
通常我们使用 ES, 使用的是 http api,其实 Elasticsearch 是天生的集群架构,ES 进程监听 2 个端口,9200 用于提供 http 访问,9300 用于和集群中的节点进行通信。
在 windows 开发环境下,调试 Elasticsearch 8.4.0-snapshot 源码:.\gradlew.bat run --debug-jvm
另外通过命令行再启动一个 ES 进程,组建一个集群。创建一个索引,设置 1 个分片,1 个副本。如此示例索引有 1 个主分片,1 个副本分片。
我一直有疑问,问题 1:ES 的 getById 向分片发起查询时,会路由到副本分片所在数据节点吗?网上说不会,经过源码调试,发现在 getById 的查询场景下,主分片和副本分片的地位是一样的。
截图为证
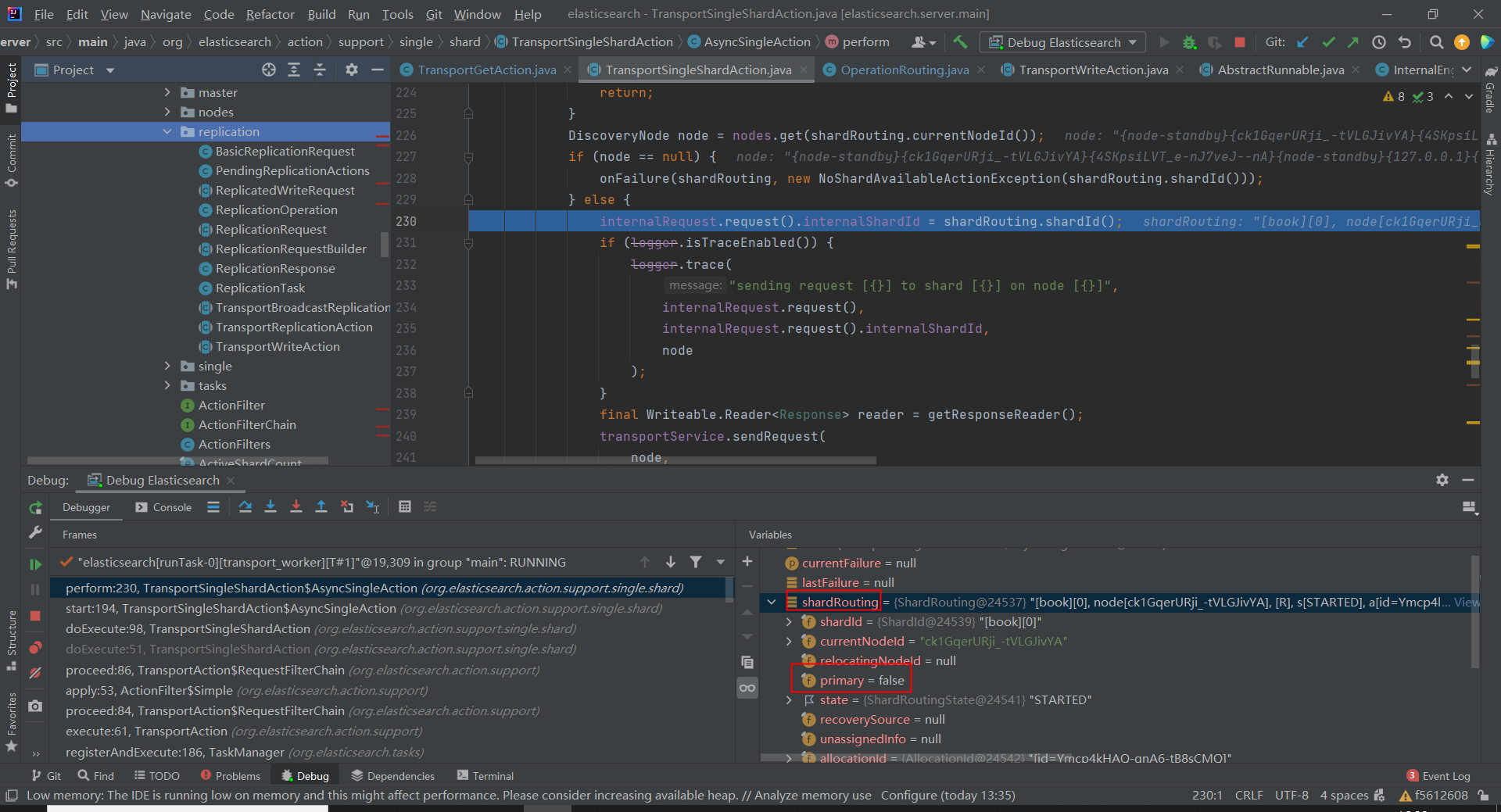
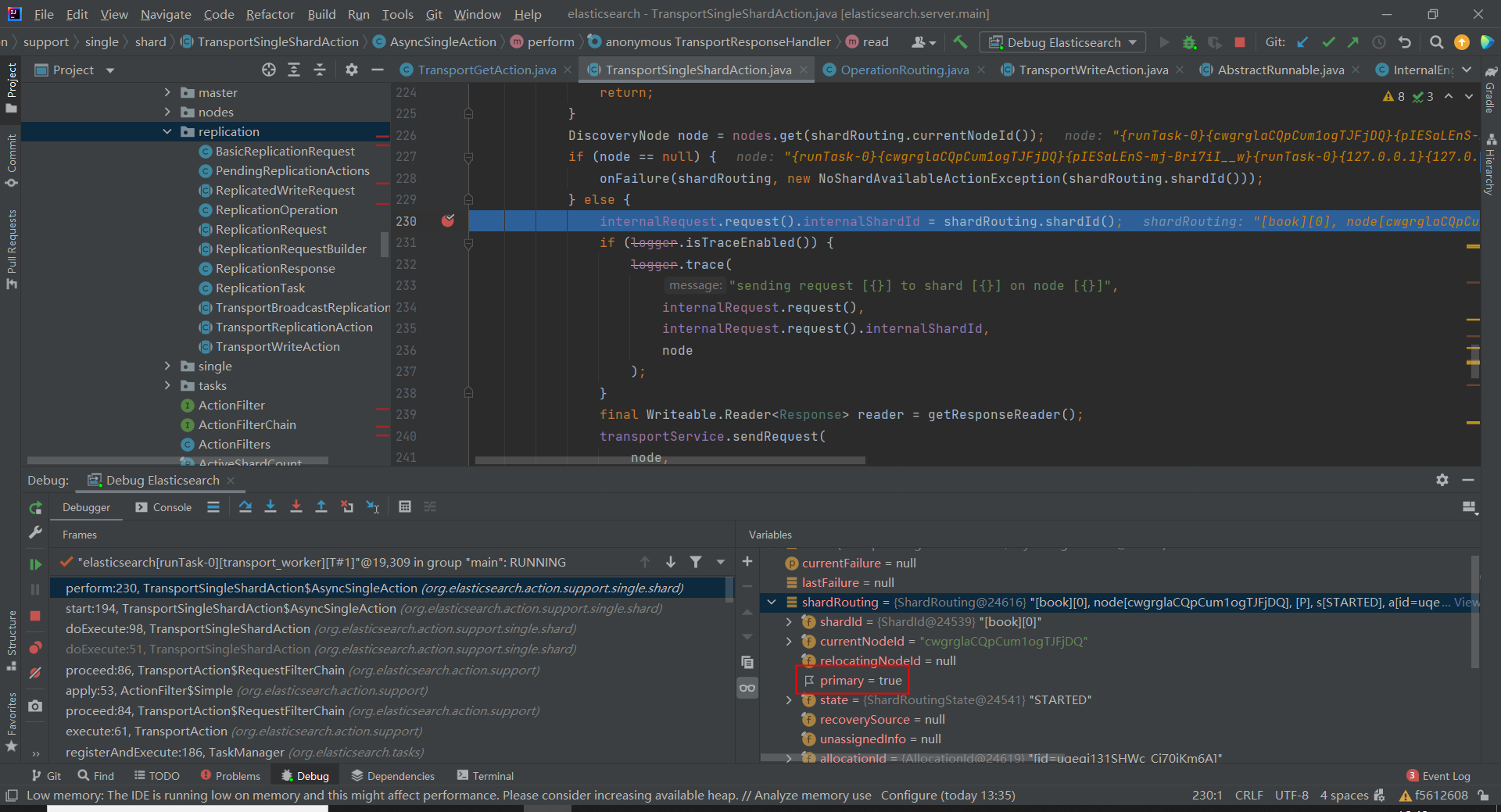
连续发起两次 getById 请求,协调节点一次向副本分片所在数据节点发起查询,第二次协调节点向主分片所在数据节点发起查询。
为什么会这样,和印象中似乎有点反差,仔细一想其实合理,因为文档的写入已经是同步写入到副本了,当写入请求返回时(写