Java BIO体系详解
前言
本文讲解IO体系中的流式部分,即InputStream、OutputStream、Reader、Writer大家族。即BIO。
输入流和输出流——明确流向
总是说输入流和输出流,但是有的人可能很迷糊这流向到底是从哪里到哪里。首先要明确,输入和输出都是相对于内存而言的。
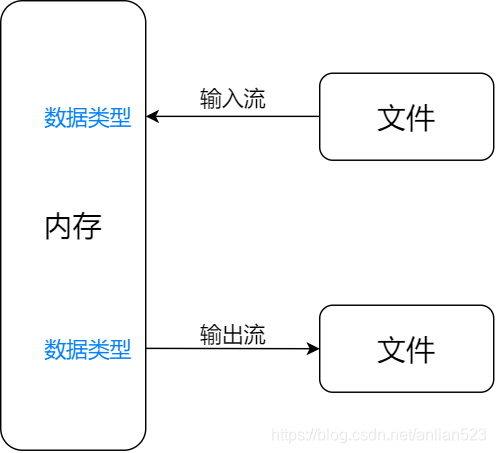
- 输入流是将数据从文件中流向内存;输出流则是将数据从内存中流向文件。
- 输入流能做的事情无非是:将文件中的数据放入java的数据类型中(比如byte、char、short、int)。
- 输出流能做的事情无非是:将java数据类型中的数据放入文件中。
- 对于程序来说:输入流是有能力产出数据的流,输出流是有能力接受数据的流。
流的特点
- 使用流的好处就是,当你获得了一个流对象后,你就不用关心与流交互的具体节点是什么了。
- 读出时,只能顺序读出;写入时,只能顺序写入。
- 一个流只能要么是输入流、要么是输出流,不可能同时具有读和写的功能。(当然这里要除了RandomAccessFile)
基类的划分
Java的BIO体系从基类来分析还是很清晰的,因为可以从数据的流向和处理的数据类型来进行分类。
| 处理字节 | 处理字符 | |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
- InputStream和OutputStream:处理的数据类型为byte。
- Reader和Writer:处理的数据类型为char。
- 总的来说,Reader/Writer相比InputStream/OutputStream算是一种升级,将当初设计得不好的地方进行了优化。
而字符流本质上来讲,是对字节流的功能拓展,因为字符流本质上也是在处理各个字节。比如FileReader的构造器,本质上也是先构造出一个FileInputStream。
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
子类的划分——实体类和装饰类
其实子类可以分为两种:实体类和装饰类和其他。因为整个IO体系中使用到了装饰器模式,所以你可以动态组装这些流以构成你想要的功能,而装饰器就类似俄罗斯套娃(禁止套娃!)。现将可以进行装饰的流称为装饰类,真正拥有交互节点(文件、网络)的类称为实体类。
实体类必须有一个真正的节点(比如文件),用来产出数据或接受数据。
而装饰类的构造器一般将一个流作为参数,所以它不用关心是否有节点,反正构造器接受的流肯定会直接或间接地包含到节点。装饰类,主要用来为流增加新功能。
InputStream的子类
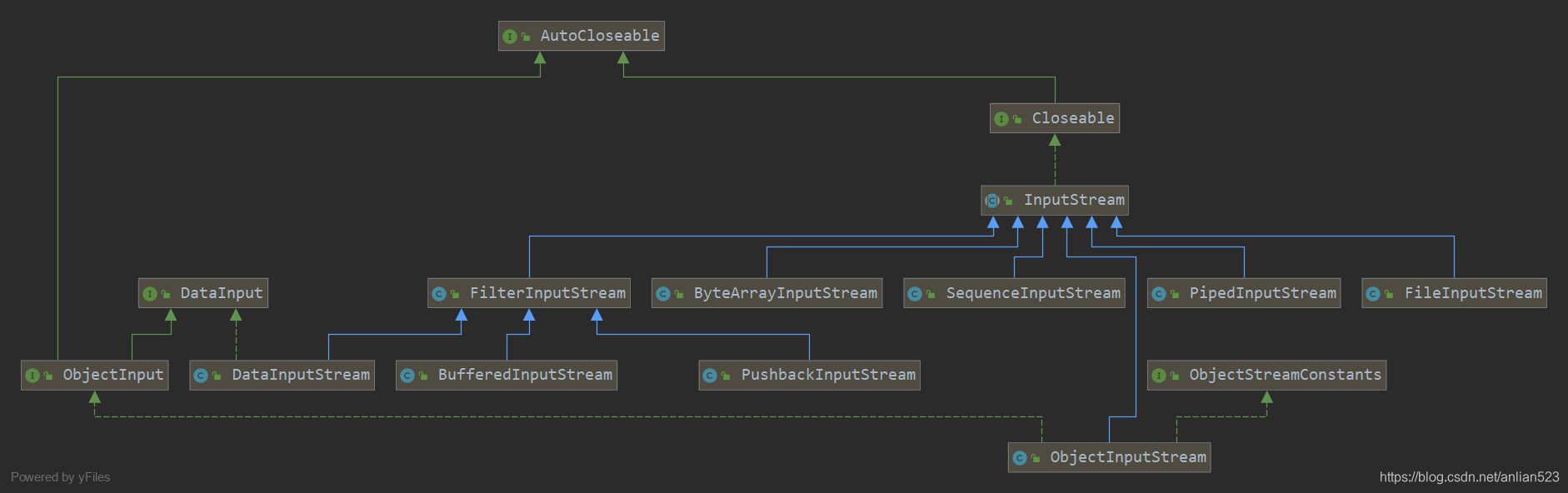
还有一些被遗弃的类(就没有体现在上图中了),以及推荐使用的类:
| Deprecated Class | Alternative |
|---|---|
| StringReader | |
| LineNumberReader |
从上图可以看出:
- InputStream有若干儿子类和孙子类。
- ByteArrayInputStream、FileInputStream都属于实体类。
- FilterInputStream及其子类和ObjectInputStream都属于装饰类。
- PipedInputStream是为了与其他线程公用管道来读取数据。
- SequenceInputStream更像是一个工具类,组合多个InputStream并依次读取。
再分别讲解:
- 从FileInputStream的成员以及构造器中可以看出,这确实是一个实体类,构造完成会持有一个file作为节点。
public class FileInputStream extends InputStream
{
private final FileDescriptor fd;
