
锁相关
关于锁
锁的作用:避免并发请求时对同一个数据对象同时修改,导致数据不一致
怎么加锁:
事务T1在对某个数据对象R1操作之前,先向系统发出请求,对其加锁L1,之后,事务T1对该数据对象R1有了相应的控制,在T1释放L1之前,其它事务不能修改R1
加锁对数据库的影响:
锁等待,锁L1锁定某个对象R1,锁L2等待该锁释放,如果不释放,会一直等待,或者达到系统预设的超时阈值后报错(回滚整个事务或只回滚当前的SQL)
死锁,锁资源请求产生了回路,例如:L1等待L2释放,L2等待L3释放,L3等待L2释放,死循环
锁类型:排他锁(X),共享锁(S)
通常的锁范围:全局锁(global lock),表锁(table lock),行锁(row lock)
表锁一般是在server层实现
InnoDB表,还有个IS/IX表级锁,以及auto-inc锁
MyISAM锁
默认是表锁,读写互斥,仅只读共享
读锁,LOCK TABLE user READ,自身只读,不能写;其他线程仍可读,不能写。多个线程都可提交read lock
写锁,LOCK TABLE user WRITE,自身可读写;其他线程完全不可读写
写锁优先级高于读锁
SELECT自动加读锁(共享锁)
其他DML、DDL自动加写锁(排他锁)
释放锁,执行unlock tables,执行lock table,显示开启一个事务,连接断开或者被kill
InnoDB锁
默认是行锁(row lock)
InnoDB是通过在索引记录上加锁,实现行锁
因此,没有索引时就无法实现行锁,而升级成全表记录锁,等同于表锁
锁类型lock_mode:
LOCK_S,行级共享锁,可用于表锁、行锁
不允许其他事务修改被锁定的行,只能读
select...lock in share mode
自动提交模式下的普通select是一致性非锁定读,不加锁
LOCK_X,行级排他锁,可用于表锁、行锁
对一条记录进行DML时,需至少加上排他锁
insert ... on duplicate key update
锁范围视情况而定,可能是record lock、next-key lock,或者可能只有gap lock
执行DML,或select...for update
意向锁,InnoDB特有,加载在表级别上的锁
LOCK_IS,事务T想要获得表中某几行的共享锁,表级锁
LOCK_IX,事务T想要获得表中某几行的排他锁,表级锁
意向锁是加在数据表B+树结构的根节点,也就是对整个表加意向锁
意向锁的作用:避免在执行DML时,对表执行DDL操作,导致数据不一致
LOCK_AUTO_INC,自增锁
5.1之后新增innodb_autoinc_lock_mode选项,表级锁
当innodb_autoinc_lock_mode = 1时,其实是个轻量级的互斥量(mutex)
1,默认设置,快速mutex加锁,可预判行数时使用新方式,不可预判时仍旧使用表锁,会造成autoinc列自增空洞,不过影响很小。LOAD DATA,INSERT...SELECT时,还用旧模式
0,传统表级加锁模式,每次请求都会等待表锁,SQL结束后释放。可以保证主从INSERT...SELECT一致性,但当有大INSERT时,并发效率很低
2,使用新方式,不退化,不适合replication环境(可能造成主从数据不一致)
InnoDB锁兼容模式
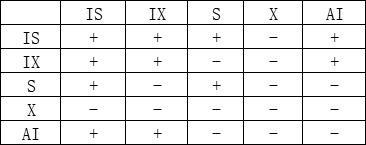
全局锁
global read lock
加锁:FTWRL,FLUSH TABLES WITH READ LOCK,实际上是加了2个锁:全局读锁,全局COMMIT锁
关闭实例下的所有表,并加上全局读锁,防止被修改,知道提交UNLOCK TABLES
xtrabackup时可分开备份InnoDB和MyISAM,或者不执行--master-data

