数据结构与算法之概念
1. 数据结构
存储、组织数据的方式 包括数组、链表、堆、栈、队列、树、图等
同样的数据不同的组织方式就是数据结构。比如对老王的姓名、年龄、性别的描述:
列表方式:[老王,18,男]
字典方式:{name:"老王",age:18,sex:"男"}
而列表、字典都可以存储了老王的数据,但按照不同的方式存储在内存中。

算法是为了解决实际问题而设计的,数据结构是算法需要处理问题的载体
分类
1. 线性结构:线性结构中的数据元素之间存在一对一的关系,即每个元素只有一个直接前驱和一个直接后继。常见的线性结构包括数组、链表、栈和队列等。
- 数组(Array):一组具有相同类型的元素按照一定顺序排列,并通过索引访问。
- 链表(Linked List):一组节点按照顺序连接而成的数据结构,每个节点包含数据和指向下一个节点的指针。
- 栈(Stack):一种具有特殊操作限制的线性表,按照“先进后出”的原则进行插入和删除操作。
- 队列(Queue):一种具有特殊操作限制的线性表,“先进先出”的原则进行插入和删除操作。
2. 树形结构:树形结构中的数据元素之间存在一对多的关系,即每个元素有且仅有一个直接前驱,但可以有多个直接后继。常见的树形结构包括二叉树、堆和哈夫曼树等。
- 二叉树(Binary Tree):每个节点最多有两个子节点的树结构。
- 堆(Heap):一种特殊的二叉树,每个节点的值都大于或小于其子节点的值,用于实现优先队列等应用。
- 哈夫曼树(Huffman Tree):通过频率来构建的一种特殊二叉树,常被用于数据压缩。
3. 图形结构:图形结构中的数据元素之间存在多对多的关系,即每个元素可以与其他任意元素有关联。常见的图形结构包括有向图和无向图等。
- 有向图(Directed Graph):图中的边具有方向性。
- 无向图(Undirected Graph):图中的边没有方向性。
4. 散列结构:散列结构利用散列函数将数据元素映射到一个固定位置,常用于实现哈希表等。
以上只是数据结构的一些常见分类,实际上还有很多其他类型的数据结构,如集合、链表、树堆、图等。不同的数据结构适用于不同的场景和问题,选择合适的数据结构可以提高算法效率和程序性能。
1.1 数组
一组连续存储的相同类型元素的集合。连续存储说的是内存空间的使用情况,表示是一块连续内存空间。访问可以根据索引访问
1.2 链表
由节点组成的线性数据结构,每个节点包含数据和指向下一个节点的指针。在内存空间的表现是不连续,通过指针建立前后关系
1.3 堆
在计算机科学中,"堆"(Heap)是一种用于动态内存分配的数据结构。堆用于存储程序运行时分配和释放的数据,例如对象、函数的局部变量等。
它与栈(Stack)不同,栈用于存储函数调用的上下文和局部变量。
堆是一块大的内存区域,它的大小在程序运行时可以动态地增长或缩小,允许程序在需要时动态地分配内存。
在堆中分配的内存块通常由程序员手动分配和释放(java有垃圾回收机制),这需要一些管理工作以避免内存泄漏和悬挂指针等问题。
在堆中,数据存储的方式不是按照线性顺序,而是以一种更为灵活的方式进行组织。
对象和数据结构可以在堆中的不同位置分布,而且它们的大小不需要事先确定。这使得堆成为动态内存分配的理想选择,特别是在需要存储不同大小和不同生命周期的数据时。
值得注意的是,堆不仅仅用于动态内存分配,还用于存储在程序运行期间需要长时间存在的数据,如全局变量和动态分配的对象。
不同的编程语言和操作系统对于堆的管理方式可能会有所不同。
1.4 栈
一种后进先出(LIFO)或者说先进后出的数据结构,只允许在栈顶进行插入和删除操作。
1.5 队列
一种先进先出的数据结构。
队列(Queue)遵循先进先出(First-In-First-Out,FIFO)的原则。在队列中,首先被添加到队列的元素也将首先被移除,类似于排队等候的概念。
队列有两个主要操作:入队(Enqueue)和出队(Dequeue)。入队操作将元素添加到队列的尾部,出队操作将队列的头部元素移除并返回。
队列常常用于模拟排队等待的场景,例如打印任务队列、计算机进程调度等。在编程中,队列的应用非常广泛,它可以帮助我们有效地管理和操作一系列数据。
1.6 树结构
树结构(Tree)是一种的非线性数据结构,它由节点(Node)组成,节点之间通过边(Edge)相连接。
树的第一个节点称为根节点(Root),它没有父节点;其他节点都有一个父节点,可以有零个或多个子节点。
树结构的一个重要特性是它的层次性,节点之间有明确定义的层级关系。
树结构的核心概念:
- 根节点(Root): 树的起始节点,没有父节点。
- 父节点(Parent): 有子节点的节点。
- 子节点(Child): 直接连接到父节点的节点。
- 叶子节点(Leaf): 没有子节点的节点。
- 兄弟节点(Sibling): 具有相同父节点的节点。
- 祖先节点(Ancestor): 某节点的父节点、父节点的父节点等等。
- 后代节点(Descendant): 某节点的子节点、子节点的子节点等等。
树结构的示例(二叉树)
下面是一个简单的二叉树的示例,其中包含了整数值作为节点的数据:
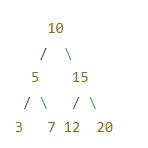
- 根节点是 10。
- 10 的左子节点是 5,右子节点是 15。
- 5 的左子节点是 3,右子节点是 7。
- 15 的左子节点是 12,右子节点是 20。
分类
树结构(Tree)在计算机科学中具有多种不同的分类,它们适用于不同的应用和问题。以下是一些常见的树结构分类和详细解释:
-
二叉树(Binary Tree):
- 二叉树是一种树结构,每个节点最多有两个子节点,分别称为左子节点和右子节点。左子节点通常存储比父节点小的值,右子节点存储比父节点大的值。