private final String path;
public FileInputStream(String name) throws FileNotFoundException {...}
public FileInputStream(File file) throws FileNotFoundException {...}
public FileInputStream(FileDescriptor fdObj) {...}
}
- 从FileInputStream的成员以及构造器中可以看出,这确实是一个实体类,构造完成会持有一个byte[]字节数组作为节点。
public class ByteArrayInputStream extends InputStream {
protected byte buf[];
public ByteArrayInputStream(byte buf[]) {...}
public ByteArrayInputStream(byte buf[], int offset, int length) {...}
}
- FilterInputStream以及它的三个子类都是属于装饰类,它们的构造器都会接受一个InputStream,接受的这个流就会被装饰掉,装饰后的效果取决你使用了哪个装饰类。
- 它们都是InputStream的子类,且构造器接受一个InputStream。这便是装饰器模式的要领:装饰者和被装饰者必须是同一个类型,且装饰者可以拓展功能。
- FilterInputStream从本质上来讲,只能算代理模式,因为它完全没有拓展任何功能。
- BufferedInputStream和PushbackInputStream为了拓展相应的功能,自己新加了一个字节数组成员。
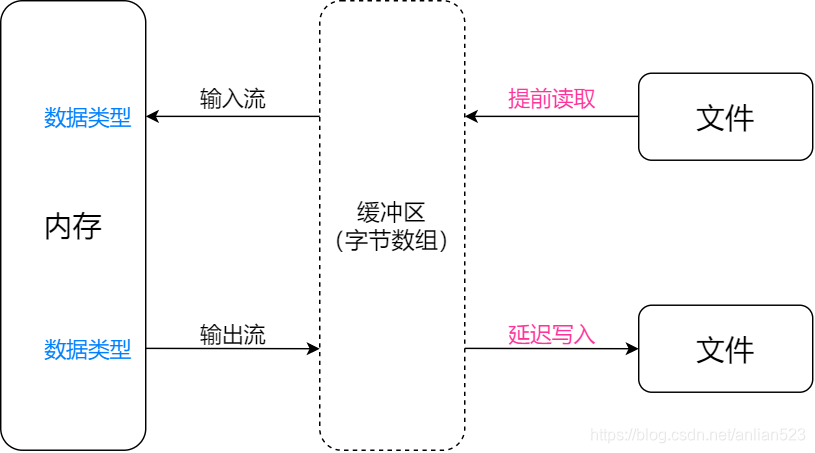
- BufferedInputStream则是为了让读写更快,具体做法则是通过让程序不再直接与文件打交道(也就不必每次程序执行读写时,就真的执行一次物理读写动作),而是与缓冲区打交道。效果如下图,读取数据时,都是从缓冲区里读取,而缓冲区里的数据则都是提前读取一部分了的;写入数据时,都是往缓冲区里写入,而真正的物理写动作则是在缓冲区的数据满到一定程度后才执行的。
//FilterInputStream
public class FilterInputStream extends InputStream {
protected volatile InputStream in;
protected FilterInputStream(InputStream in) {
this.in = in;
}
}
//DataInputStream构造器
public DataInputStream(InputStream in) {
super(in);
}
//BufferedInputStream构造器
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
//PushbackInputStream构造器
public PushbackInputStream(InputStream in) {
this(in, 1);
}
public PushbackInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("size <= 0");
}
this.buf = new byte[size];
this.pos = size;
}
- ObjectInputStream也是一个装饰类,但它没有继承FilterInputStream。
public ObjectInputStream(InputStream in) throws IOException {...}
OutputStream的子类
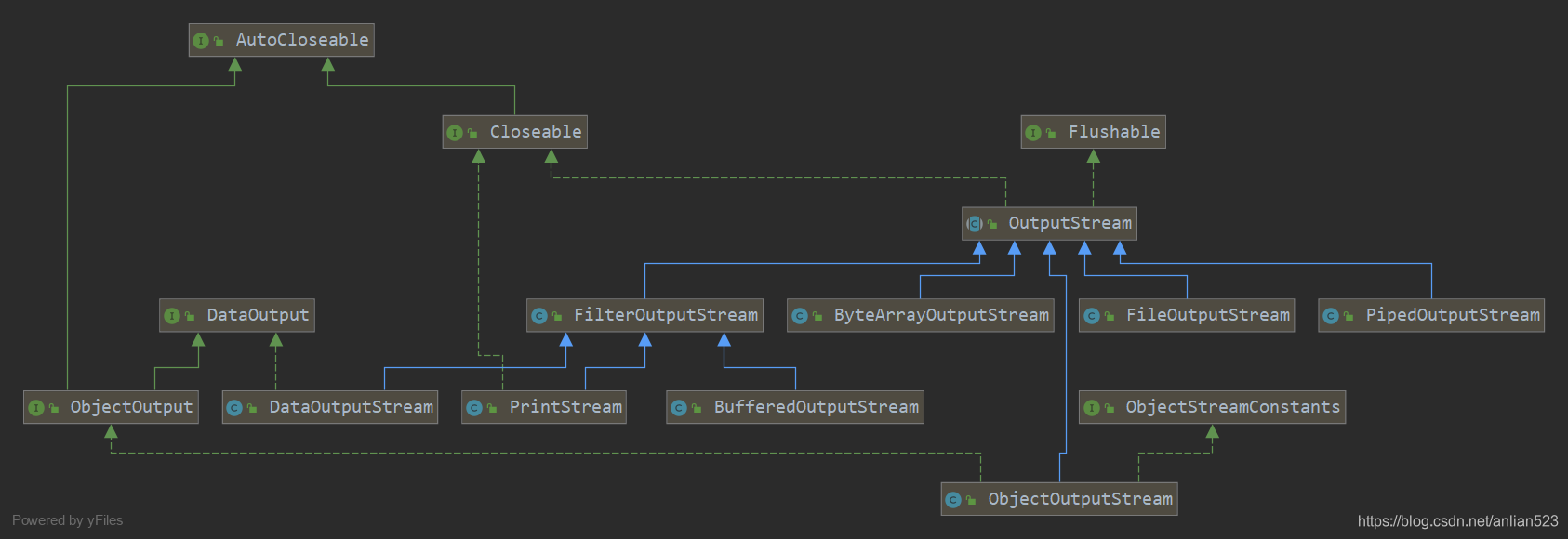
