexOutOfBoundsException();
}
}
CharBuffer cb = CharBuffer.wrap(ca)这句执行过程如下,而返回的CharBuffer对象是一个HeapCharBuffer实例(简单理解HeapCharBuffer,它靠持有一个char数组来作为缓存):
//CharBuffer.java
public static CharBuffer wrap(char[] array) {
return wrap(array, 0, array.length);//调用下面的重载版本
}
public static CharBuffer wrap(char[] array,
int offset, int length)
{
try {
return new HeapCharBuffer(array, offset, length);//返回一个HeapCharBuffer实例
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
CharBuffer db = this.duplicate()这句则返回一个浅拷贝的ByteBufferAsCharBufferB实例。浅拷贝是因为两个ByteBufferAsCharBufferB实例持有的ByteBuffer类型成员是同一个对象。这样做只是为了不破坏掉this对象的那些记录索引的成员(比如position、limit)。
//ByteBufferAsCharBufferB.java
public CharBuffer duplicate() {
return new ByteBufferAsCharBufferB(bb,//这里是this对象的bb成员,所以是浅拷贝
//下面的是基本类型int,所以新对象的成员改变了,不会改变this对象的这些成员
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
cb.put(db)这句才是真正的关键。由于db是一个ByteBufferAsCharBufferB实例,这句调用到put(CharBuffer)版本函数,且会进入最后的else分支:
//HeapCharBuffer.java
public CharBuffer put(CharBuffer src) {
if (src instanceof HeapCharBuffer) {
if (src == this)
throw new IllegalArgumentException();
HeapCharBuffer sb = (HeapCharBuffer)src;
int n = sb.remaining();
if (n > remaining())
throw new BufferOverflowException();
System.arraycopy(sb.hb, sb.ix(sb.position()),
hb, ix(position()), n);
sb.position(sb.position() + n);
position(position() + n);
} else if (src.isDirect()) {
int n = src.remaining();
if (n > remaining())
throw new BufferOverflowException();
src.get(hb, ix(position()), n);
position(position() + n);
} else {
super.put(src);
}
return this;
}
super.put(src)会调用到直接父类CharBuffer的put(CharBuffer)版本函数:
//CharBuffer.java
public CharBuffer put(CharBuffer src) {
if (src == this)
throw new IllegalArgumentException();
if (isReadOnly())
throw new ReadOnlyBufferException();
int n = src.remaining();
if (n > remaining())
throw new BufferOverflowException();
for (int i = 0; i < n; i++)
put(src.get());
return this;
}
- 这里for循环会执行4次
put(src.get())。 - 在CharBuffer类型的src形参(是一个ByteBufferAsCharBufferB实例)上调用的get函数是这个版本
public abstract char get();,但这是个抽象函数(在CharBuffer.java里),所以它的实现在ByteBufferAsCharBufferB里:
//ByteBufferAsCharBufferB.java
protected int ix(int i) {
return (i << 1) + offset;//这里的offset是指字节的偏移量
}
public char get() {