- 特殊的二叉树包括满二叉树(每个节点要么没有子节点,要么恰好有两个子节点,满二叉树的节点数量可以用公式计算:N = 2^H - 1,其中 N 表示节点数量,H 表示树的高度。满二叉树的高度是固定的,取决于节点数量)和完全二叉树(除了最后一层,其他层都是满的,而且最后一层的节点都尽量靠左排列。高度可以根据节点数量进行计算,通常为 log2(N)(向上取整),N是节点数。不要求每个节点都有两个子节点,但是如果某个节点有子节点,它的子节点一定是从左到右依次添加的,不会有空缺的位置。)。
-
二叉搜索树(Binary Search Tree,BST):
- 二叉搜索树是一种二叉树,它具有以下性质:
- 左子树中的所有节点的值都小于根节点的值。
- 右子树中的所有节点的值都大于根节点的值。
- 左右子树都是二叉搜索树。
- BST 可以用于高效的查找、插入和删除操作。
- 二叉搜索树是一种二叉树,它具有以下性质:
-
平衡二叉树(Balanced Binary Tree):
- 平衡二叉树是一种特殊的二叉搜索树,它确保树的高度平衡,避免出现极端不平衡的情况。平衡树的操作效率更稳定。
-
红黑树(Red-Black Tree):
- 红黑树是一种自平衡二叉搜索树,它通过规定节点的颜色和旋转操作来保持平衡。红黑树的高度永远不会超过 2 倍的最短路径。
-
B树(B-Tree):
- B树是一种多叉树(每个节点可以有多个子节点),通常用于数据库和文件系统中。它具有平衡性和高度可调性,能够存储大量数据。
-
堆(Heap):
- 堆是一种特殊的树结构,通常是一个完全二叉树。堆分为最小堆和最大堆两种类型,用于高效地查找最小值或最大值。
-
Trie(前缀树):
- Trie 是一种树结构,用于高效存储和检索字符串集合。它的每个节点代表一个字符,从根节点到叶子节点的路径构成一个字符串。
-
AVL树:
- AVL树是一种自平衡二叉搜索树,确保树的高度平衡。它在插入和删除操作时会自动执行旋转操作以维持平衡。
-
伸展树(Splay Tree):
- 伸展树是一种自适应树结构,它通过伸展操作将最近访问的节点移到根节点位置,以提高最近访问节点的访问效率。
这些是一些常见的树结构分类,每种树结构都有自己的特点和适用场景。根据具体的问题和需求,选择合适的树结构可以提高算法和数据结构的效率。
满二叉树和完美二叉树区别:
- 满二叉树的每个节点要么没有子节点,有子节点必须有两个子节点,高度是固定的。
- 完全二叉树的高度可以根据节点数量计算,最后一层节点从左到右排列,不会有空缺。
满二叉树:
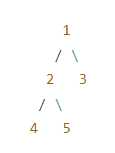
完美二叉树:
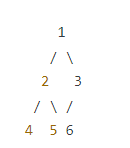
树结构的应用:
-
二叉树(Binary Tree): 每个节点最多有两个子节点,左子节点和右子节点。常用于搜索、排序和表示层次关系等任务。
-
二叉搜索树(Binary Search Tree,BST): 一种特殊的二叉树,左子树中的节点值小于根节点,右子树中的节点值大于根节点。用于高效的查找、插入和删除操作。
-
平衡二叉树(Balanced Binary Tree): 一种特殊的二叉搜索树,确保树的高度平衡,以提高性能。
-
堆(Heap): 用于高效地找到最大或最小元素,常用于优先队列、堆排序等。
-
树表达式(Expression Tree): 用于表示数学表达式,如算术表达式或布尔表达式,方便求值。
-
文件系统(File System): 文件和目录可以表示为树结构,其中根目录是根节点,子目录是父目录的子节点。
-
HTML DOM(Document Object Model): 用于表示网页文档的树结构,方便操作和修改网页内容。
树结构的深度
树结构的深度(Depth)是指树中从根节点到某个节点的最长路径的长度。深度也可以表示树的层数,即树中最深的节点所在的层级。
下面来详细解释树结构的深度:
-
树的根节点深度为 0: 根节点是树的起始点,因此它的深度为 0。
-
子节点的深度是父节点深度加 1: 在一棵树中,每个子节点的深度都是其父节点深度加 1。
-
树的深度是最深节点的深度: 一棵树的深度等于其中最深的节点的深度。
-
深度与层级: 深度也可以表示为树的层数。根节点所在的层级是第 0 层,树的深度等于最底层叶子节点所在的层级。
深度的概念在树的操作和遍历中非常重要,因为它决定了你可以在树中搜索的范围。在深度优先搜索(Depth-First Search,DFS)和广度优先搜索(Breadth-First Search,BFS)等算法中,深度是一个关键参数。
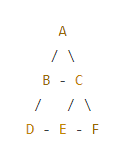
下面是一个示例树结构,让我们计算树中各个节点的深度:
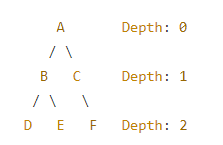
- 节点 A 的深度为 0。
- 节点 B 和节点 C 的深度为 1。
- 节点 D、节点 E 和节点 F 的深度为 2。
在这个示例中,树的深度是 2,因为最深的节点(D、E、F)位于第 2 层。了解树的深度可以帮助你确定树的结构,以及如何在树中进行搜索和操作。
1.7 图结构
图结构(Graph)用于表示对象之间的关系。
图由节点(Node)和边(Edge)组成,节点表示对象,边表示对象之间的关系。
图可以用于解决各种实际问题,如社交网络分析、路由算法、关系数据库等。
基本概念:
-
节点(Node):
- 节点也称为顶点(Vertex),表示图中的对象或实体。节点可以存储任何类型的数据。
- 节点之间可以有连接,也可以没有。
-
边(Edge):
- 边表示节点之间的关系,它可以是有向的或无向的。
- 有向边从一个节点指向另一个节点,具有方向性。
- 无向边没有方向,表示节点之间的双向关系。
-
路径(Path):
