基于python的信用评分模型
随着金融知识的普及,越来越多的人开始改变了自己的消费观念,以前是“先储蓄后消费”,现在是“先消费后还钱”,不得不说,这种观念的改变使得人们的物质生活开始变得更丰富,但与此同时也带来了一些问题:部分人开始还不起款了。在贷款供应端就涉及到了信用评分的问题。
1.背景
Give me some credit是Kaggle上关于信用评分的项目,通过改进信用评分技术,预测未来两年借款人会遇到财务困境的可能性。银行在市场经济中发挥关键作用。 他们决定谁可以获得融资,以及以何种条件进行投资决策。 为了市场和社会的运作,个人和公司需要获得信贷。信用评分算法可以猜测违约概率,这是银行用于确定是否应授予贷款的方法。目标是建立一个借款人可以用来帮助做出最佳财务决策的模型。
#导入相关包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("C:\\Users\\Administrator\\Desktop\\Give me some credit data\\cs-training.csv",engine = "python")
data.describe()
2.数据获取
变量解释:

3.数据预处理
在对数据进行处理之前,我们首先对整体情况进行概览。
data = pd.read_csv("C:\\Users\\Administrator\\Desktop\\give me some credit\\cs-training.csv",engine = "python")
data.describe()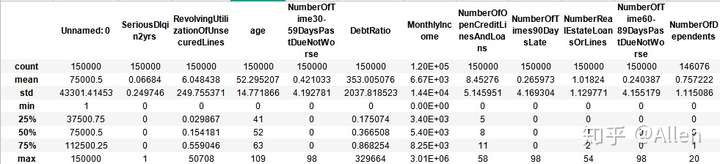
从上图可知,变量MonthlyIncome和NumberOfDependents存在缺失,变量MonthlyIncome共有缺失值29731个,NumberOfDependents有3924个缺失值。
3.1缺失值处理
这种情况在现实问题中非常普遍,这会导致一些不能处理缺失值的分析方法无法应用,因此,在信用风险评级模型开发的第一步我们就要进行缺失值处理。缺失值处理的方法,包括如下几种。
(1) 直接删除含有缺失值的样本。
(2) 根据样本之间的相似性填补缺失值。
(3) 根据变量之间的相关关系填补缺失值。
变量MonthlyIncome缺失率比较大,所以我们根据变量之间的相关关系填补缺失值,我们采用随机森林法:
# 用随机森林对缺失值进行预测
from sklearn.ensemble import RandomForestRegressor
# 预测填充函数
def rf_filling(df):
# 处理数集
process_miss = df.iloc[:,[5,0,1,2,3,4,6,7,8,9]]
#分成已知特征与未知特征
known = process_miss[process_miss.MonthlyIncome.notnull()].as_matrix()
unknown = process_miss[process_miss.MonthlyIncome.isnull()].as_matrix()
#X,要训练的特征
X = known[:,1:]
#y ,结果标签
y = known[:,0]
#训练模型
rf = RandomForestRegressor(random_state=0,n_estimators=200,max_depth=3,n_jobs=-1)
rf.fit(X,y)
#预测缺失值
pred = rf.predict( unknown[:,1:]).round(0)
#补缺缺失值
df.loc[df['MonthlyIncome'].isnull(),'MonthlyIncome'] = pred
return df
data = rf_filling(data)NumberOfDependents变量缺失值比较少,对总体模型不会造成太大影响。首先我们先通过统计描述查看家属人数列数据。
