


本文从一个示例入手,从代码层面分析 elastic search 查询文档的完整过程。
新建索引 cn-msg,设置 3 分片,1 副本
PUT localhost:9200/cn-msg
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
写入文档
POST localhost:9200/cn-msg/_doc
{
"messageId": "6a5955ee28ec4ce483ebb8a4d6a4d214",
"status": 1
}
查询文档
POST localhost:9200/cn-msg/_search
{
"query": {
"match": {
"messageId": "6a5955ee28ec4ce483ebb8a4d6a4d214"
}
}
}
接收到查询文档请求的节点称为协调节点,协调节点收到请求,将查询请求转发给 3 个分片所在的节点,等待这 3 个分片的响应,汇总响应发送给客户端(暂且可以这么认为,这里还有一步 query then fetch)。
转发查询请求:
// org.elasticsearch.action.search.AbstractSearchAsyncAction#run
for 循环遍历 3 个分片,向 3 个分片发送查询请求:
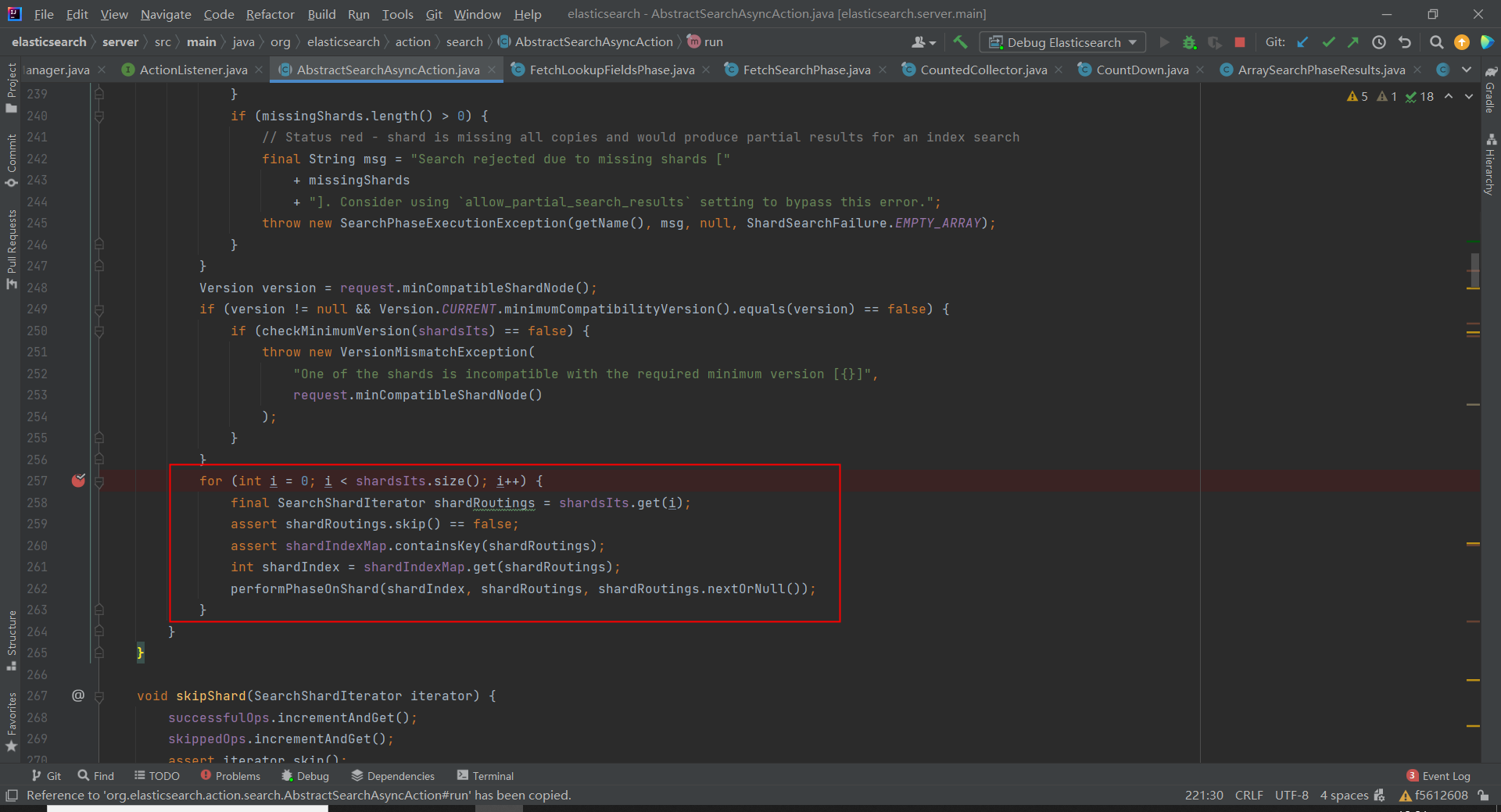
协调节点收到分片的响应后,保存响应并检查是否所有的响应都已收到:
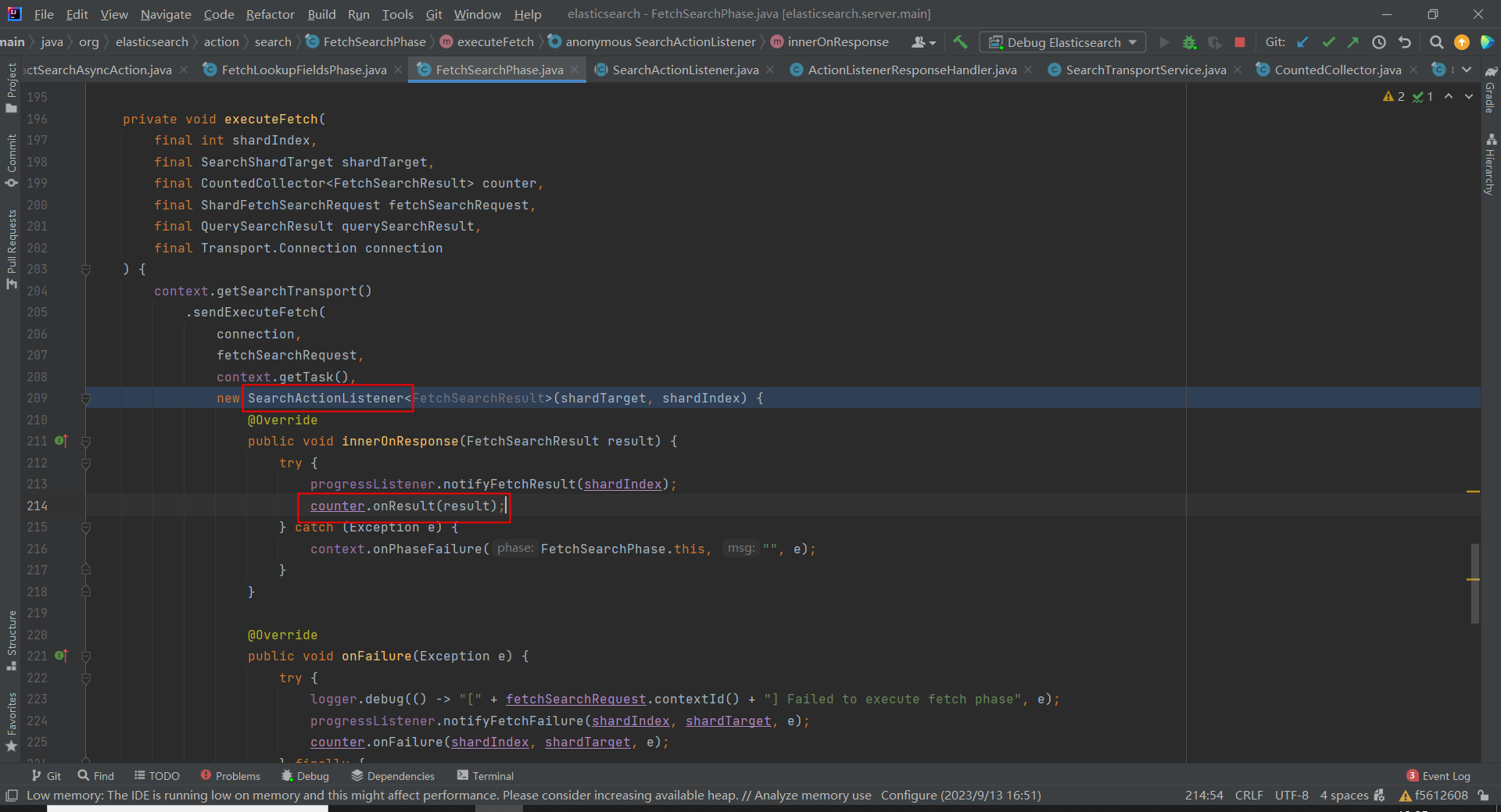
couter 对象的注释如下:

/** * This is a simple base class to simplify fan out to shards and collect their results. Each results