- 路径是节点和边的序列,连接图中的节点。路径可以为空(长度为 0),或者包含一个或多个节点和边。
-
有向图和无向图:
- 有向图(Directed Graph)包含有向边,其中边从一个节点指向另一个节点。
- 无向图(Undirected Graph)包含无向边,边没有方向,表示节点之间的对等关系。
-
权重(Weight):
- 对于加权图(Weighted Graph),每条边都关联一个权重或成本,用于表示边的属性或距离。
-
无向图(Undirected Graph):
- 无向图中的边没有方向,节点之间的关系是对等的。
-
有向图(Directed Graph,Digraph):
- 有向图中的边具有方向,表示节点之间的单向关系。
-
加权图(Weighted Graph):
- 加权图中的边具有权重,通常用于表示距离、成本等。
-
稀疏图和稠密图:
- 稀疏图具有较少的边,节点之间的连接相对较少。
- 稠密图具有大量的边,节点之间的连接相对较多。
图的应用:
图结构在许多领域中都有广泛的应用,包括但不限于:
- 社交网络分析:用于表示社交网络中的用户和关系。
- 路由算法:用于网络路由和路径规划。
- 数据库:用于关系数据库中的表与表之间的关系。
- 编译器设计:用于表示源代码的语法结构。
- 地理信息系统(GIS):用于地图和地理空间数据的表示。
图是一种非常强大的数据结构,可以用于解决各种复杂的问题,但也需要谨慎使用,因为图算法的复杂度通常较高。
示例
考虑一个社交网络中的图结构,其中表示了一些用户之间的关系。
在这个图中,每个节点代表一个用户,边代表用户之间的关系,例如友谊关系。这是一个无向图,因为友谊关系是双向的。
解释:
-
节点(Vertices):
- A、B、C、D、E、F 分别代表六个用户。
-
边(Edges):
- 边表示用户之间的友谊关系。
- 例如,A 与 B 之间有一条边,表示 A 和 B 是朋友。
- 同样,B 与 C、C 与 E、E 与 D 都有边表示他们之间是朋友关系。
-
无向图(Undirected Graph):
- 这是一个无向图,因为边没有方向。如果 A 与 B 是朋友,那么 B 与 A 也是朋友。
-
路径(Paths):
- 路径是从一个节点到另一个节点经过的边的序列。例如,从 A 到 D 可以通过节点 B 和节点 E 获得路径:A -> B -> E -> D。
-
连通性(Connectivity):
- 图中的节点和边形成一个连通组件,也就是说,从任何一个节点出发,都可以到达图中的其他节点。
- 例如,在这个图中,每个节点都与其他节点相连通。
这个图示例展示了一个简单的社交网络,其中用户之间的友谊关系表示为图的边。
图结构可以用于模拟和分析各种复杂的关系网络,包括社交网络、网络路由、组织结构等。图的节点和边的组织方式可以根据具体的应用和问题而变化。
1.8 哈希表
哈希表(Hash Table),也称为散列表,是一种常用的数据结构,用于高效地存储和检索数据。
哈希表基于哈希函数将数据存储在数组中,并通过哈希函数将键映射到数组的特定位置,从而实现快速的数据访问。
以下是哈希表的详细解释以及一个示例:
基本概念:
-
哈希函数(Hash Function):
- 哈希函数是一个算法,它接受输入(例如键)并将其转换为固定大小的哈希值(散列码)。
- 好的哈希函数应该具有以下特性:
- 一致性:对于相同的输入,始终生成相同的哈希值。
- 均匀性:尽量避免哈希冲突,即不同的输入应该映射到不同的哈希值。
- 快速计算:哈希函数应该快速计算哈希值。
-
哈希表数组(Hash Table Array):
- 哈希表通常是一个包含固定数量桶或槽的数组,每个桶用于存储数据。
- 哈希函数将键映射到数组的特定索引位置。
-
哈希冲突(Hash Collision):
- 当两个不同的键被哈希函数映射到相同的索引位置时,发生哈希冲突。
- 解决哈希冲突的方法包括链地址法和开放地址法等。
哈希表的示例:
考虑一个简单的哈希表示例,用于存储学生的成绩信息。每个学生有一个唯一的学号作为键,对应的成绩作为值。
1 # 创建一个哈希表 2 hash_table = [None] * 10 # 使用长度为 10 的数组作为哈希表 3 4 # 哈希函数示例:将学号取模来计算索引位置 5 def hash_function(student_id): 6 return student_id % len(hash_table) 7 8 # 插入数据 9 def insert_score(student_id, score): 10 index = hash_function(student_id) 11 if hash_table[index] is None: 12 hash_table[index] = [] 13 hash_table[index].append((student_id, score)) 14 15 # 查找数据 16 def lookup_score(student_id): 17 index = hash_function(student_id) 18 if hash_table[index] is not None: 19 for item in hash_table[index]: 20 if item[0] == student_id: 21 return item[1] 22 return None 23 24 # 插入学生成绩 25 insert_score(101, 95) 26 insert_score(102, 88) 27 insert_score(103, 78) 28 29 # 查找学生成绩 30 print("Student 101's score:", lookup_score(101)) # 输出:Student 101's score: 95 31 print("Student 102's score:", lookup_score(102)) # 输出:Student 102's score: 88 32 print("Student 104's score:", lookup_score(104)) # 输出:Student 104's score: None
