
想学习下 flink,开始。
需求很简单,使用 flink 统计本地磁盘上一个文件的单词频率,实现方式有二 DataSet 和 DataStream,两种方式统计的结果出乎我这个新手的预料。
操作步骤:
1. 在 CentOS 中部署单节点的 flink,修改 conf/flink-conf.yaml 文件,根据情况修改 rest.port,rest.address,rest.bind-address 的值,执行 start-cluster.sh 脚本启动 flink
2. 在 idea 中开发 flink 任务
1 package com.example; 2 3 import org.apache.flink.api.common.functions.FlatMapFunction; 4 import org.apache.flink.api.java.DataSet; 5 import org.apache.flink.api.java.ExecutionEnvironment; 6 import org.apache.flink.api.java.tuple.Tuple2; 7 import org.apache.flink.streaming.api.datastream.DataStream; 8 import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; 9 import org.apache.flink.util.Collector; 10 import org.slf4j.Logger; 11 import org.slf4j.LoggerFactory; 12 13 public class WordCountExample { 14 15 private static Logger logger = LoggerFactory.getLogger(WordCountExample.class); 16 17 public static void main(String[] args) throws Exception { 18 if (args.length != 1) { 19 System.err.println("Usage: WordCountExample <input type>"); 20 System.exit(-1); 21 } 22 23 String marker = args[0]; 24 if (marker.equals("1")) { 25 dataSet(); 26 } else { 27 dataStream(); 28 } 29 } 30 31 private static void dataSet() throws Exception { 32 // set up the execution environment 33 final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); 34 env.setParallelism(1); 35 36 // 从文件读取数据 37 DataSet<String> text = env.readTextFile("/home/devops/input.txt"); 38 39 // 处理数据流 40 DataSet<Tuple2<String, Integer>> wordCounts = text 41 .flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { 42 @Override 43 public void flatMap(String line, Collector<Tuple2<String, Integer>> out) { 44 String[] words = line.toLowerCase().split("\\W+"); 45 for (String word : words) { 46 if (word.length() > 0) { 47 out.collect(new Tuple2<>(word, 1)); 48 } 49 } 50 } 51 }).groupBy(0) // 根据单词分组 52 .sum(1); // 对每个单词的计数求和 53 54 // 将数据流写入到文件中 55 wordCounts.writeAsText("/home/devops/output.txt", org.apache.flink.core.fs.FileSystem.WriteMode.OVERWRITE); 56 57 // 执行任务 58 env.execute("Word Count Example"); 59 } 60 61 private static void dataStream() throws Exception { 62 // 创建 Flink 流处理执行环境 63 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); 64 65 // 假设我们的数据源是一个文本文件,这里使用读取文件的方式 66 DataStream<String> text = env.readTextFile("/home/devops/input.txt"); 67 68 // 使用 flatMap 函数将每一行文本分割成单词 69 DataStream<Tuple2<String, Integer>> words = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { 70 @Override 71 public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { 72 // 规范化和分割文本行 73 String[] tokens = value.toLowerCase().split("\\W+"); 74 for (String token : tokens) { 75 if (token.trim().length() > 0) { 76 out.collect(new Tuple2<>(token, 1)); 77 } 78 } 79 } 80 }); 81 82 // 按单词分组并计算每个单词的频率 83 DataStream<Tuple2<String, Integer>> wordCounts = 84 words.keyBy(0) 85 .sum(1); 86 87 // 将数据流写入到文件中 88 wordCounts.writeAsText("/home/devops/output.txt", org.apache.flink.core.fs.FileSystem.WriteMode.OVERWRITE); 89 90 // 执行 Flink 程序 91 env.execute("Flink Word Count Example"); 92 } 93 }
3. 在界面中提交任务,并执行
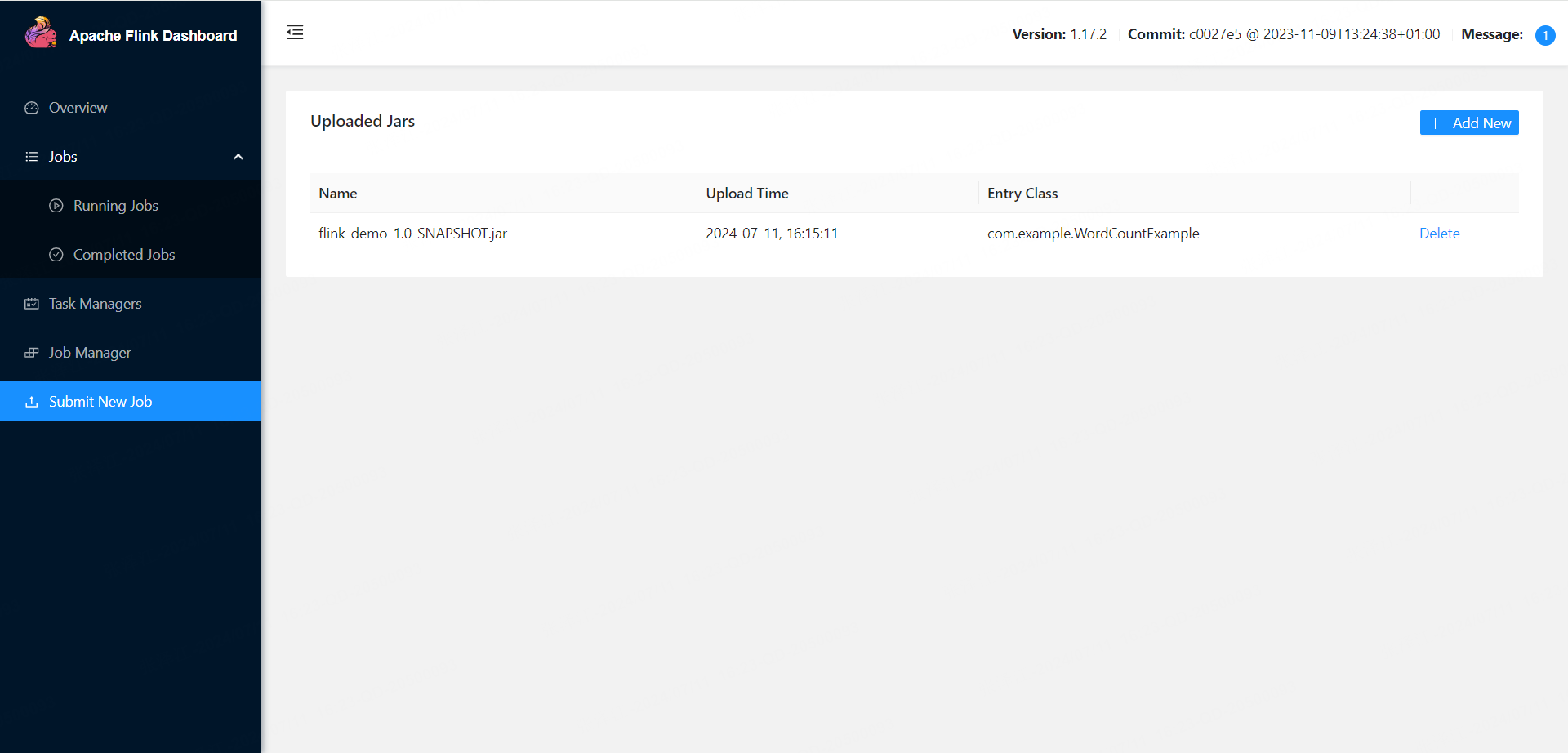
4. 程序参数先输入 1,执行 DataSet,而后输入 2 ,执行 DataStream
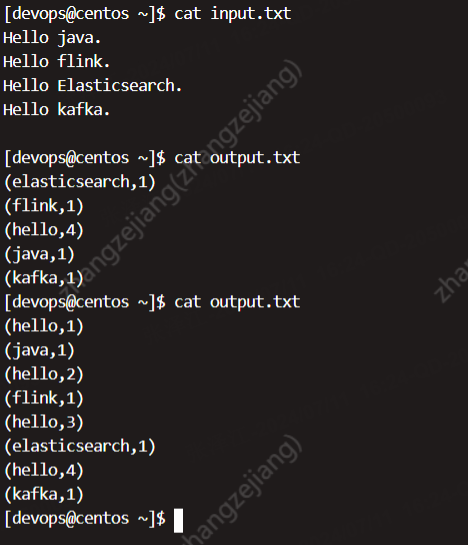
输入文件 input.txt 内容见下图,通过 DataSet 有界数据计算出的词频复合预期,hello 一共出现了 4 次,而通过 DataStream 计算出的词频则让初学者不可思议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号