MDL锁
MDL,meta data lock
全局读锁、TABLESPACE/SCHEMA、表、FUNCTION/PROCEDURE/TRIGGER/EVENT等多种对象上加的锁
5.6开始引入
事务开启后,会锁定表的meta data lock,其他会话对表有DDL操作时,均需等待mdl释放后方可继续
超时阈值定义:lock_wait_timeout
锁模式 作用
MDL_INTENTION_EXCLUSIVE 意向排他锁 GLOBAL对象、SCHEMA对象操作会加此锁
MDL_SHARED 共享锁,只访问元数据,而不访问数据 比如表结构 FLUSH TABLES with READ LOCK
MDL_SHARED_HIGH_PRIO 仅对MyISAM存储引擎有效,用于访问information_scheam表
MDL_SHARED_READ 共享读锁,SELECT查询 访问表结构并且读表数据
MDL_SHARED_WRITE 共享写锁,DML语句 访问表结构并且写表数据
MDL_SHARED_READ_ONLY 只读锁,常见于LOCK TABLE X READ
MDL_SHARED_NO_WRITE FLUSH TABLES xxx,yyy,zzz READ 可升级锁,访问表结构并且读写表数据,并且禁止其它事务写。
MDL_SHARED_NO_READ_WRITE FLUSH TABLE xxx WRITE可升级锁,访问表结构并且读写表数据,并且禁止其它事务读写。
MDL_EXCLUSIVE 排他锁,可以修改字典和数据
MDL锁观察
启用MDL检测
update setup_consumers set enabled='YES' where name='global_instrumentation';
update setup_instruments set enabled='YES' where name='wait/lock/metadata/sql/mdl';
观察MDL锁
select * from performance_schema.metadata_locks\G
select * from sys.schema_table_lock_waits\G
InnoDB自旋锁,spin lock
保护共享资源而提出的一种锁机制,和互斥锁类似,任何时刻下都只能有一个持有者,控制事务并发时的CPU时间片分配
用于控制InnoDB内部线程调度而生的轮询检测
innodb_spin_wait_delay,控制轮询间隔,默认6秒
事务并发非常高,CPU忙不过来的时候,事务处于sleep状态,spin round可能也会很高
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 23
OS WAIT ARRAY INFO: signal count 14
RW-shared spins 0, rounds 73, OS waits 5
RW-excl spins 0, rounds 1114, OS waits 5
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 73.00 RW-shared, 1114.00 RW-excl, 0.00 RW-sx
------------
rounds,表示spin一次空转多少圈,也就是返回来询问的次数
OS waits,表示sleep,当突然增长比较快时,说明latch争用比较严重
BACKUP锁
8.0新增功能,为了保证备份一致性,需要BACKUP_ADMIN权限
发起备份前,执行LOCK INSTANCE FOR BACKUP, 备份结束后执行UNLOCK INSTANCE解锁
BACKUP LOCK的作用是备份期间依旧允许DML操作,以及session级的DDL操作,例如生成临时表。但是建表、改表、删表、REPAIR、TRUNCATE、OPTIMIZE被禁止
多个会话可并行持有该锁
InnoDB行锁实现
基于索引实现
逐行检查,逐行加锁
没有索引的列上需要加锁时,会先对所有记录加锁,再根据实际情况决定是否释放锁
辅助索引上加锁时,同时要回溯到主键索引上再加一次锁
InnoDB行锁范围(粒度)
record lock (LOCK_REC_NOT_GAP),单个记录上的锁
仅记录锁,仅锁住记录本身,不锁其前面的GAP
RC下的行锁大多数都是这个锁类型
RR下的主键、唯一索引等值条件下加锁通常也是这个锁类型
RR下的非唯一索引加锁时(LOCK_ORDINARY),也会同时回溯到主键加LOCK_REC_NOT_GAP锁。但唯一性约束检测时,即使是在RC下,总是要先加LOCK_S|LOCK_ORDINARY锁
gap lock (LOCK_GAP),间隙锁,锁定一个范围,但不包含记录本身
只锁住索引记录之间、或第一条索引记录(INFIMUM)之前、又或最后一条索引记录(SUPREMUM)之后的范围,并不锁住记录本身
RR级别下,对非唯一索引记录当前读(current-read)时,除了对命中的记录加LOCK_ORDINARY锁,还会对该记录之后的GAP加LOCK_GAP,这是为了保证可重复读的需要(避免其他事务插入数据,造成幻读)
next-key lock = record lock + gap lock (LOCK ORDINARY),锁定一个范围和本身
著名的next-key lock,锁住记录本身,及其前面的GAP
在RR级别下,利用next-key lock来避免产生幻读
当innodb_locks_unsafe_for_binlog=1时,LOCK_ORDINARY会降级为LOCK_REC_NOT_GAP,相当于降级到RC,这个参数8.0后弃用
LOCK_INSERT_INTENTION 意向插入锁,是GAP Lock的一种
当插入索引纪录的时候用来判断是否有其他事务的范围锁冲突,如果有就需要等待
同一个GAP中,只要不是同一个位置就可以有多个插入意向锁并存。例如[5]~[10]区间中,同时插入[6]、[8]就不会相互冲突阻塞,而同时插入[9]就会引发冲突阻塞等待
gap lock仅用于防止往gap上写入新记录(避免幻读),因此无论是S-gap还是X-gap锁,其实作用是一样的
LOCK_INSERT_INTENTION和LOCK_GAP并不兼容