在这个示例中,我们使用一个长度为 10 的数组作为哈希表。
我们定义了一个哈希函数来计算学生的学号对应的索引位置。
然后,我们可以插入学生成绩和查找学生成绩,通过哈希函数将学号映射到数组中的索引位置,实现了高效的数据存储和检索。
哈希表是一种非常强大且高效的数据结构,常用于解决数据存储和查找的问题。但需要注意的是,良好的哈希函数设计对于减少哈希冲突非常重要。
2. 数据类型
JAVA
Java常见的数据类型
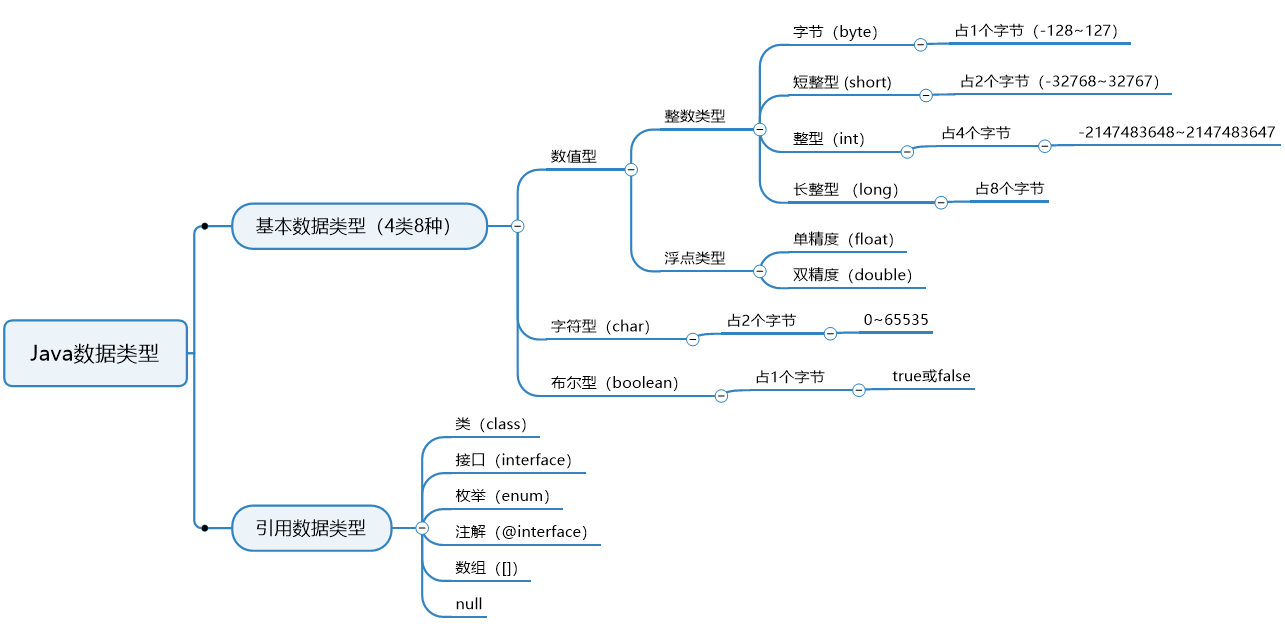
- 列表、集合、字典/map都是以类存在的
- Java是编译解释语言,也是强类型语言、静态类型语言
- 对于数据结构来说这些数据都可以存储。有1点特别注意:数组结构也可以存储数组这种数据(就是绕了点,说白了就是数组中的元素是数组)
import java.util.Arrays; public class Test { public static void main(String[] args) { Object [] array = new Object[2]; array[0]=new int[]{1,2,3}; array[1]=new int[]{3,4,5}; System.out.println(Arrays.toString((int[]) array[0])); System.out.println(Arrays.toString((int[]) array[1])); } }
输出:
[1, 2, 3] [3, 4, 5]
Python
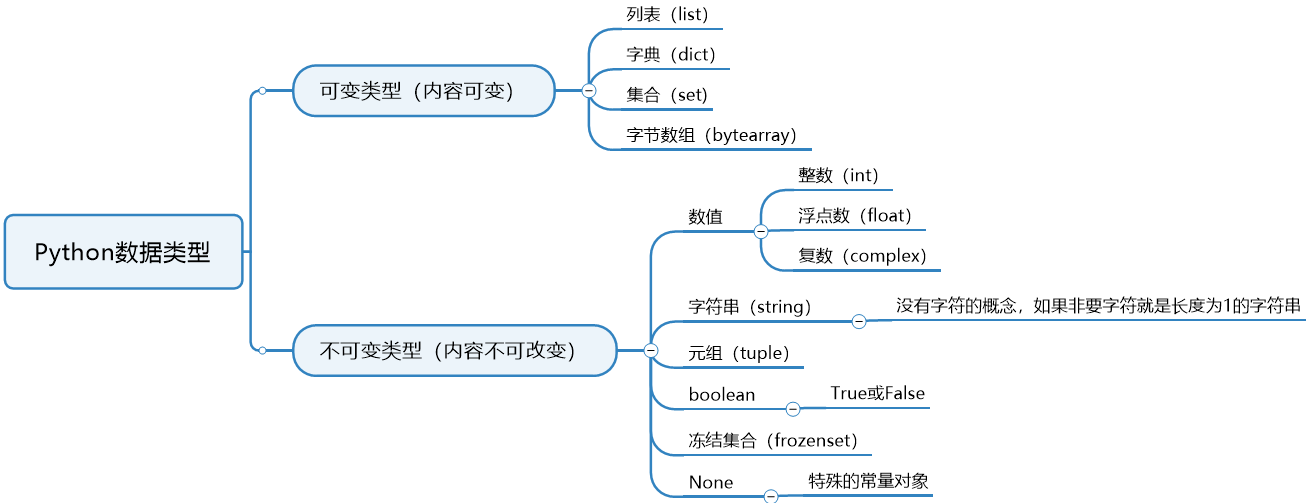
1. 因为Python一切皆对象,只能按可变、不可变来区分。
2. Python 中的一切都被视为对象。这是 Python 的一项基本设计原则,被称为 "一切皆对象"("everything is an object")原则。
3. 在 Python 中,不仅是变量、数据类型和函数,连数字、字符串、类、模块等各种概念都被视为对象。
4. 这种对象的概念意味着每个对象都有一些数据(称为属性)和可以在对象上执行的操作(称为方法)。
5. 这也意味着你可以在 Python 中将对象作为参数传递、将它们分配给变量,并且在运行时操作它们的属性和方法。
6. 类、函数、模块也可视为不可变类型
https://www.cnblogs.com/allenxx/p/17515439.html
https://aistudio.baidu.com/projectdetail/5408513
JavaScript
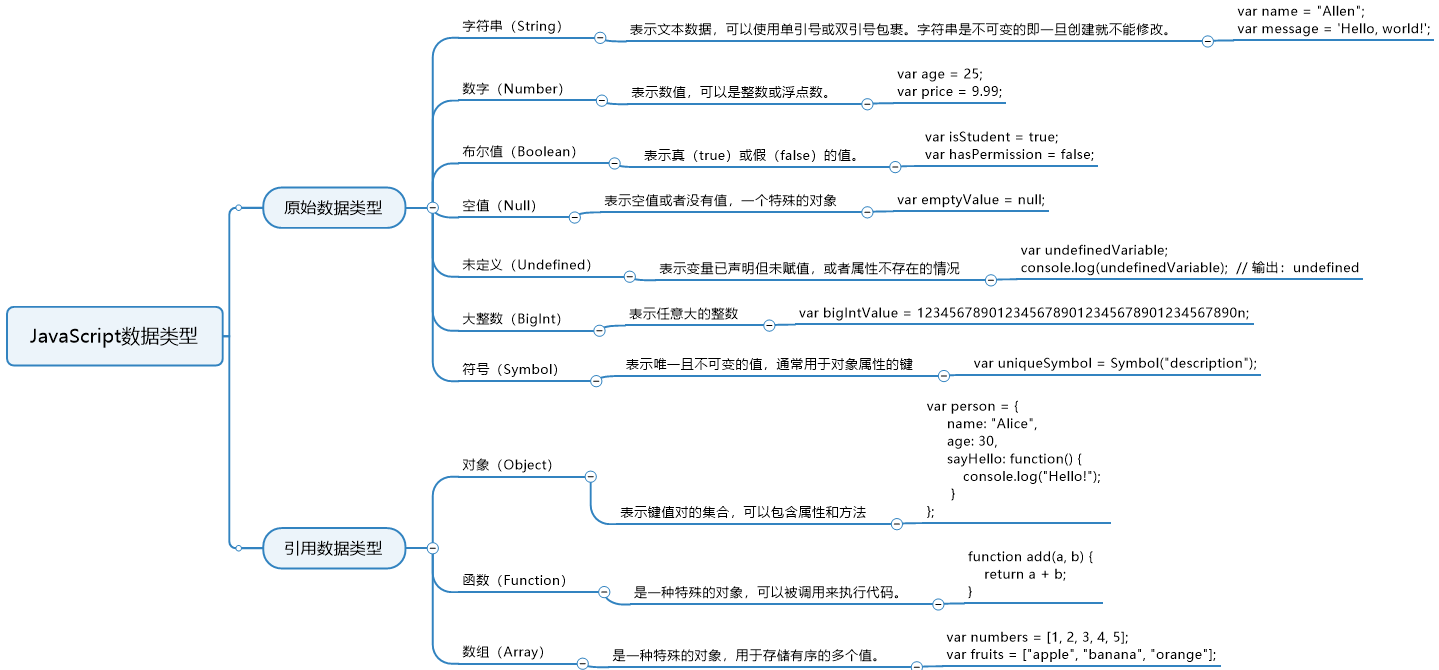
js与Python一样是动态语言即变量的类型可以在运行时根据值的类型自动更改(弱语言)。
变量的类型可以在运行时自动推断或改变
算法
解决问题的具体步骤或计算过程。 包括排序算法(如冒泡排序、插入排序、选择排序、快速排序、归并排序)、搜索算法(如线性搜索、二分搜索、广度优先搜索、深度优先搜索)等。
同样的数据,同样的目的, 不同的算法,不同的方法和思路,效率就会不同

算法是一种独立的存在 , 它并不依附于代码 , 代码只是实现算法思想的方式而已。比如穷举法 按照穷举法的思想 , 我们既可以使用java语言解决问题也可以使用Python语言解决问题
算法的5大特性
①输入: 算法具有0个或多个输入
②输出: 算法至少有1个或多个输出
③有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
④确定性:算法中的每一步都有确定的含义,不会出现二义性
⑤可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
分治法
它将一个大问题分解成若干个相似的小问题,然后将这些小问题的解合并成原问题的解。
分治法通常包括三个步骤:分、治、合。
分治法的基本步骤:
-
分(Divide): 将原问题分解成若干个相似的子问题。这通常通过递归地将问题划分为更小的部分来完成。
-
治(Conquer): 递归地解决子问题。通常,如果子问题足够小,可以直接求解。否则,继续分解子问题,直到达到基本情况。
-
合(Combine): 将子问题的解合并成原问题的解。这个步骤通常是通过合并子问题的解来完成的。
分治法的示例 - 归并排序:用于对一个数组进行排序。
1 # 归并排序函数 2 def merge_sort(arr): 3 if len(arr) <= 1: 4 return arr 5 6 # 分 7 mid = len(arr) // 2 8 left = arr[:mid] 9 right = arr[mid:] 10 11 # 递归地解决子问题 12 left = merge_sort(left) 13 right = merge_sort(right) 14 15 # 合并子问题的解 16 return merge(left, right) 17 18 # 合并函数 19 def merge(left, right): 20 result = [] 21 i = j = 0 22 23 while i < len(left) and j < len(right): 24 if left[i] < right[j]: 25 result.append(left[i]) 26 i += 1 27 else: 28 result.append(right[j]) 29 j += 1 30 31 result.extend(left[i:]) 32 result.extend(right[j:]) 33 return result 34 35 # 示例用法 36 arr = [38, 27, 43, 3, 9, 82, 10] 37 sorted_arr = merge_sort(arr) 38 print(sorted_arr) # 输出:[3, 9, 10, 27, 38, 43, 82]
