Hbase RIT 故障修复
业务场景:
CDH集群
RocketMQ+Storm+Hbase
组件版本:
RocketMQ:3.4.6
Storm:1.2.1
Hbase:1.2.1
1. 问题描述
4月15号早上发现业务系统前一天数据量明显偏低,查看系统发现storm入Hbase的TPS很低,甚至为0。
2. 问题定位
通过查看Hbase和Storm监控页面,发现dscn18节点不在服务中,远程连接比较卡顿,去机房查看没有报警,通过终端查看HRegionServer和Supervisor进程都在,15号上午11点多查看系统日志:/var/log/message:
系统日志:
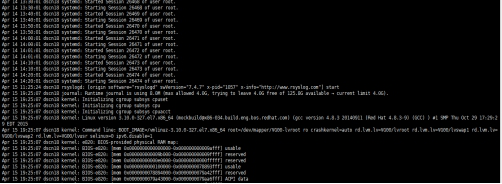
重启后,日志变为正常

综上判断可能是因为网络通信原因导致dscn18节点异常。
Hbase日志:显示dscn18,region已下线

Storm日志:显示连接超时
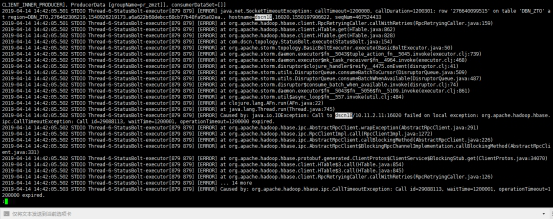
Hbase监控页面:RIT问题
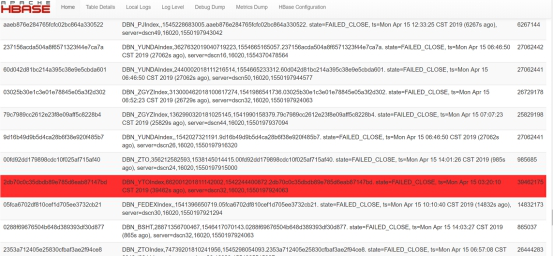
综上,可判断,由于dscn18节点连接异常,导致当前节点Hbase和Storm的服务异常,另外Hbase出现RIT,会影响Hbase的写入。
3. 解决过程
当时尝试重启拓扑,但写入TPS很低,后来将dscn18的Regionserver下线,效果仍不理想,最后决定做Hbase在线修复(dscn18已下线):
当时Hbase状态:

步骤:
1. hbase hbck 检查输出所以ERROR信息,每个ERROR都会说明错误信息。
2. hbase hbck -fixTableOrphans 先修复tableinfo缺失问题,根据内存cache或者hdfs table 目录结构,重新生成tableinfo文件。
3. hbase hbck -fixHdfsOrphans 修复regioninfo缺失问题,根据region目录下的hfile重新生成regioninfo文件。
4. hbase hbck -fixHdfsOverlaps 修复region重叠问题,merge重叠的region为一个region目录,并从新生成一个regioninfo。
5. hbase hbck -fixHdfsHoles 修复region缺失,利用缺失的rowkey范围边界,生成新的region目录以及regioninfo填补这个空洞。
6. hbase hbck -fixMeta 修复meta表信息,利用regioninfo信息,重新生成对应meta row填写到meta表中,并为其填写默认的分配regionserver。
7. hbase hbck -fixAssignments 把这些offline的region触发上线,当region开始重新open 上线的时候,会被重新分配到真实的RegionServer上 , 并更新meta表上对应的行信息。
另外,当执行完所有修复步骤后仍然有:
ERROR: Empty REGIONINFO_QUALIFIER found in hbase:meta
执行:
hbase hbck -fixEmptyMetaCells
当时修复了近三个小时,修复完成后,重启了Hbase,RIT异常解决了,再次检查出现了新的问题:
1、元数据缺失

2、region重叠
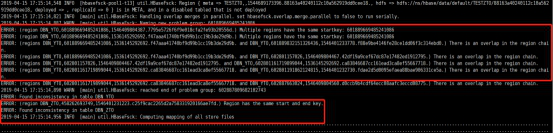
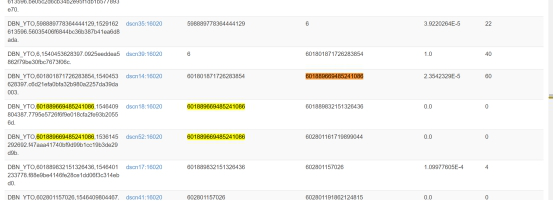
再利用之前的修复命令无法修复。通过协商得到解决办法:
针对1:
通过执行hbase hbck -fixEmptyMetaCells
修复 ERROR: Empty REGIONINFO_QUALIFIER found in hbase:meta
针对2:
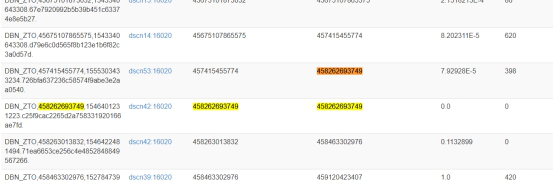
delete 'hbase:meta','DBN_YTO,601889669485241086,1536145292692.f47aaa41740bf9d99b1cc19b3de29d9b.','info:regioninfo'
delete 'hbase:meta','DBN_YTO,601889669485241086,1546409804387.7795e5726f6f9e018cfa2fe93b20556d.','info:regioninfo'
hdfs dfs -rm -r /hbase/data/default/DBN_YTO/f47aaa41740bf9d99b1cc19b3de29d9b
hdfs dfs -rm -r /hbase/data/default/DBN_YTO/7795e5726f6f9e018cfa2fe93b20556d
最后执行:
hbase hbck -fixAssignments -fixMeta -fixHdfsHoles

Hbase状态为正常,到此Hbase修复完毕!
之后重启合并Storm,个别端口连接被占用,重启Storm后检查无僵尸进程,最终将worker数由400改为340(17个Storm节点),任务启动成功,总TPS达到8万左右,到此问题解决完毕。
4. 总结
Hbase在线修复之前首先保证停掉相关业务,并且确保所有region都在线,否则修复可能会产生重复region,另外确保hbase根目录下文件没有损坏丢失,如果有,先移除掉,再修复。

移除命令:
hdfs fsck -delete
/hbase/back/SJYB_FEDEX/fedex_back/e90da00b658869d9e8ec90b871637adc/if/5612ded9b14341e19160bdc7238bf4da
引用:https://www.cnblogs.com/changsblogs/p/12145338.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号