入结果正常),即表示文档同时写入到主分片和副本分片,此时从哪个分片查询,结果都是一样的。
问题2:为什么 ES 在 7.0 以后,索引的默认分片是 1 了?同样当我们在网上查询答案时,问到 ES 在 search 时的 queryAndFetch 过程,AI 会告诉我们,协调节点先向数据节点发起 query 请求,拿到文档 id 后,进行汇总和排序,然后向对应的数据节点发起 fetch 请求获取完整的文档。但是,这种说法又错了,或者说错了一半。
截图证明:
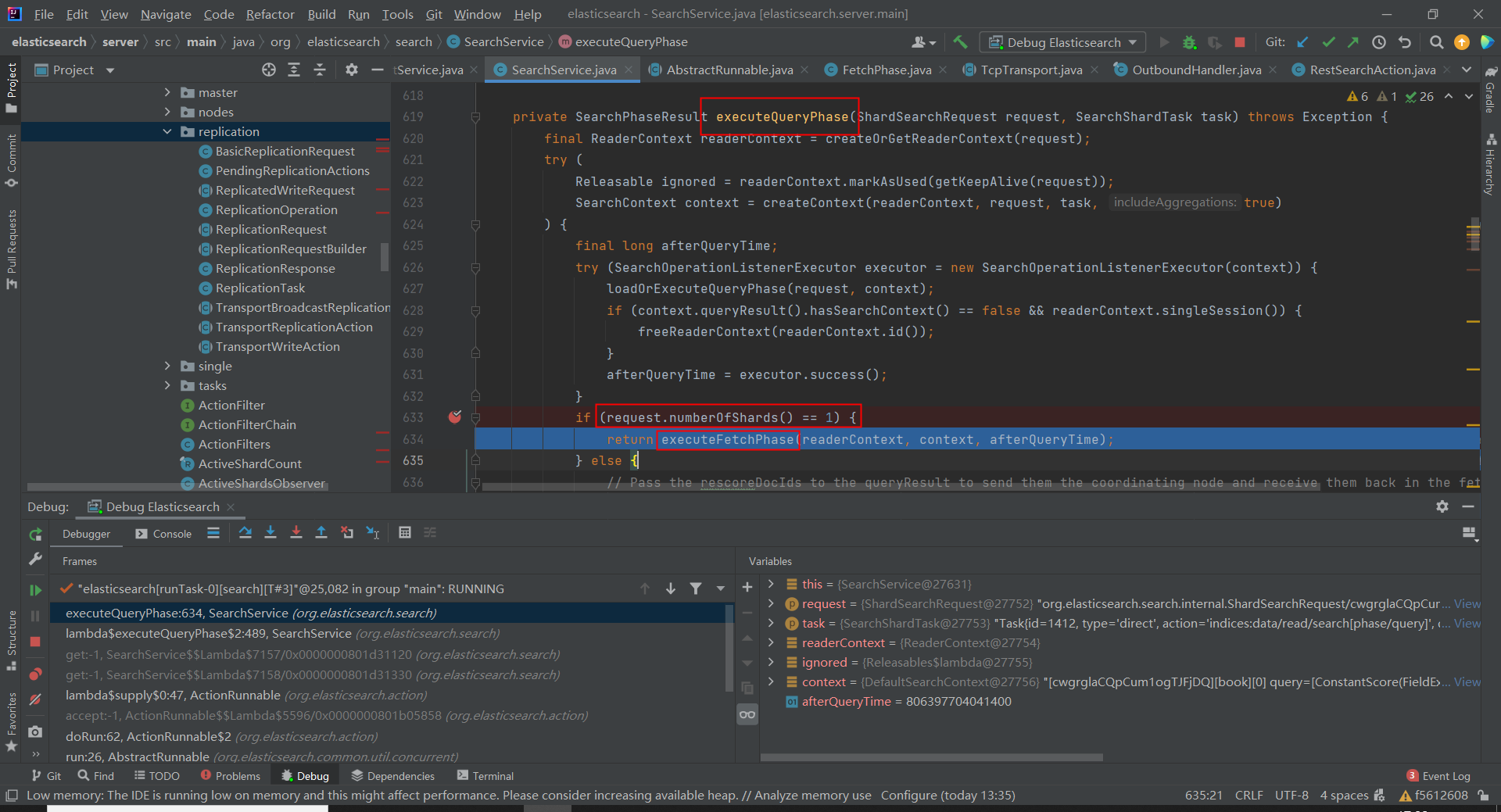