在归并排序中,我们首先将数组分成两半,然后递归地对每一半进行排序,最后将排序好的两个子数组合并成一个有序数组。
分治法的最佳实践:
-
选择合适的问题: 分治法通常用于可以划分成若干个子问题且子问题与原问题相似的情况。适合用分治法解决的问题通常具有以下性质:子问题是相互独立的,子问题的解可以合并成原问题的解。
-
递归停止条件: 确保递归的子问题足够小,可以直接求解,从而避免无限递归。(不要超时递归深度)
-
合并子问题的解: 子问题的解需要能够合并成原问题的解。这通常需要一些合并操作,如归并排序中的合并步骤。
-
性能考虑: 分治法可能导致问题的重复计算,因此可以考虑使用记忆化技术或动态规划来优化性能。
-
处理边界情况: 确保考虑到边界情况,例如空数组或单个元素数组,以避免错误。
分治法是解决许多复杂问题的有效方法,如排序、查找、优化问题等。了解如何将问题分解成子问题,递归地求解子问题,然后合并解是掌握分治法的关键。
递归法
递归法(Recursion)是一种解决问题的方法,其中函数自身调用以解决问题的子问题。递归通常用于解决可以分解成相似子问题的问题,例如数学中的阶乘、斐波那契数列,以及树和图的遍历等。以下是递归法的详细解释、示例和最佳实践。
递归法的基本原理:(1.函数里面调自己,2. 建立相邻次调用的关系,3. 函数里有终止条件。)
递归法是一种自相似性的解决问题的方法,它包括以下关键步骤:
-
基本情况(Base Case): 定义一个或多个基本情况,这些情况下递归将停止。基本情况通常是问题可以直接求解的情况。
-
递归调用: 在问题的递归情况下,函数调用自身,并将问题分解为一个或多个更小的子问题。
-
合并子问题的解: 在递归调用返回之后,将子问题的解合并为原问题的解。
递归法的示例 - 阶乘计算:
阶乘(Factorial)是一个经典的递归问题,可以用递归法来解决。
1 # 阶乘计算的递归函数 2 def factorial(n): 3 # 基本情况 4 if n == 0: # 3:函数递归调用终止 5 return 1 6 # 递归调用 7 else: 8 return n * factorial(n - 1) # 1&2: 函数里调用自己并建立此次调用与下次调用关系 9 10 # 示例用法 11 result = factorial(5) 12 print(result) # 输出:120
在这个示例中,factorial 函数通过递归计算了阶乘。基本情况是 n 等于 0 时,阶乘为 1。在递归情况下,函数调用自身,并将问题分解为一个较小的子问题(n - 1 的阶乘),然后将子问题的解与 n 相乘以获得原问题的解。
递归法的最佳实践:
-
定义清晰的基本情况: 确保基本情况是清晰且能够停止递归的条件。
-
确保问题规模减小: 在递归调用中,问题的规模应该比原问题小,否则可能会导致无限递归。
-
处理递归调用的返回值: 确保正确处理递归调用的返回值,以合并子问题的解。
-
注意性能和堆栈溢出: 递归可能导致堆栈溢出,因此在处理大规模问题时,要考虑性能问题。有些递归问题可以通过迭代方法或尾递归优化来避免堆栈溢出。
-
避免重复计算: 一些递归问题会重复计算相同的子问题。可以考虑使用记忆化(Memoization)来缓存子问题的解,提高性能。
-
适用场景: 递归通常用于树结构、图遍历、分治法等问题,但不是所有问题都适合递归解决。
递归法是一种强大的问题解决方法,但需要小心处理递归调用的细节,以避免陷入无限递归或性能问题。在选择使用递归时,考虑问题的自相似性和结构,以确定递归法是否适用。
贪心法
贪心算法(Greedy Algorithm)用于解决优化问题。
贪心算法每次选择当前最优的解决方案,希望最终获得全局最优解。
虽然贪心算法在某些情况下能够得到最优解,但并不保证在所有问题上都能够取得最优结果。
贪心算法的基本思想:
贪心算法的核心思想是每次都选择局部最优解,希望通过这种方式最终达到全局最优解。贪心算法通常包括以下步骤:
-
建立数学模型: 首先,将问题抽象成一个数学模型,明确问题的目标和约束条件。
-
确定局部最优解策略: 确定一种策略,每次都选择当前局部最优的解决方案,这是贪心算法的核心。
-
检查是否满足约束条件: 确认选择的解决方案是否满足问题的约束条件,如果不满足,则需要调整选择。
-
迭代直到达到全局最优: 重复步骤 2 和 3,直到满足问题的
贪心算法的示例 - 找零钱问题(经典的机试题):
考虑一个找零钱的问题,假设有以下面额的硬币:1元、5元、10元、25元,以及一个顾客需要找零 n 元的需求。我们的目标是找零的硬币数量尽可能少。