gap和gap并不冲突
gap只和insert intention锁冲突
select ... for update时,已存在的记录,加LOCK_REC_NOT_GAP(SK索引加LOCK_ORDINARY),不存在的记录,加LOCK_GAP
RR级别&等值条件加锁
主键索引是LOCK_REC_NOT_GAP (record lock)
唯一辅助索引是LOCK_REC_NOT_GAP (record lock)
普通辅助索引是LOCK_ORDINARY (next-key lock)
没有索引的话,则是全表范围LOCK_ORDINARY (next-key lock)
RC下,默认只有LOCK_REC_NOT_GAP,只有在检查外键约束或者duplicate key检查时才加LOCK_ORDINARY LOCK | S
RR & innodb_locks_unsafe_for_binlog = 1 (<=5.7),降级为RC
两种InnoDB读模式
快照读(read view, snapshot read)
基于read view读可见版本,不加锁,由基于某个时间点的一组InnoDB内部(活跃)事务构建而成的列表
start transaction with consistent read + select
普通select
当前读(current read)
读(已提交)最新版本,并加锁
S锁,select...lock in share mode
X锁,select...for update/DML
一致性非锁定读
consistent non-locking read
通过MVCC机制,基于当前时间点read view读取
默认情况下,不加锁
InnoDB锁特点
显示锁(explicit-lock)
select * from t where id = xxx for update / LOCK IN SHARE MODE
隐式锁(implicit-lock)
降低加锁开销,减少内存消耗
创建锁时,若无冲突的话,并不直接加锁
其他事务扫描到该行记录时,发现有个隐式锁,再升级成显示锁
对插入操作通常不加锁,当另外的事务检测到冲突时,再加锁
update t set c2=? where c1=?
修改主键时,也会导致辅助索引上加隐式锁,反之也如此
和其他session有冲突时,隐式锁转换为显示锁
InnoDB行锁

create table tt1(
a int not null,b int default NULL,primary key(a),key b(b)
);
insert into tt1 values (1,1),(3,1),(5,3),(7,6),(10,8);

T1对表加IX锁,对b=3的所有记录加X锁,T1为一致性锁定读,对于聚集索引,仅对列a=5的行加上record lock。对于辅助索引,锁定的范围是(1,6)
T2执行select * from tt1 where a=5 lock in share mode时,对表加IS锁,对a=5的行加S锁,与T1冲突,为一致性锁定读
T2执行insert into时,T1对b列的gap lock范围为(1,6),符合插入意向锁范围,全会锁等待