- ByteArrayOutputStream、FileOutputStream是实体类。
- FilterOutputStream及其子类们和ObjectOutputStream都是装饰类。
- PipedOutputStream是线程用来输出数据的。
Reader的子类
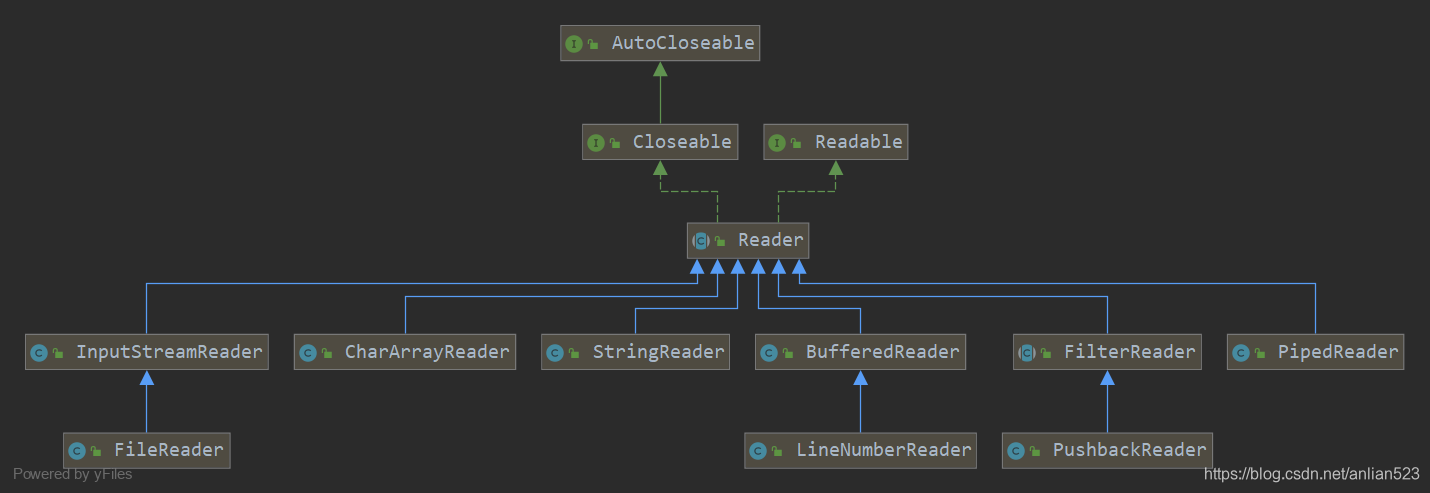
- CharArrayReader、StringReader是实体类。
- BufferedReader及其子类是装饰类。(注意BufferedReader并没有继承自FilterReader)
- FilterReader及其子类也是装饰类。注意FilterReader算是jdk提供给你自定义装饰类的标准父类,而且它一个抽象类,让你来继承用的。
- InputStreamReader及其子类也是装饰类,但它是用来装饰InputStream的,所以说它是用来将InputStream转换为Reader的。
- PipedReader是线程用来读取数据的。
Writer的子类
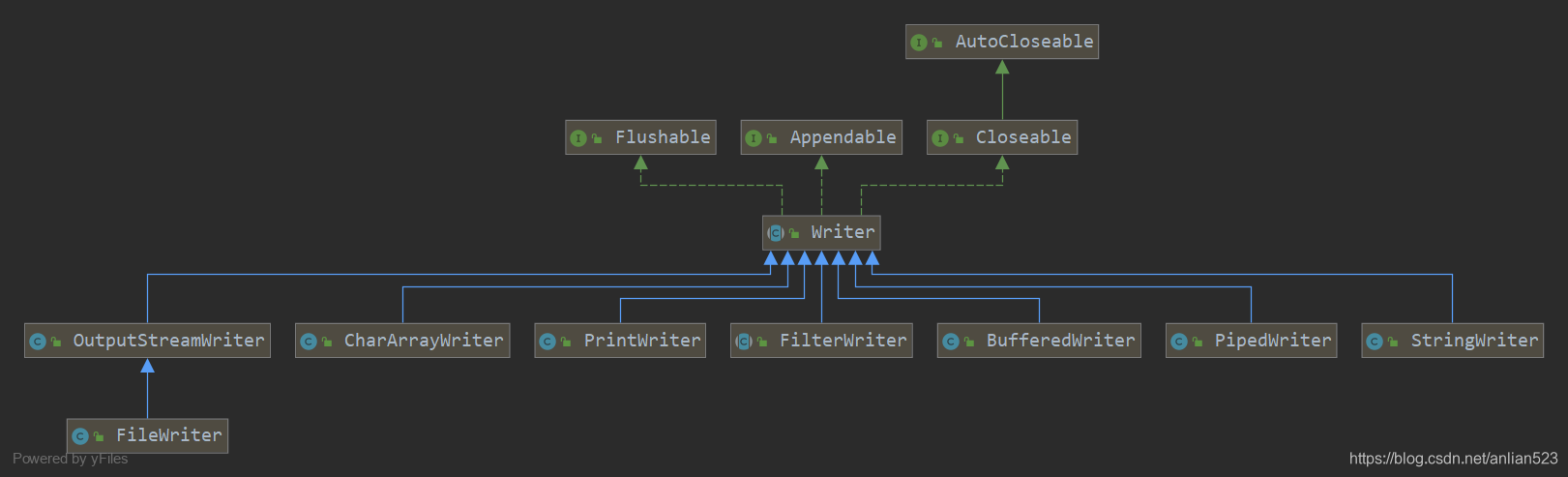
- CharArrayWriter、StringWriter是实体类。
- BufferedWriter是装饰类。(注意它也没有继承FilterWriter)
- FilterWriter是装饰类,注意它是抽象类,用来继承实现自定义装饰类的。
- PrintWriter也是装饰类,它功能强大,一般作为装饰器模式的最外层。
- OutputStreamWriter及其子类也是装饰类,但它是用来装饰OutputStream的,所以说它是用来将OutputStream转换为Writer的。
- PipedWriter是线程用来输出数据的。
典型使用方法
缓冲读取File(使用BufferedReader)
import java.io.*;
public class BufferedInputFile {
// Throw exceptions to console:
public static String read(String filename) throws IOException {
// Reading input by lines:
BufferedReader in = new BufferedReader(
new FileReader(filename));
String s;
StringBuilder sb = new StringBuilder();
while((s = in.readLine())!= null)
sb.append(s + "\n");
in.close();
return sb.toString();
}
public static String read_Deprecated(String filename) throws IOException {
// Reading input by lines:
DataInputStream in = new DataInputStream(
new FileInputStream(filename));
String s;
StringBuilder sb = new StringBuilder();
while((s = in.readLine())!= null)//readLine是Deprecated的
sb.append(s + "\n");
in.close();
return sb.toString();
}
public static void main(String[] args)
throws IOException {
// 注意如果报错文件找不到,那么根据根目录看自己文件的位置
System.out.println("此工程的根目录:"+System.getProperty("user.dir"));