1 ''' 2 考虑一个找零钱的问题,假设有以下面额的硬币:1元、5元、10元、25元,以及一个顾客需要找零 n 元的需求。我们的目标是找零的硬币数量尽可能少。 3 ''' 4 5 6 def greedy_coin_change(n, coins): 7 coins.sort(reverse=True) # 将硬币按面额降序排序 8 change = [] # 存储找零的硬币列表 9 10 for i in range(0, len(coins), 1): # range(start, stop, step),实践到stop-1 11 coin = coins[i] 12 print(coin) 13 while n >= coin: # 每次都贪心,就想要大面额的硬币 14 n -= coin 15 change.append(coin) 16 17 if n == 0: 18 return change 19 else: 20 return "无法找零" 21 22 23 def greedy_coin_change2(n, coins): 24 coins.sort(reverse=True) # 将硬币按面额降序排序 25 change = [] # 存储找零的硬币列表 26 27 for coin in coins: # python、javascript for-each是按照列表的顺序顺序遍历的,但java不是,java是随机的 28 while n >= coin: 29 n -= coin 30 change.append(coin) 31 32 if n == 0: 33 return change 34 else: 35 return "无法找零" 36 37 38 # 示例用法 39 n = 49 40 coins = [1, 5, 10, 25] 41 change = greedy_coin_change(n, coins) 42 print(change) # 输出:[25, 10, 10, 1, 1, 1, 1]
在这个示例中,首先将硬币按面额降序排序,然后从最大面额的硬币开始,尽可能多地选择大面额的硬币,直到找零金额 n 为 0。
这个算法的核心是每次都选择当前面额的硬币,因为它是局部最优解,希望通过这种方式找到最少的硬币数量。
贪心算法的最佳实践:
-
问题适用性: 贪心算法适用于一类特定的优化问题,通常需要证明问题具有贪心选择性质,即每次选择局部最优解可以导致全局最优解。
-
无法保证最优性(每次是最优,但最终不一定最优): 贪心算法通常无法保证获得全局最优解,因此需要谨慎选择算法,特别是在问题具有多个解或约束复杂的情况下。
-
排序和选择策略: 对于贪心算法,通常需要对数据进行排序,以便每次选择最优的局部解决方案。选择策略应该符合问题的性质。
-
验证解的正确性: 在使用贪心算法时,必须验证所选择的解是否满足问题的所有约束条件。
-
备选算法: 在贪心算法无法获得最优解时,可以考虑其他优化算法,如动态规划等。
贪心算法是一种强大的工具,用于解决一些特定类型的问题。理解问题的性质以及选择合适的贪心策略是成功使用贪心算法的关键。
动态规划法
动态规划(Dynamic Programming,简称DP)是一种常用于解决具有最优子结构(Optimal Substructure)和重叠子问题性质(Overlapping Subproblems)的问题的算法设计技巧。
DP通常用于解决优化问题,其中目标是找到最佳解决方案,例如最短路径、最大价值等。
动态规划的基本思想:
动态规划的核心思想是将一个复杂问题分解成多个子问题,并将子问题的解存储起来以避免重复计算。DP通常包括以下步骤:
-
定义状态: 确定问题的状态,通常用一个或多个变量表示状态。这些状态可以描述问题的子问题或问题的不同阶段。
-
状态转移方程: 定义状态之间的转移关系。通常,状态转移方程描述了如何根据已知状态计算下一个状态。
-
初始化: 初始化问题的初始状态,通常是问题中的边界情况或基本情况。
-
递推计算: 使用状态转移方程从初始状态递推计算到问题的目标状态。
-
返回结果: 根据已计算的状态,返回问题的最终结果。
动态规划的示例 - 斐波那契数列:
斐波那契数列是一个常见的动态规划示例,它定义如下:
F(0) = 0 F(1) = 1 F(n) = F(n-1) + F(n-2) (对于 n > 1)
使用动态规划可以计算斐波那契数列的任意项:
def fibonacci(n): if n <= 1: return n # 1. 初始化状态 dp = [0] * (n + 1) # [0, 0, 0, 0, 0, 0, 0] dp[1] = 1 # 2. 递推计算 for i in range(2, n + 1): dp[i] = dp[i - 1] + dp[i - 2] # 3. 返回结果 return dp[n] # 示例用法 result = fibonacci(6) print(result) # 输出:8
说明:
1. 解决F(0)=0,F(1)=1的问题,从而确保函数的基本情况正确。
def fibonacci(n):
if n <= 1:
return n
2. 初始化状态
# 1. 初始化状态
dp = [0] * (n + 1) #[0, 0, 0, 0, 0, 0, 0],创建了一个长度为n+1的列表dp,用于存储计算过程中的状态
dp[1] = 1 # 完成初始化状态,对应F(1)结果是1
这是动态规划的第一步,即初始化状态。
创建了一个长度为n+1的列表dp,用于存储计算过程中的状态。
由于斐波那契数列的第一个数是0,第二个数是1,所以我们在dp[1]处赋值为1,以满足初始状态。
F(n)的值就对应dp(n),dp列表的长度是n+1的元素,是包含了F(0)的情况
3. 递推计算
# 2. 递推计算
for i in range(2, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
这是动态规划的核心部分,即递推计算。我们使用一个循环从第3个数开始,一直计算到第n个数。
状态转移方程 dp[i] = dp[i - 1] + dp[i - 2] 表示第i个数等于前两个数之和,这是斐波那契数列的定义。
这个循环将填充dp 列表,计算并存储了斐波那契数列的所有中间项。
4. 把最终结果返回