都不会锁等待
InnoDB锁案例
create table t1(
c1 int not null default 0,c2 int not null default 0,c3 int not null default 0,c4 int not null default 0,primary key(c1),key idxc2(c2)
);
insert into t1 values (0,0,0,0),(1,1,1,0),(3,3,3,0),(4,2,2,0),(6,2,5,0),(8,6,6,0),(10,4,4,0);
+----+----+----+----+
| c1 | c2 | c3 | c4 |
+----+----+----+----+
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 |
| 3 | 3 | 3 | 0 |
| 4 | 2 | 2 | 0 |
| 6 | 2 | 5 | 0 |
| 8 | 6 | 6 | 0 |
| 10 | 4 | 4 | 0 |
+----+----+----+----+

会阻塞
T1对表加IX锁,对c1=3的行加X锁,具有排他性不允许对该行显示加任何锁,T2对表加IS锁,对c1=3的行加S锁
T1,T2都是一致性锁定读

会阻塞
T1对表加IS锁,对c1=3的行加S锁,T2对表加IX锁,对c1=3加X锁具有排他性,与T1有冲突
T1,T2都是一致性锁定读

不会阻塞
T1对表加IX锁,对c1=3的行加X锁具有排他性,T2没有显示加任何锁
T1是一致性锁定读,T2是一致性非锁定读(MVCC)
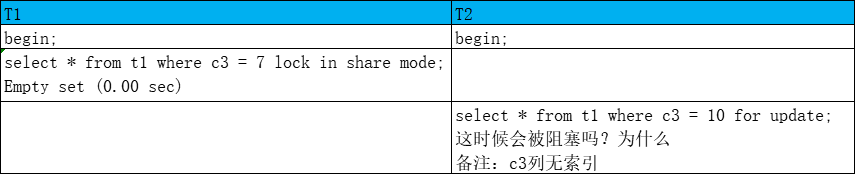
会阻塞
T1对表加IS锁,没有索引,没有c3=7的记录,对所有行加S锁,T2对表加IX锁,没有索引,没有c3=10的记录,对所有行加X锁具有排他性
T1,T2都是一致性锁定读
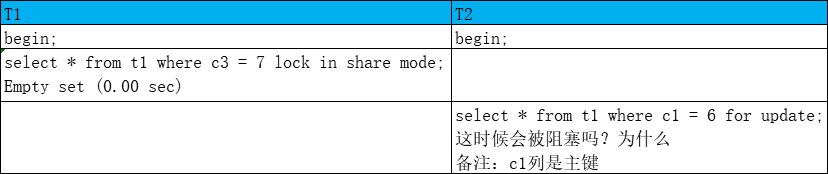
会阻塞
T1对表加IS锁,没有索引,没有c3=7的记录,对所有行加S锁,T2对表加IX锁,主键索引,对c1=6的记录加X锁具有排他性
T1,T2都是一致性锁定读

不会被阻塞,没有找到就没有锁定,都是gap lock
T1:(6,无穷大),LOCK_GAP | S
T2:(6,无穷大),LOCK_GAP | X

会被阻塞
T1:(6,无穷大),LOCK_GAP | S
T2:(6,无穷大),INSERT_INTENTION_LOCK | X

会被阻塞
T1:C3列 (0,无穷大),LOCK_ORDINARY | S
T1:C1列 (0,1,3,4,6,8,10),LOCK_REC_NO_GAP | S
T2:(6),LOCK_REC_NO_GAP | X
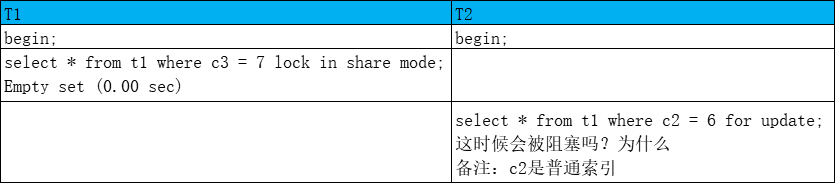
会阻塞
T1对表加IS锁,没有索引,没有c3=7的记录,对所有行加S锁,T2对表加IX锁,普通索引,对c2=6的记录加X锁具有排他性
T1,T2都是一致性锁定读