passed to * {@link #onResult(SearchPhaseResult)} will be set to the provided result array * where the given index is used to set the result on the array. */ final class CountedCollector<R extends SearchPhaseResult> { private final ArraySearchPhaseResults<R> resultConsumer; private final CountDown counter; private final Runnable onFinish; private final SearchPhaseContext context;
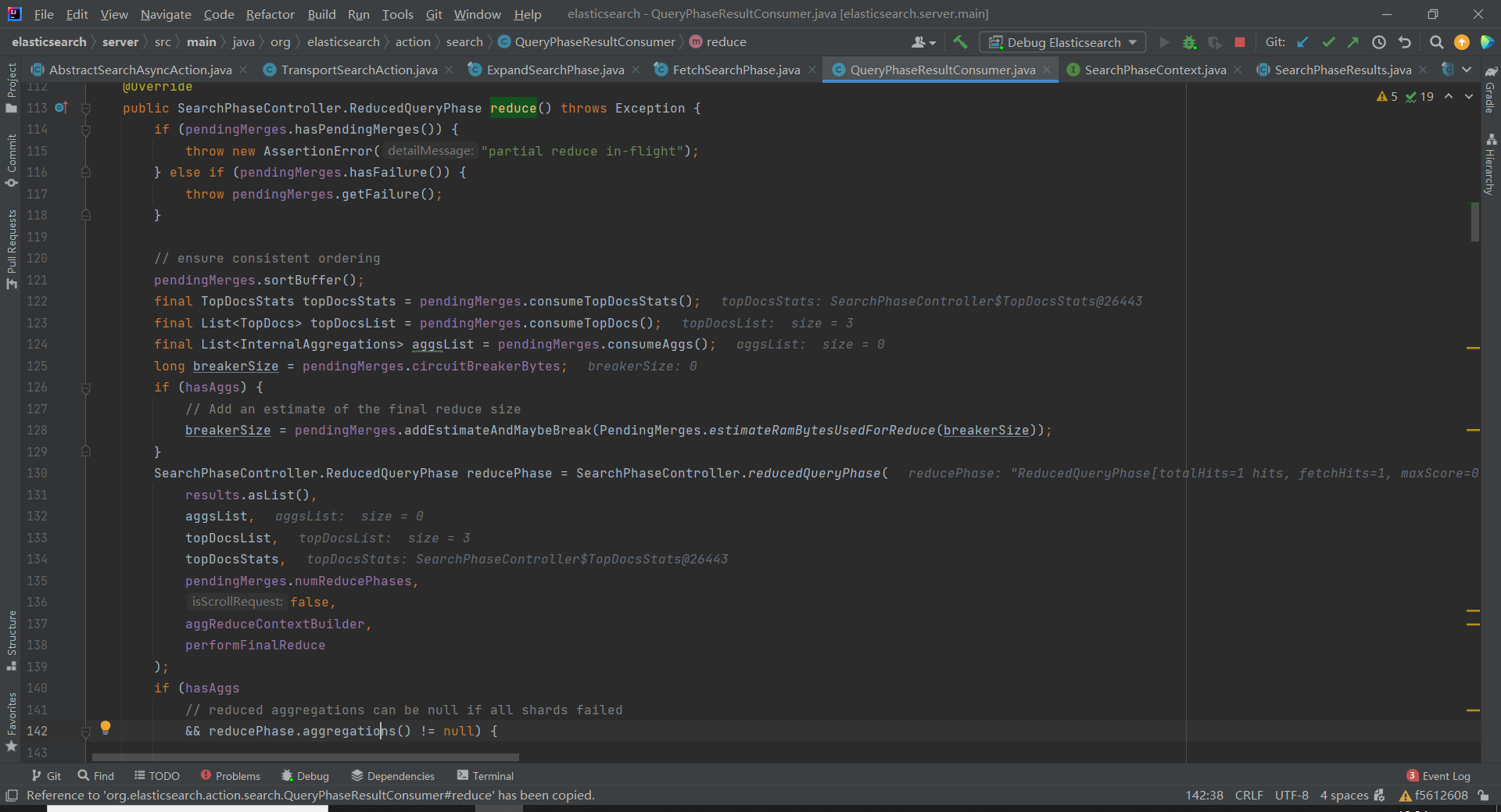