# 返回结果
return dp[n]
返回dp[n],即斐波那契数列的第n项作为结果。
态规划的思想是将问题分解为子问题,然后通过填充状态数组 dp 来避免重复计算子问题,从而高效地计算斐波那契数列的值。这是动态规划的一个经典示例。
动态规划:用问题分解为子问题,并存储、映射关系。上例子的就是使用列表dp存储每个子问题(F(n-1)、F(n-2)、……F(1)、F(0)),通过列表索引与子问题建立映射关系。避免了重复计算。
迭代法
迭代法(Iteration)通过重复执行一组操作来逐步逼近问题的解决方案。迭代法通常用于循环和逐步逼近的问题,如数值计算、搜索、优化等。
迭代法的基本思想:
迭代法的核心思想是通过多次重复执行一组操作,逐步逼近问题的解决方案。迭代法通常包括以下步骤:
-
初始状态: 确定问题的初始状态或初始值。
-
迭代操作: 定义一个迭代操作或算法,该操作将当前状态转换为下一个状态。
-
终止条件: 确定终止条件,即什么时候停止迭代。通常,终止条件与问题的解或精度有关。
-
迭代过程: 重复执行迭代操作,直到满足终止条件。
-
返回结果: 返回最终的解决方案或结果。
迭代法的示例 - 计算平方根:
让我们以计算一个数的平方根为例来说明迭代法的示例。我们将使用牛顿迭代法来近似计算一个数的平方根。
牛顿迭代法的迭代公式如下:
x_(n+1) = (x_n + num / x_n) / 2
其中,num 是要计算平方根的数,x_n 是第n次迭代的估计值,x_(n+1) 是第n+1次迭代的估计值。我们可以通过重复应用这个迭代公式来逼近平方根的值。
def sqrt_newton(num, tol=1e-6): # 默认值:tol指定精度,1e-6为科学计数法 x = num # 初始估计值 while True: next_x = 0.5 * (x + num / x) # 牛顿迭代公式 if abs(next_x - x) < tol: # 检查终止条件 return next_x x = next_x # 更新估计值 # 示例用法 result = sqrt_newton(9) print(result) # 输出:3.0
在这个示例中,我们使用牛顿迭代法来近似计算数字9的平方根。我们从一个初始估计值开始,然后重复应用迭代公式,直到满足终止条件(估计值变化小于 tol,即精度要求)。最后,我们返回逼近的平方根。
迭代法的最佳实践:
-
选择合适的迭代方法: 根据问题的性质选择合适的迭代方法。不同的问题可能需要不同的迭代策略。
-
初始化: 确保正确初始化迭代的初始状态或值。
-
确定终止条件: 仔细选择终止条件,通常与问题的解或精度要求有关。确保终止条件能够被满足。
-
迭代操作: 定义迭代操作或算法,确保它能够逐步逼近问题的解。
-
考虑性能: 在迭代过程中,要注意性能问题,确保迭代不会无限循环或花费过多时间。
-
备选算法: 在某些情况下,迭代法可能不是最优解决方案,因此要考虑其他算法,如分治法、动态规划等。
迭代法是一种广泛应用于计算和优化领域的强大工具,可以用于解决各种问题。选择正确的迭代策略和合适的参数是成功使用迭代法的关键。
枚举法
枚举法(Enumeration)是一种简单而直接的问题解决方法,它通常涉及遍历所有可能的解决方案以找到问题的解。
枚举法适用于小规模问题或者在解决大规模问题时可以帮助生成问题空间的一部分解的情况。
枚举法的基本思想:
枚举法的核心思想是尝试所有可能的解决方案,以找到问题的解。枚举法通常包括以下步骤:
-
定义问题空间: 确定问题的解可能存在的空间范围,以及解的可能取值。
-
遍历解空间: 使用循环或递归等方法遍历问题的解空间,生成所有可能的解决方案。
-
评估解决方案: 对每个生成的解决方案进行评估,以确定它是否是问题的解。
-
返回结果: 返回
枚举法的示例 - 寻找质数:
我们将使用枚举法来寻找小于或等于给定数的所有质数(素数)。质数是只能被1和自身整除的正整数。
1 def find_primes(n): 2 primes = [] # 存储质数的列表 3 for num in range(2, n + 1): # 遍历2到n之间的数 4 is_prime = True # 假定当前数是质数 5 for i in range(2, int(num ** 0.5) + 1): # 从2到sqrt(num)进行遍历 6 if num % i == 0: # 如果能被整除,不是质数 7 is_prime = False 8 break 9 if is_prime: 10 primes.append(num) 11 return primes 12 13 14 # 示例用法 15 result = find_primes(20) 16 print(result) # 输出:[2, 3, 5, 7, 11, 13, 17, 19]
在这个示例中,我们使用枚举法来寻找小于或等于给定数 n 的所有质数。
我们从2开始,逐个检查每个数是否是质数。如果一个数不能被比它小的整数整除(从2到它的平方根),那么它就是质数。我们将找到的质数存储在 primes 列表中,最后返回这个列表作为结果。
枚举法的最佳实践:
-
定义解空间: 确定问题的解空间,即解可能存在的范围。这有助于确定需要枚举的解的范围。
-
选择合适的遍历方式: 根据问题的性质和解空间的大小,选择适当的遍历方式,如循环或递归。
-
剪枝和优化: 在遍历解空间时,可以使用剪枝技巧来减少不必要的计算。例如,在寻找质数时,可以只检查奇数,因为偶数除了2都不可能是质数。
-
性能考虑: 注意在枚举法中,解空间的大小可能会快速增加,因此需要注意性能问题,以避免不必要的计算。
-
备选算法: 在某些情况下,枚举法可能不是最优解决方案,因此要考虑其他更高效的算法,如贪心算法、动态规划等。