System.out.print(read("src/BufferedInputFile.java"));
System.out.print(read_Deprecated("src/BufferedInputFile.java"));
}
} /* (Execute to see output) *///:~
- 使用了BufferedReader来装饰FileReader。
- 如果报错FileNotFoundException,那么注意是你给的文件路径不正确,请根据工程根目录修正路径。
- 对比两个静态函数,read函数能够正常读取;read_Deprecated函数在遇到中文字符时会出错(java文件一般是用utf-8来存代码的,而中文则一个汉字三个字节,DataInputStream遇到多字节存储的字符时就会出错,因为它认为字符都是ASCII字符即都是单字节的)。
- 对于readLine方法,要使用BufferedReader的,而不是DataInputStream的。
| Deprecated Method | Alternative |
|---|---|
| String BufferedReader.readLine() |
装饰InputStream类型的System.in
结合上例例子,首先是错误示例:
import java.io.*;
public class test2 {
public static void main(String[] args) throws IOException {
DataInputStream in = new DataInputStream(System.in);
String s;
while((s=in.readLine()) !=null) {
System.out.println(s);
}
}
}
可见打印结果不对。
然后是正确示例:使用了BufferedReader来装饰InputStreamReader
import java.io.*;
public class test2 {
public static void main(String[] args) throws IOException {
// 通过InputStreamReader将一个InputStream转换为Reader
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
String s;
while((s=in.readLine()) !=null) {
System.out.println(s);
}
}
}

从内存中的String读取(必然使用StringReader)
使用StringReader
import java.io.*;
public class MemoryInput {
public static void main(String[] args)
throws IOException {
//注意StringReader构造器只是需要一个String
StringReader in = new StringReader(
BufferedInputFile.read("src/MemoryInput.java"));
int c;
while((c = in.read()) != -1)
System.out.print((char)c);
}
} /* (Execute to see output) *///:~
上面程序能够将文本一个字符一个字符地打印出来。
使用StringReader打印两遍
import java.io.*;
public class MemoryInput {
public static void main(String[] args)
throws IOException {
StringReader in = new StringReader(
