机器学习1.1-监督学习和非监督学习
监督学习
-
必须明确目标变量的值,以便算法可以发现特征和目标变量之间的关系。给定一组数据,我们就该知道输出结果应该是什么样子,并且知道输出结果和输入结果之间有一个特定的关系。
-
样本集:训练数据+测试数据
训练样本 = 特征 + 目标变量(label: 分类-离散值/回归-连续值)
特征通常是训练样本集的列,他们是独立测量得到的
目标变量:目标是机器学习预测算法的测试结果(在分类算法中目标变量是离散值 :真/假;在回归算法中目标变量是连续值:1~100)
-
监督学习需要注意的问题:
偏置方差的权衡
功能的复杂性和训练数据的数量
输出空间的维数
噪声中的输出值
非监督学习
-
非监督学习解决的问题是,在未添加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有反馈来评估潜在的解决方案。
-
无监督学习和统计密度估计问题密度相关,其中还包括寻求,总结和解释数据的主要特点等诸多技术,这和数据挖掘息息相关。
-
数据中不包含类别信息,也不会给定目标值。
-
非监督学习包括的类型有:
聚类:在无监督学习中,将数据分成由类似的对象组成多个类的过程称为聚类;
密度估计:通过样本分布的紧密程度,来估计与分组的相似性
此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维或者三维图形更加直观地展示数据信息。
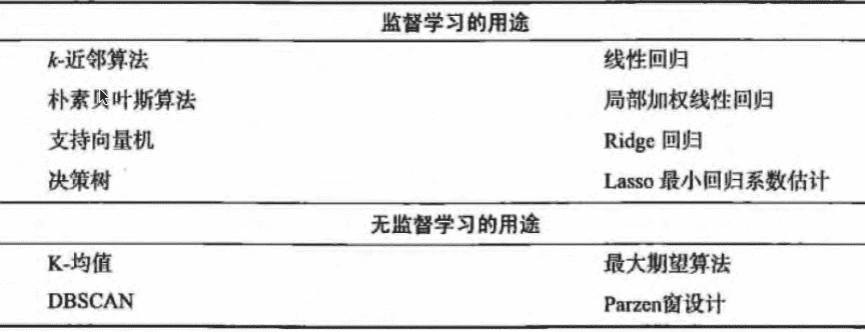
算法汇总

 浙公网安备 33010602011771号
浙公网安备 33010602011771号