会阻塞
T1对表加IX锁,对行c2=2的所有行加X锁,因为是普通索引且有主键降级为行锁,T2对表加IX锁,普通索引,对c2=2的所有记录加X锁具有排他性,如果T2中没有c2查询条件,只有c3查询条件,因为c3列无索引,且没有这条记录,将对所有行加X锁
T1,T2都是一致性锁定读

不会阻塞
T1对表加IX锁,对行c2=2的所有行加X锁,因为是普通索引且有主键降级为行锁,T2对表加IX锁,对c2=3的所有记录加X锁,因为是普通索引且有主键降级为行锁,在此基础上找c3=7的记录,没有找到记录。T1,T2加锁不冲突。
T1,T2都是一致性锁定读

会阻塞
T1对表加IX锁,对行c2=2的所有行加X锁,因为是普通索引且有主键降级为行锁,T2对表加IX锁,对c1=4的行加X锁,刚好是T1中c2=2的行,在此基础上找c3=10的记录,没有找到记录。T1,T2加锁冲突。
T1,T2都是一致性锁定读
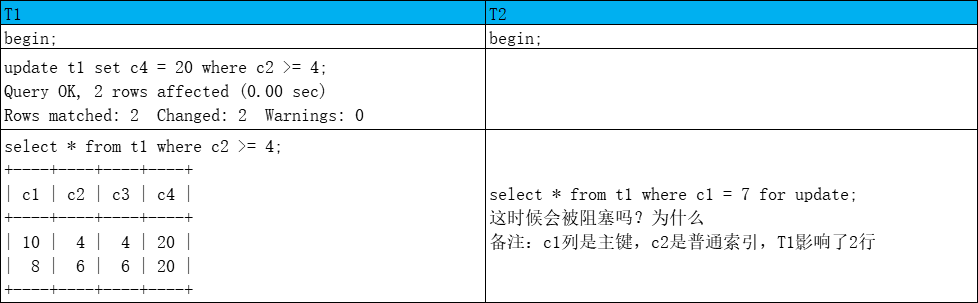
不会阻塞
T1对表加IX锁,对行c2>=4的所有行加X锁,因为是普通索引且有主键降级为行锁,T2对表加IX锁,对c1=7的行加X锁,不在T1加锁范围内
T2是一致性锁定读
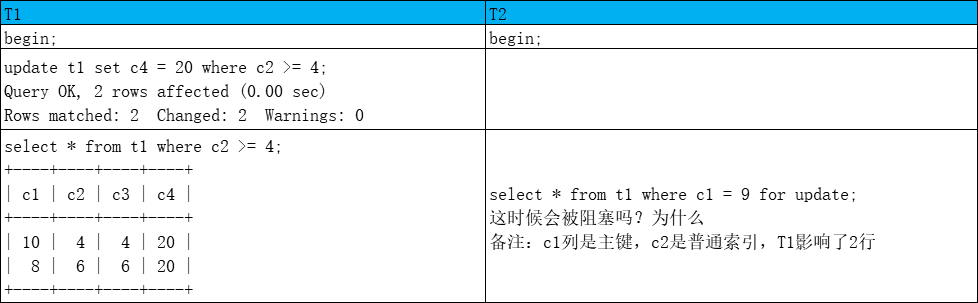
不会阻塞

不会,gap lock兼容

会阻塞
T1是next-key lock, T2是c1=9 lock_s | next-key lock c2=5 insert intention lock

不会阻塞
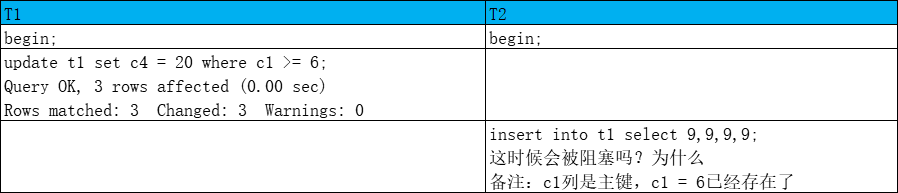
会阻塞
第一次对主键索引加锁不会对二级索引加锁,第一次对二级索引加锁还会对主键索引加锁