data.NumberOfDependents.value_counts()
0.0 86902
1.0 26316
2.0 19522
3.0 9483
4.0 2862
5.0 746
6.0 158
7.0 51
8.0 24
9.0 5
10.0 5
13.0 1
20.0 1
Name: NumberOfDependents, dtype: int64再通过图像描述
sns.countplot(x = 'NumberOfDependents',data = data)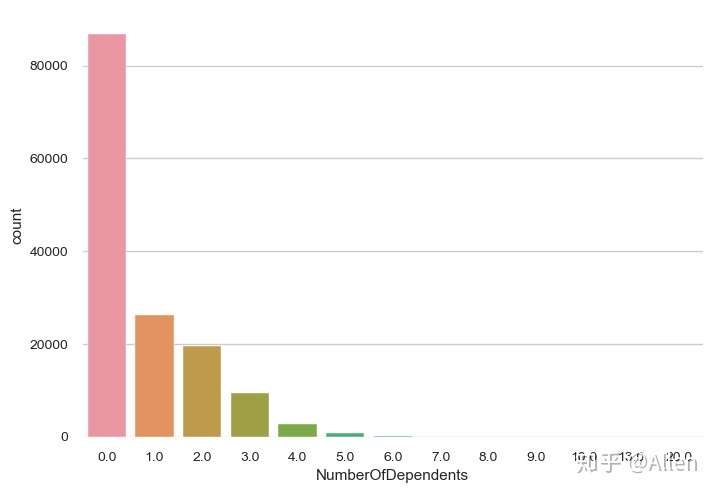
可以看到这一列的数据主要是0、1、2、3、4,因此这一列额Na值我们从[0,1,2,3,4]中随机抽取数值进行填充。
Dependents = pd.Series([0,1,2,3,4])
for i in data['NumberOfDependents'][data['NumberOfDependents'].isnull()].index:
data['NumberOfDependents'][i] = Dependents.sample(1)处理异常值,根据分布情况可以看出,家庭人口数超过8人的非常少,再结合生活常识,将超过8人的全部用8代替
data['NumberOfDependents'][data['NumberOfDependents']>8] = 8
对缺失值处理完之后,删除重复项。
data = data.drop_duplicates() #删除重复值
3.2异常值处理
处理完缺失值之后我们还需要对异常值进行处理。异常值是明显偏离大多数样本抽样数据的数值。
3.2.1年龄
首先我们发现年龄列age中存在0数值,明显是异常值,将其直接剔除。
我们先使用探索性分析来查看age列的分布情况。
fig = plt.figure()
ax1 = plt.subplot()
ax1.boxplot(data['age'])
ax1.set_xticklabels(['age'])
plt.show()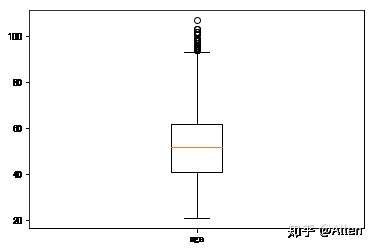
我们认为年龄应该在0-100之间,之外的数据我们剔除。
data = data[data['age']>0]
data = data[data['age']<100]
3.2.2
对于RevolvingUtilizationOfUnsecuredLines(可用额度比值)及DebtRatio(负债率)而言,箱线图表示如下:
fig = plt.figure()
x1 = data['RevolvingUtilizationOfUnsecuredLines']
x2 = data['DebtRatio']
ax = fig.add_subplot(111)
ax.boxplot([x1,x2])
ax.set_xticklabels(['RevolvingUtilizationOfUnsecuredLines','DebtRatio'])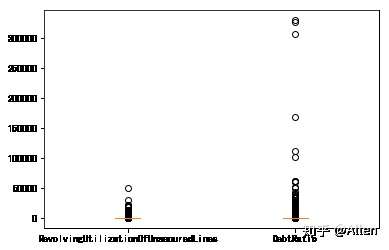
上述两个变量的数值类型均是百分比,故将大于1的值全部删除。
data = data[data['RevolvingUtilizationOfUnsecuredLines']>=0]
data = data[data['RevolvingUtilizationOfUnsecuredLines']<=1]
data = data[data['DebtRatio']>=0]
data = data[data['DebtRatio']<=1]
3.2.3
对于变量NumberOfTime30-59DaysPastDueNotWorse(逾期30-59天笔数)、NumberOfTimes90DaysLate(逾期90天笔数)、NumberOfTime60-89DaysPastDueNotWorse(逾期60-89天笔数),箱型图分析如下。
fig = plt.figure()