可以看出这是一个存储分片响应的抽象过的容器,当所有的分片响应都收到后,即 CountDown 值为 0,则可以对文档 id 进行汇总(排序,聚合):
// org.elasticsearch.action.search.QueryPhaseResultConsumer#reduce
但是,协调节点收到的分片响应仅包含 doc id,如果要获取文档数据还得再发送一次 fetch 请求:
// org.elasticsearch.action.search.FetchSearchPhase#innerRun
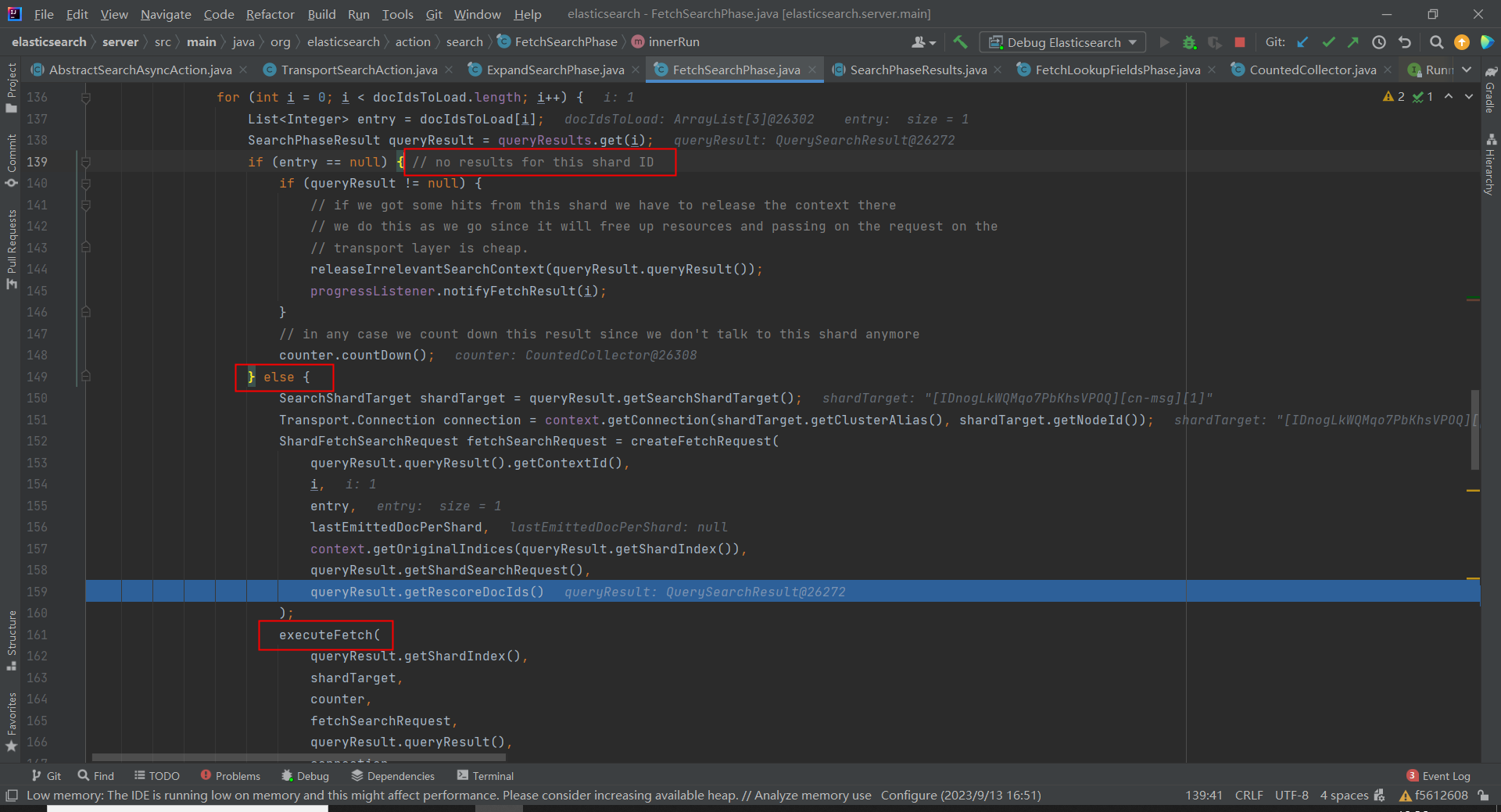
当协调节点接收到所有存在数据的分片节点的 fetch 响应后,就可以发送响应给客户端了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通