阻塞,innodb的特殊情况
小于等于情况特殊

不会阻塞

会阻塞,比较特殊的案例
也就是RC其实也扫描下一条记录,只不过是加锁然后释放

会阻塞,理由同上

不会阻塞

会阻塞

不会阻塞

会阻塞

会阻塞
T1加gap lock
T2加共享next key lock,然后是insert intention lock,最后转变为lock_rec_not_gap

会阻塞
先是共享的next-key lock,然后是insert intention lock,最后转变为lock_rec_not_gap

不会阻塞
gap lock和gap lock兼容
行锁表现测试
create table t (
c1 int not null, c2 int default null, c3 int default null, c4 int default null, primary key (c1), unique key c2(c2), key c3(c3)
);
insert into t values (1,1,1,1),(10,10,10,10),(20,20,20,20),(30,30,30,30);
#1、主键等值条件
select * from t where c1 = 1 for update;
只在c1 = 1上加LOCK_X | LOCK_REC_NOT_GAP

#2、 主键等值查询,更新索引列
update t set c3 = 2 where c1 = 1;
在c1 = 1上加LOCK_X | LOCK_REC_NOT_GAP
在c3 = 1上加LOCK_X | LOCK_REC_NOT_GAP


#3、主键等值条件,但数据不存在
select * from t where c1 = 3 for update;
在下一条记录(c1 = 10)前面的GAP上加LOCK_X | LOCK_GAP,update也是如此
#4、主键范围条件
select * from t where c1 >= 20 for update;
在c1 = 20上加LOCK_X | LOCK_REC_NOT_GAP
在c1 > 20上加LOCK_X | LOCK_ORDINARY,包括supremum记录
#5、主键范围条件更新,包含索引列
update t set c3 = 32 where c1 >= 30;
在c1 = 30上加LOCK_X | LOCK_REC_NOT_GAP
在c1 > 30上加LOCK_X | LOCK_ORDINARY,包括supremum记录
在c3 = 30上加LOCK_X | LOCK_REC_NOT_GAP
此时,c3 = 32上需要加锁吗?该加什么锁?
#6、主键范围条件
select * from t where c1 <= 10 for update;
在c1 = 10上加LOCK_X | LOCK_ORDINARY
在c1 = 20先加LOCK_X | LOCK_ORDINARY,再判断c1 = 20不符合条件(但在RR下不会释放该锁,只有在RC下才会释放)

#7、唯一索引等值条件
select * from t where c2 = 1 for update;
在c2 = 1加LOCK_X | LOCK_REC_NOT_GAP
在c1 = 1加LOCK_X | LOCK_REC_NOT_GAP
二级索引上锁,需要回溯到主键索引也上锁
#8、普通索引等值条件
select * from t where c3 = 1 for update;
在c3 = 1加LOCK_X | LOCK_ORDINARY
在c3 = 10前面的GAP加LOCK_X | LOCK_GAP
对应的c1 = 1加LOCK_X | LOCK_REC_NOT_GAP
#9、普通索引范围条件
select * from t where c3 <= 1 for update;
在c3 <= 1加LOCK_X | LOCK_ORDINARY
在c3 = 10前面的GAP加LOCK_X | LOCK_ORDINARY
在相应的主键c1 = 1加LOCK_X | LOCK_REC_NOT_GAP
#10、普通索引范围条件
select * from t where c3 >= 30 for update;
在c3 >= 30上加LOCK_X | LOCK_ORDINARY,包括supremum记录
在主键c1 = 30上加LOCK_X | LOCK_REC_NOT_GAP
InnoDB死锁
如果多个事务都需要访问数据,而另一个事务已经以互斥方式锁定该数据,则会发生死锁
事务A等待事务B,同时事务B等待事务A,会产生死锁
InnoDB有死锁检测线程,如果检测到死锁,会马上抛出异常并回滚一个事务(另一个继续执行)
怎么判断是否会发生死锁
事务T1需要等待事务T2,画一条T1到T2的线
以此类推
最后整个图如果有回路就表示有死锁