当本次请求对应的分片数为 1 时,数据节点会直接执行 query 和 fetch。
回到标题,由于 ES 是分布式的系统,代码初看起来,整个请求链到处乱跳,其实有套路可循,以搜索为例:
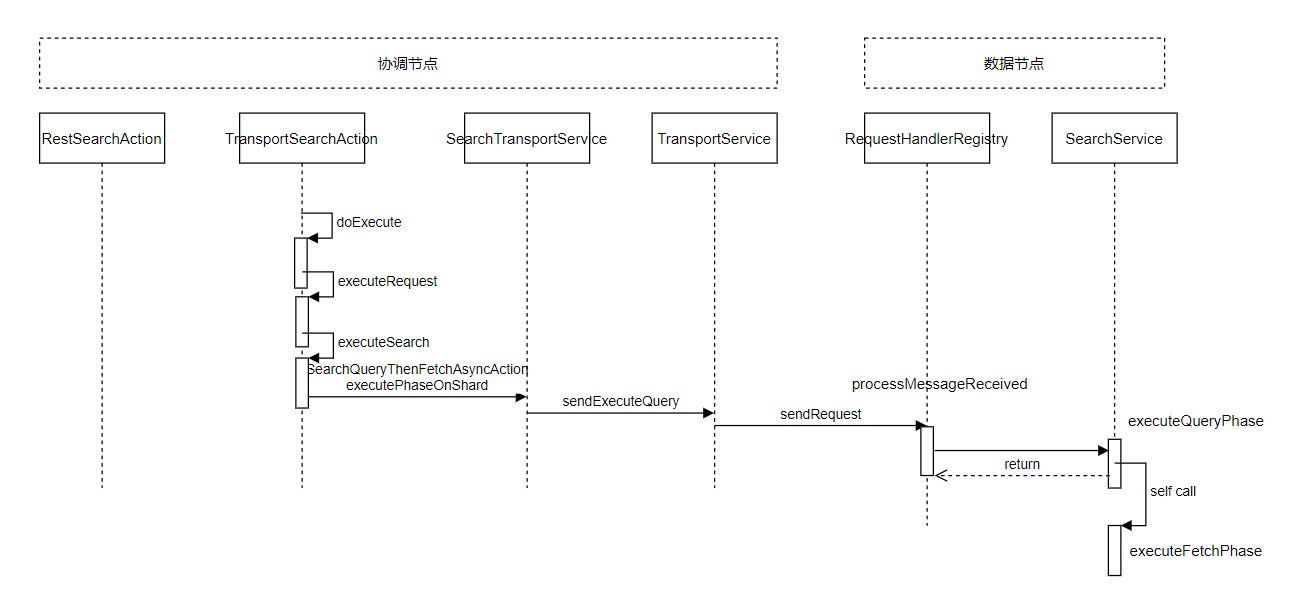
协调节点向数据节点发起请求时,是在 TransportService 中,在这个地方断点基本能抓住调用栈,关于请求的命名也遵循着套路,例如 getById 的请求是 TransportGetAction。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号