x1 = data['NumberOfTime30-59DaysPastDueNotWorse']
x2 = data['NumberOfTimes90DaysLate']
x3 = data['NumberOfTime60-89DaysPastDueNotWorse']
ax = fig.add_subplot(111)
ax.boxplot([x1,x2,x3])
ax.set_xticklabels(['NumberOfTime30-59DaysPastDueNotWorse','DebtRatio','NumberOfTime60-89DaysPastDueNotWorse'])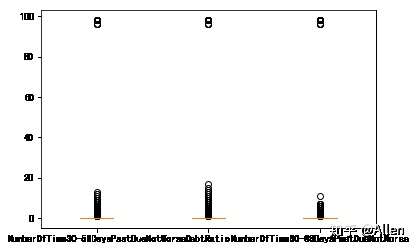
这几个变量有两个异常值96、98,将其删除。
data = data[data['NumberOfTime30-59DaysPastDueNotWorse']!=96]
data = data[data['NumberOfTime30-59DaysPastDueNotWorse']!=98]
data = data[data['NumberOfTimes90DaysLate']!=96]
data = data[data['NumberOfTimes90DaysLate']!=98]
data = data[data['NumberOfTime60-89DaysPastDueNotWorse']!=96]
data = data[data['NumberOfTime60-89DaysPastDueNotWorse']!=98]
3.2.4月收入
虽然我们在前面填补了月收入的数据,但是可以看到其中的一些数据还是异常的,我们先通过图形来分析一下。
import seaborn as sns
sns.set_style("whitegrid")
sns.boxplot(x = data.MonthlyIncome)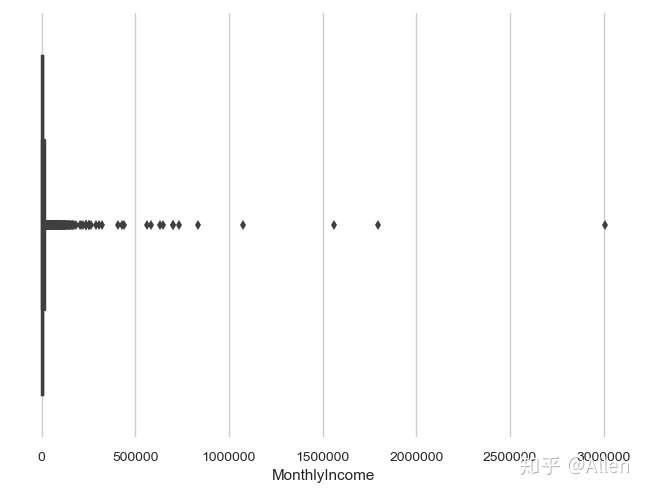
初步观察,月收入大多集中在500000以内,我们再统计超过500000的个数。
(data['MonthlyIncome']>500000).sum()结果显示为 12
说明这12个值可能为异常值,我们使用500000来替换它们,不影响分析的结果。
data["MonthlyIncome"][data["MonthlyIncome"]>500000] = 500000
4.探索性分析
4.1好坏客户整体情况
考虑到实际分类中,一般正常客户为1,违约客户为0,所以我们需要先转换客户分类列数据。
data['SeriousDlqin2yrs'] = 1-data['SeriousDlqin2yrs'] #转换0、1
grouped = data['SeriousDlqin2yrs'].groupby(data['SeriousDlqin2yrs']).count()
print("不良客户占比:",(grouped[0]/grouped[1])*100,"%")
grouped.plot(kind = 'bar')结果显示不良客户占比为:6.337390508687819 %
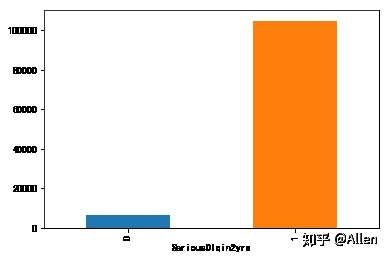
这里明显可以看出这一列存在类失衡的问题,在后续的建模过程中可使用class_weight = 'balanced'来解决这个问题。
4.2客户年龄分布
查看年龄变量分布状态
sns.distplot(data['age'])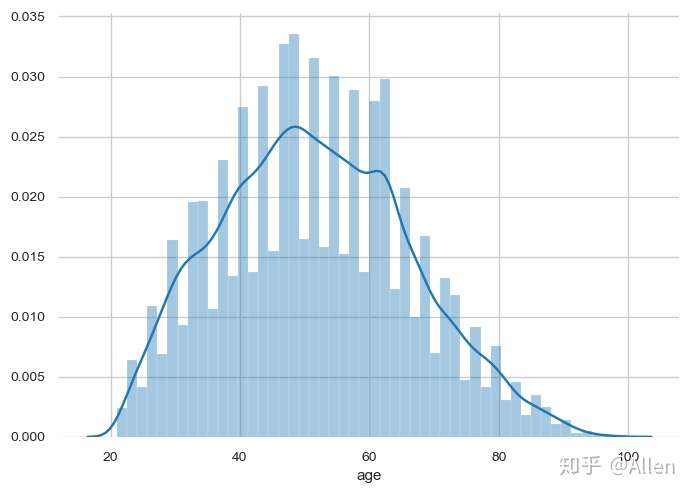
年龄分布符合正态分布,对后续结果影响不大。
4.3相关性分析
corr = data.corr()
corr
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(1,1,1)