create table t1 (
c1 int not null default 0,c2 int not null default 0,c3 int not null default 0,c4 int not null default 0,primary key (c1),key idxc2(c2)
);
insert into t1 values(0,0,0,0),(1,1,1,0),(3,3,3,0),(4,2,2,0),(6,8,5,0),(7,6,6,10),(10,10,4,0);
+----+----+----+----+
| c1 | c2 | c3 | c4 |
+----+----+----+----+
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 |
| 3 | 3 | 3 | 0 |
| 4 | 2 | 2 | 0 |
| 6 | 8 | 5 | 0 |
| 7 | 6 | 6 | 10 |
| 10 | 10 | 4 | 0 |
+----+----+----+----+
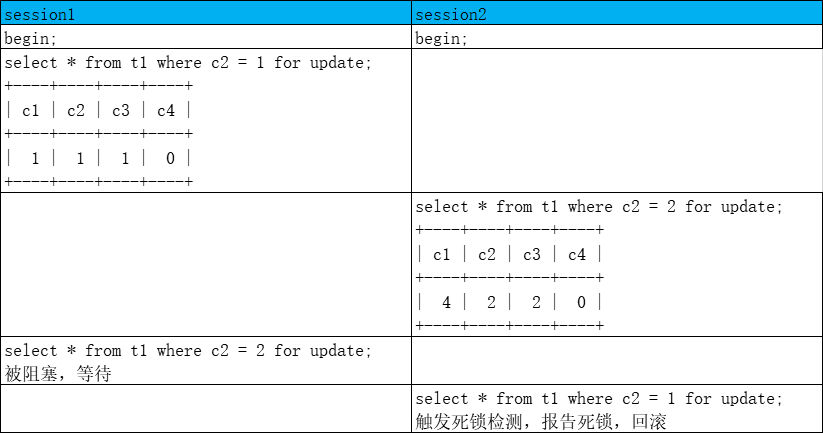


create table t1(i int, primary key(i)); insert into t1 values (1);