BufferedInputFile.read("src/MemoryInput.java"));
int c;
while((c = in.read()) != -1)
System.out.print((char)c);
in.reset();
while((c = in.read()) != -1)
System.out.print((char)c);
}
} /* (Execute to see output) *///:~
- 上面程序能够打印两遍代码。
- 如果没有这句
in.reset();,那么只能打印一遍,因为流已经用完了。 - 在最开始读取之前,不用调用
in.mark(),也能起到作用。
使用BufferedReader打印两遍
import java.io.*;
public class MemoryInput {
public static void main(String[] args)
throws IOException {
//注意StringReader构造器只是需要一个String
BufferedReader in = new BufferedReader(new StringReader(
BufferedInputFile.read("src/MemoryInput.java")));
in.mark(BufferedInputFile.read("src/MemoryInput.java").length()+1);
int c;
while((c = in.read()) != -1)
System.out.print((char)c);
System.out.println("========================我是分割线==========================");
in.reset();
String s;
while((s = in.readLine()) != null) {
System.out.println(s);
}
}
} /* (Execute to see output) *///:~
- 程序使用了BufferedReader来装饰StringReader。此版本可以将Reader流用两遍,打印MemoryInput.java两次。
- 如果没有
in.mark(BufferedInputFile.read("src/MemoryInput.java").length()+1);和in.reset();这两句,第二遍就无法打印出东西,因为流已经用完了。 - mark函数的参数使用了
String.length(),这很自然,因为Reader就是处理字符的流,length返回的也是字符个数。mark函数的参数,必须加1,不然reset时就会报错。 - 由于使用了BufferedReader,所以也可以使用readLine方法了。(相比笨拙的read方法)
从内存中的byte[ ]读取(必然使用ByteArrayInputStream)
import java.io.*;
public class FormattedMemoryInput {
public static void main(String[] args) throws IOException {
try {
DataInputStream in = new DataInputStream(
new ByteArrayInputStream("test测试\n".getBytes()));
while(true)
System.out.print((char)in.readByte());
} catch(EOFException e) {
System.err.println("End of stream");
}
}
} /* (Execute to see output) *///:~
- 此程序使用了DataInputStream来装饰ByteArrayInputStream。打印时使用了readByte来读取每一个字节,再通过强转char来打印。