sns.heatmap(corr,annot = True,cmap = 'rainbow',ax = ax1)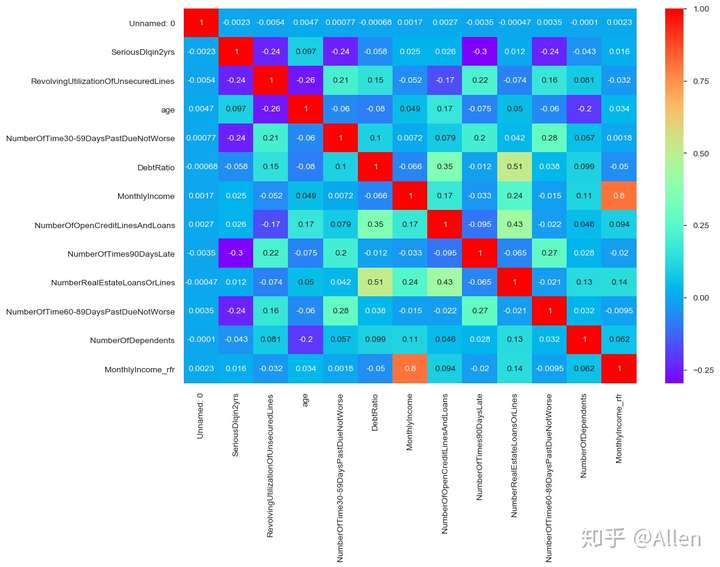
由上图可以看出,各变量之间的相关性是非常小的,可以初步判断不存在多重共线性问题。
4.4 数据切分
from sklearn.model_selection import train_test_split
Y = data['SeriousDlqin2yrs']
X=data.iloc[:,1:]
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size = 0.8,random_state=0)
train = pd.concat([Y_train,X_train], axis =1)
test = pd.concat([Y_test,X_test], axis =1)
train = train.reset_index(drop=True)
test = test.reset_index(drop=True)
#保留一份测试数据集,后面生成评分卡
test.to_csv('origin_test.csv', index=False)5.构建模型
5.1特征选择
特征选择对于模型的准确使用至关重要,在建立评分卡的时候我们使用IV值来筛选特征,具体的IV值和WOE计算如下。
5.1.1特征分箱
特征分箱指的是将连续变量离散化或者多状态的离散变量合并成少状态。相对于连续变量,离散特征的增加或者减少相对容易,易于模型的快速迭代,离散化后的特征对于异常数据有很强的鲁棒性(模型结果不受异常数据过多的影响),能够减少未离散化之前异常值对模型的干扰,同时离散化后可以进行特征交叉。本文选取的模型算法为逻辑回归,逻辑回归属于广义线性模型,表达能力有限。而将单变量离散化之后,每个变量有单独的权重,相当于为模型引入非线性,提升了模型的表达能力,同时也降低了模型过拟合的风险。
特征分箱常用的方法有如下:有监督的Best-KS,卡方分箱,无监督的等频,等距,聚类等。根据不同的数据采用不同的分箱方式。
5.1.1.1连续变量特征分箱
假设因变量为优质客户以及不良客户,其中1为优质客户,0为违约客户。
实现连续型变量单调分箱,在等频的基础上:其中DF表示导入的数据,Y是因变量的字段名,X是自变量的字段名。
import scipy.stats as stats
def monoto_bin(Y, X, n):
r = 0
total_good = Y.sum()
total_bad =Y.count()-total_good
while np.abs(r) < 1:
d1 = pd.DataFrame({"X": X, "Y": Y, "Bucket": pd.qcut(X, n)})
d2 = d1.groupby('Bucket', as_index = True)
r, p = stats.spearmanr(d2.mean().X, d2.mean().Y)
n = n - 1
d3 = pd.DataFrame(d2.min().X, columns = ['min_' + X.name])
d3['min_' + X.name] = d2.min().X
d3['max_' + X.name] = d2.max().X
d3[Y.name] = d2.sum().Y
d3['total'] = d2.count().Y
#d3[Y.name + '_rate'] = d2.mean().Y
#好坏比,求woe,证据权重,自变量对目标变量有没有影响,什么影响
d3['goodattr']=d3[Y.name]/total_good
d3['badattr']=(d3['total']-d3[Y.name])/total_bad
d3['woe'] = np.log(d3['goodattr']/d3['badattr'])
#iv,信息值,自变量对于目标变量的影响程度
iv = ((d3['goodattr']-d3[