show engine innodb status\G
只显示最后的死锁信息
设置innodb_print_all_deadlocks = 1
在日志中记录全部死锁信息
自动检测死锁,并自动回滚某个事务
优先回滚小事务,影响较小的事务,比如谁产生的undo更少
表锁不会发生死锁,不过要调小innodb_lock_wait_timeout
高并发(秒杀)场景中,关闭innodb_deadlock_detect选项,降低死锁检测开销,提高开发效率
偶尔死锁不可怕,频繁死锁才需要关注
程序中应有事务失败检测及自动重复提交机制
多用小事务,并及时显示提交/回滚
加FOR UPDATE、LOCK IN SHARE MODE锁时,最好降低事务隔离级别,例如用RC级别,降低死锁发生概率,也可以降低锁定粒度
事务中涉及多个表,或者涉及多行记录时,每个事务的操作顺序都要保持一致,降低死锁概率,最好用存储过程/函数固化
通过索引优化SQL效率,降低死锁概率
死锁不是"锁死",死锁会快速检测到,快速回滚。而"锁死"则是长时间锁等待
锁等待和死锁不是一回事
8.0新增的特性
select * from d for update nowait;
select * from d for update skip locked;
常见SQL的锁模式
SELECT...FROM,一致性非锁定读,除非是serializable隔离级别(LOCK_ORDINARY | S)
LOCK IN SHARED MODE,LOCK_ORDINARY | S
FOR UPDATE,LOCK_ORDINARY | X
UPDATE/DELETE,LOCK_ORDINARY | X
普通INSERT,加锁LOCK_INSERT_INTENTION | X,当写入请求检测到有重复值时,会加锁LOCK_ORDINARY | S,可能引发死锁
INSERT...ON DUPLICATE KEY UPDATE,LOCK_ORDINARY | X
REPLACE,没冲突/重复时,和INSERT一样(LOCK_INSERT_INTENTION | X),否则LOCK_ORDINARY | X
INSERT INTO t SELECT ... FROM s,t表加LOCK_REC_NOT_GAP | X,事务隔离级别为RC或者启用innodb_locks_unsafe_for_binlog时,s表上采用无锁一致性读,否则s表加LOCK_ORDINARY | X (即:RC不加锁,RR加next-key lock)
CREATE TABLE ... SELECT,同INSERT ... SELECT
REPLACE INTO t SELECT ... FROM s WHERE 或 UPDATE t ... WHERE col IN (SELECT ... FROM s ...),都会在s表上加LOCK_ORDINARY | S
AUTO_INCREENT列上写新数据时,索引末尾加排他record lock
请求自增列计数器时,InnoDB使用一个AUTO-INC mutex,但只对请求的那个SQL有影响(lock_mode = 1时)
有外键约束字段上进行IUD操作时,除了自身的锁,还会在外表约束列上同时加共享record lock
备注:以上next-key lock只发生在RR隔离级别
InnoDB锁优化
避免myisam,改用innodb
尽量能让所有的数据检索都通过索引来完成,从而避免InnoDB因为无法通过索引键加锁而升级为表锁(全表所有行)锁定
创建合适的索引,尽量不要多个单列索引
合理设计索引,让InnoDB在索引键上面加锁的时候尽可能准确,尽可能的缩小锁定范围,避免造成不必要的锁定而影响其他Query的执行
尽可能减少范围数据检索过滤条件,降低过多数据被加上next-key lock
多使用primary key或unique key
避免大事务,长事务
在业务低峰期DDL
执行DDL/备份前,先判断是否有长SQL、未提交事务、及其他的lock wait事件
必要时将隔离级别改为rc
查看InnoDB锁
show processlist
show engine innodb status
sys var: innodb_status_output & innodb_status_output_locks
sys.innodb_lock_waits & sys.schema_table_lock_waits & information_schema.innodb_trx
PFS.data_locks
PFS.data_lock_waits
PFS.metadata_locks
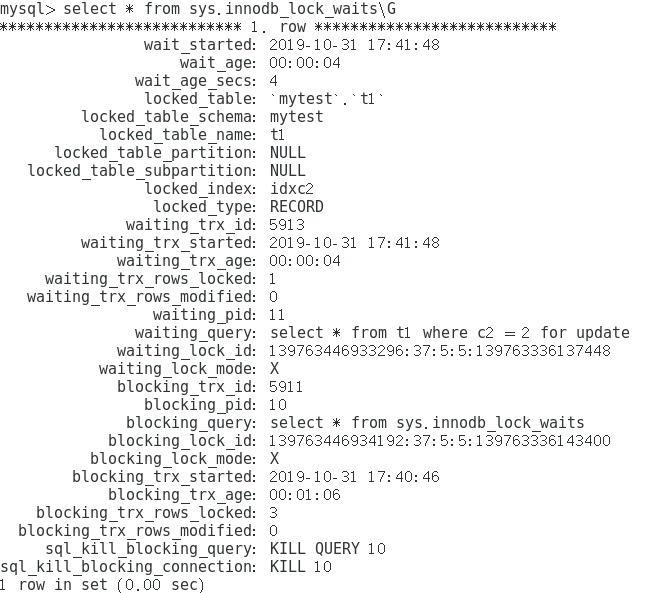
锁状态监控
通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况show status like 'innodb_row_lock%';对于各个状态说明如下:Innodb_row_lock_current_waits:当前正在等待锁的数量;Innodb_row_lock_time:从系统启动到现在锁定总时间长度;Innodb_row_lock_time_avg:每次等待所花平均时间;Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间长度;Innodb_row_lock_waits:系统启动到现在总共等待的次数;
对于这5个状态变量,比较重要的是:Innodb_row_lock_time_avg,Innodb_row_lock_waits,Innodb_row_lock_time。尤其是当等待次数很高,而且每次等待时长也很大的时候,我们就要分析系统中为什么有这么多的等待,然后根据分析结果来制定优化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?