- 由于中文字符在getBytes后一个字符肯定对应多个字节,且getBytes默认使用UTF-8来encode,所以在读取到中文字符的对应若干字节时,肯定会打印乱码。
- 一直读取下去,如果读了最后一个字节后再次读取,就会抛出EOFException。(这看起来很烦人)
import java.io.*;
public class FormattedMemoryInput {
public static void main(String[] args) throws IOException {
try {
DataInputStream in = new DataInputStream(
new ByteArrayInputStream("test测试\n".getBytes("UTF-16BE")));
while(true)
System.out.print(in.readChar());
} catch(EOFException e) {
System.err.println("End of stream");
}
}
} /* (Execute to see output) *///:~

- 此程序克服了读取中文字符乱码的情况。
- readChar在读取时,是以Unicode来读取的,即每两个字节对应到一个char。
getBytes("UTF-16BE")使得encode时,使用UTF-16来编码,BE代表大端模式。- 当Unicode<=
\uFFFF时,Unicode码就是UTF-16的存储,所以行得通。
import java.io.*;
public class FormattedMemoryInput {
public static void main(String[] args) throws IOException {
DataInputStream in = new DataInputStream(
new ByteArrayInputStream("test测试\n".getBytes("UTF-16BE")));
while(in.available() != 0)
System.out.print(in.readChar());
}
} /* (Execute to see output) *///:~
此程序终于摆脱了EOFException,通过提前判断available。available返回为0代表没有字节可以读取了。但注意当available遇到网络IO时,就不好用了。
将字符串写入File(使用PrintWriter)
import java.io.*;
public class test2 {
public static void main(String[] args) throws IOException {
PrintWriter out = new PrintWriter(
new BufferedWriter(new FileWriter("BasicFileOutput.out")));
out.println("我是第一行");
out.println(1111);
out.println(3.14159);
out.close();
// Show the stored file:
BufferedReader in = new BufferedReader(new FileReader("BasicFileOutput.out"));
System.out.println(in.readLine());
System.out.println(in.readLine());
System.out.println(in.readLine());
}
}
- 使用了装饰类BufferedWriter来装饰FileWriter,这就使得写入时先写入到缓冲区里。
- PrintWriter装饰在最外面,因为它有很多方便的方法,比如print、println方法有很多重载版本。