枚举法是一种直观且易于实现的问题解决方法,适用于小规模问题或问题的解空间相对较小的情况。但对于大规模问题,枚举法可能会导致计算复杂度过高,因此需要谨慎使用。
回溯法
回溯法(Backtracking)是一种用于解决组合问题、排列问题、搜索问题等的常用算法。
它的核心思想是尝试所有可能的解决方案,但在发现不可行解之后回溯(即返回之前的状态),继续尝试其他解决方案,直到找到可行解或穷尽所有可能性。
回溯法的基本思想:
回溯法的核心思想是在问题的解空间中进行深度优先搜索,逐步构建可能的解决方案,并在发现不可行解时回溯到上一个状态,继续搜索其他可能的解决方案。
回溯法通常包括以下步骤:
-
定义问题空间: 确定问题的解空间,即解可能存在的范围。这有助于定义问题的状态和决策空间。
-
选择决策: 在每一步,选择一个决策来构建解决方案。这通常涉及从可行的选项中选择一个。
-
递归搜索: 递归地构建解决方案,考虑每个决策的影响,并在必要时回溯到上一个状态。
-
终止条件: 确定何时停止搜索。这通常包括找到可行解、穷尽所有可能性或达到某个条件。
-
回溯: 当发现当前解决方案不可行时,回溯到上一个状态,继续搜索其他可能的解决方案。
回溯法的示例 - 八皇后问题:
八皇后问题是一个经典的回溯法示例,目标是在8×8的国际象棋棋盘上放置8个皇后,使得它们互相不攻击(不在同一行、同一列、同一斜线上)。
以下是一个Python示例来解决八皇后问题:
def solve_n_queens(n): # n代表棋盘大小:n * n
def is_safe(board, row, col):
# 检查列上是否有皇后
for i in range(row):
if board[i][col] == 'Q':
return False
# 检查左上对角线是否有皇后
for i, j in zip(range(row, -1, -1), range(col, -1, -1)):
if board[i][j] == 'Q':
return False
# 检查右上对角线是否有皇后
for i, j in zip(range(row, -1, -1), range(col, n)):
if board[i][j] == 'Q':
return False
return True
def backtrack(row):
if row == n: # 如果当前 row 达到了 n,表示已经成功放置了 n 个皇后,将当前棋盘状态添加到 solutions 列表中。
result.append([''.join(row) for row in board])
return
for col in range(n):
if is_safe(board, row, col): # 此题有一点特别注意:那就是肯定能放下8个皇后,具体有哪些方案?需要通过此算法列出
board[row][col] = 'Q'
backtrack(row + 1)
board[row][col] = '.' # 如果此条路不通,把之前设置的Q,都还原为点即回溯到上一个状态。
board = [['.' for _ in range(n)] for _ in range(n)] # 棋盘,初始化棋盘,一个二维数组
result = [] # 存储所有的解决方案
backtrack(0) # 从第1行(列表的索引是0)开始尝试。
return result
# 示例用法
solutions = solve_n_queens(8)
for solution in solutions:
for row in solution:
print(row)
print()
在这个示例中,使用回溯法来解决八皇后问题。我们逐行放置皇后,并使用 is_safe 函数来检查当前位置是否可以放置皇后。如果可以放置皇后,我们将在该位置放置皇后,并继续递归放置下一行的皇后。如果无法放置皇后,我们回溯到上一行,并继续尝试其他可能的位置。
1. 定义一个 solve_n_queens 函数,它接受一个整数 n,代表八皇后问题中的棋盘大小(n x n)。
2. 定义一个is_safe函数,用于检查在给定的棋盘上,在 row 行 col 列放置皇后是否安全。它会检查三个方向是否有其他皇后:竖直方向、左上斜线和右上斜线
3. 定义一个backtrack函数
if row == n:
solutions.append(["".join(row) for row in board])
return
如果当前 row 达到了 n,表示已经成功放置了 n 个皇后,将当前棋盘(board)状态添加到 solutions 列表中。
如果没有达到n,表示还没有成功放置8个皇后,需要继续判断
for col in range(n):
if is_safe(board, row, col):
board[row][col] = 'Q'
backtrack(row + 1)
board[row][col] = '.'
一个可行的示例:
.......Q ...Q.... Q....... ..Q..... .....Q.. .Q...... ......Q. ....Q...
回溯法的最佳实践:
-
定义解空间: 确定问题的解空间,即解决方案可能存在的范围。这有助于确定需要搜索的路径。
-
约束条件: 定义问题的约束条件,用于检查已构建的部分是否满
算法的衡量标准
复杂度分析:用来评估算法执行效率的指标,包括时间复杂度和空间复杂度。
在数据量不断增加的前提下,执行时间、内存占用的变化趋势,来衡量算法优劣。
时间复杂度
表示算法执行时间随输入数据规模增长的变化趋势。
空间复杂度
表示算法所需内存空间随输入数据规模增长的变化趋势。
应用
排序
查找
加解密
计算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号