return Bits.getCharB(bb, ix(nextGetIndex()));
}
- nextGetIndex函数的实现在
Buffer.java里,具体实现如下。
//Buffer.java
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;//返回当前position,并加1
}
- 再看ix函数的实现,将得到的position乘以2,看来这是要得到字符对应的字节数量(一个char字符有两个字节)。而且offset这里也没有乘以2,看来作为CharBuffer对象的offset成员是指的字节的偏移量。最终ix函数会返回每个字符的第一个字节的序号。
- 最后看看
Bits.getCharB(bb, ix(nextGetIndex()));这个函数的具体实现,具体如下。
//Bits.java
static char getCharB(ByteBuffer bb, int bi) {
//函数名的B代表是大端,大端模式的体现与给makeChar函数传的实参顺序有关
//第一个实参为:内存的低地址(bi 比 bi+1 小,自然是内存低地址)
//第二个实参为:内存的高地址
return makeChar(bb._get(bi ),
bb._get(bi + 1));
}
static private char makeChar(byte b1, byte b0) {
return (char)((b1 << 8) | (b0 & 0xff));
//根据上面的传参:b1是内存的低地址,b0是内存的高地址
//b1左移8位,相当于乘以2的8次方。所以b1是作为数据的高字节
//上述符合大端模式:数据的高字节保存在内存的低地址中
}
至此,ByteBuffer.asCharBuffer打印字符串乱码原因已经找到了:
"Some text".getBytes()获得字符对应的字节,但由于英文字母和空格的ASCII整数值小于(一个字节的无符号的最大范围),所以用一个字节就可以表示出来一个字符(因为用的UTF8来进行的编码)。所以getBytes获得的是9个字节,但实际上这里应该是有18个字节,应该多出来每个字符的高字节。CharBuffer cb = bb.asCharBuffer()这里,它认为每两个字节对应一个字符,所以会把字节数除以2.String s = cb.toString();这里,根据每两个字节和大小端模式,构造出来每个char。
这里再回头看一下CharBuffer.java的put(src.get());这句,上面把src.get()分析完了,这里分析下put()函数。但在CharBuffer.java里public abstract char get()是个抽象函数,而当前对象是一个HeapCharBuffer实例,所以put()函数具体实现在HeapCharBuffer里。
//HeapCharBuffer.java
protected int ix(int i) {
return i + offset;//这里的offset是指字符的偏移量
}
public CharBuffer put(char x) {
hb[ix(nextPutIndex())] = x;//调用到直接父类的nextPutIndex函数;hb是一个char数组
return this;
}
//Buffer.java
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
可见put()函数只是依次放置char到char数组里。
乱码本质原因
直接getBytes(无参数版本)时,作为英文字母的字符在encode时,本来应该扩充为二字节的,但实际上却没有进行扩充,而是把数据高字节省略掉,从而造成了打印字符串乱码。
另一种尝试
可能你会认为,如果将主函数中的字符串就设置为卯浥⁴數,那最终打印结果就能够正确了。
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
public class test2 {
public static void main(String[] args) {
ByteBuffer bb = ByteBuffer.wrap("卯浥⁴數".getBytes());
CharBuffer cb = bb.asCharBuffer();
String s = cb.toString();
System.out.print(s);
}
}

但实际上打印结果又乱码了。如下图可见,本来我们期待ByteBuffer持有的字节数组大小应该是8大小,但实际上却是12的大小,一个字符对应了3个字节。然后那个CharBuffer根据12个字节所以认为有6个字符。
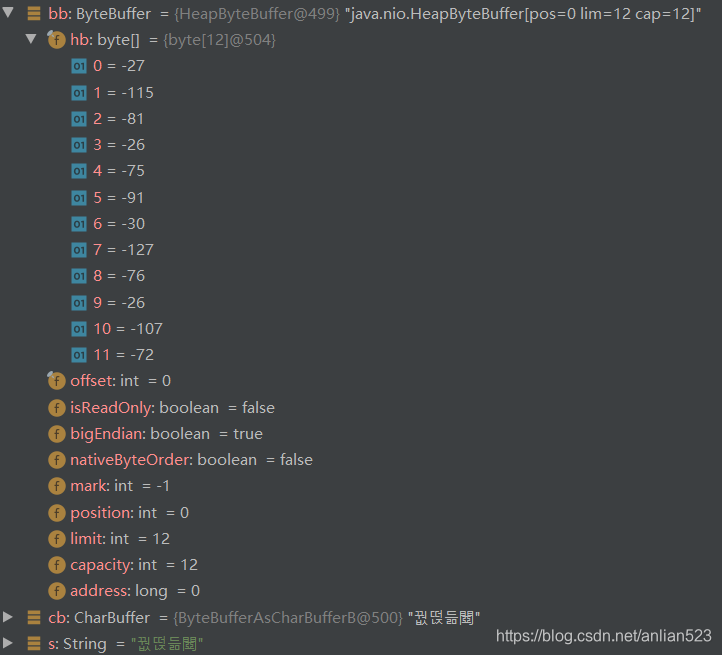
之所以打印出来只有4个字符,是因为有2个字符根本无法通过Unicode解码,或者是无法显示的字符。
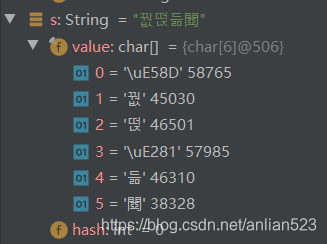
看来encode和decode时,不指定字符集,肯定会造成乱码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号