- PrintWriter也有很多重载版本的构造器:
public PrintWriter(String fileName) throws FileNotFoundException {
this(new BufferedWriter(new OutputStreamWriter(new FileOutputStream(fileName))),
false);
}
public PrintWriter(OutputStream out) {
this(out, false);//调用下面的构造器
}
public PrintWriter(OutputStream out, boolean autoFlush) {
this(new BufferedWriter(new OutputStreamWriter(out)), autoFlush);
// save print stream for error propagation
if (out instanceof java.io.PrintStream) {
psOut = (PrintStream) out;
}
}
- 不管是String版的还是OutputStream版的构造器,它都自动为我们加上了缓冲功能(BufferedWriter)。
将Java数据类型写入File(使用DataOutputStream)
import java.io.*;
public class StoringAndRecoveringData {
public static void main(String[] args) throws IOException {
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("Data.txt")));
out.writeDouble(3.14159);//各种重载版本
out.writeUTF("That was pi");
out.writeDouble(1.41413);
out.writeUTF("Square root of 2");
out.close();
DataInputStream in = new DataInputStream(
new BufferedInputStream(
new FileInputStream("Data.txt")));
System.out.println(in.readDouble());
// Only readUTF() will recover the
// Java-UTF String properly:
System.out.println(in.readUTF());
System.out.println(in.readDouble());
System.out.println(in.readUTF());
}
} /* Output:
3.14159
That was pi
1.41413
Square root of 2
*///:~
- 这句
new DataOutputStream( new BufferedOutputStream( new FileOutputStream("Data.txt")))中,装饰类BufferedOutputStream起到了缓冲作用,DataOutputStream负责把各种数据类型转换为对应的内存存储字节。 - 注意writeUTF可能不大一样,因为字符串本质是char数组,而java的char的底层存储是Unicode码。但writeUTF的实现并不是直接存入Unicode码,而是通过字符集UTF-8来映射到字节,再存入文件。
- writeUTF在写入UTF-8的映射字节之前,会先写入字符数量。这很合理,对于这种不定长的数据类型,首先给出长度是必须的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号