

索引
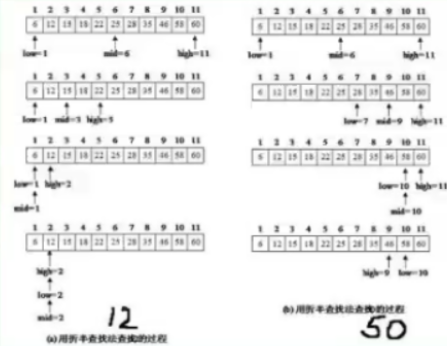
二分查找法/折半查找法
一种在有序数组中查找某一特定元素的搜索算法
二分查找法的优点是比较次数少,查找速度快,平均性能好。其缺点是要求待查表为有序表,且插入删除困难。因此,二分查找方法适用于不经常变动而查找频繁的有序列表
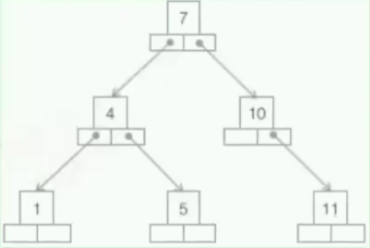
二叉树,binary tree
二叉树的每个节点至多只有两棵子树(不存在度大于2的节点),二叉树的子树有左右有序之分,次序不能颠倒
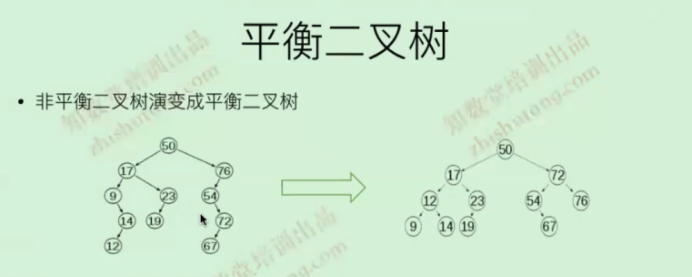
平衡树,平衡二叉树
不平衡树会通过自旋,变成平衡树
平衡树和二叉查找树最大的区别:前者是平衡的,后者未必
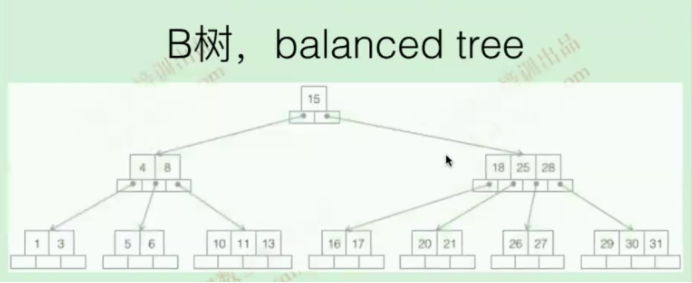
B树
一个节点可以拥有多于2个子节点的多叉查找树
适合大量数据的读写操作,普遍运用在数据库和文件系统
一棵m阶(比如m=4阶)的B树满足下列条件:
树中每个节点至多有m个(4个)子节点
除根节点和叶子节点外,其它每个节点至少有m/2个子节点
若根节点不是叶子节点,则至少有2个子节点
所有叶子节点都出现在同一层,叶子节点不包含任何键值信息
有k个子节点的非叶子节点恰好包含有k-1个键值(索引节点)
B+树
B+树是B树的变体,也是多路搜索树,B+树有自己的特点
所有数据都保存在叶子节点
所有的叶子节点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接
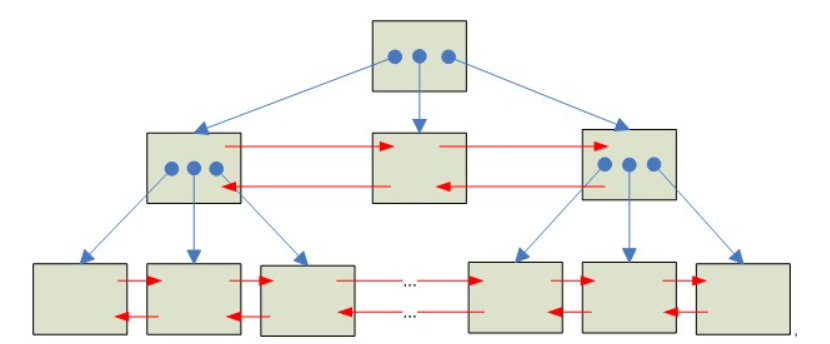
假设有个表,只有一个INT列,且设置为主键,无其他更多列
B+树中,每个非叶子节点开销:6B(row header固定开销) + 4B(主键为INT类型) + 4B(指向叶子节点的指针开销)
每行数据开销:14B + 6B(DB_TRX_ID) + 7B(DB_ROLL_PTR) = 27B
每个非叶子节点page存储约(16*1024 - 128page header)/14 = 1161行记录
每个叶子节点page存储约(16*1024 - 128page header)/27 = 600行记录
因此,一个三层高的B+树,约可存储记录1161*1161*600 = 8亿记录
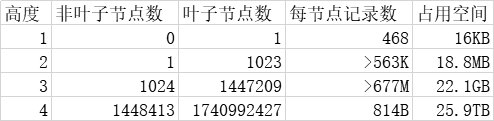
这也是为啥MySQL数据页是16K的原因,存储的数据更多了
什么是索引
相当于书名,用于快速检索
优点:
提高数据检索效率
提高表间的JOIN效率
利用唯一性索引,保证数据的唯一性
提高排序和分组效率
缺点:
消耗更多物理存储
数据变更时,索引也需要更新,降低更新效率
MySQL索引类型
按数据结构分类:
BTREE索引,是B+树(B+ Tree)的简写
HASH索引,只用于HEAP表
空间索引,很少用
Fractal Tree索引,用于TokuDB表
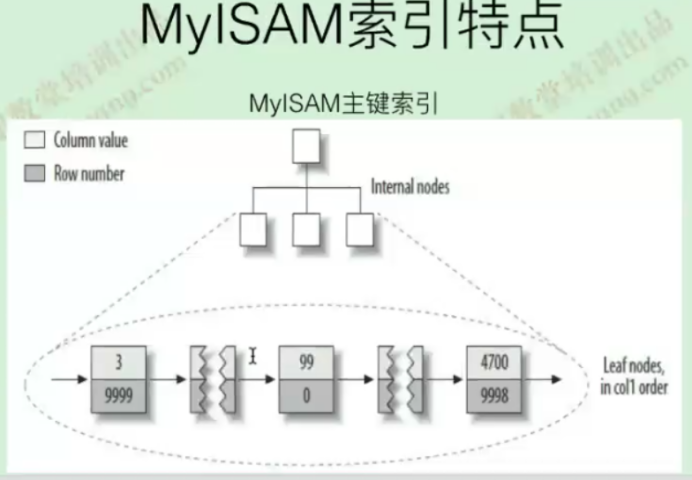
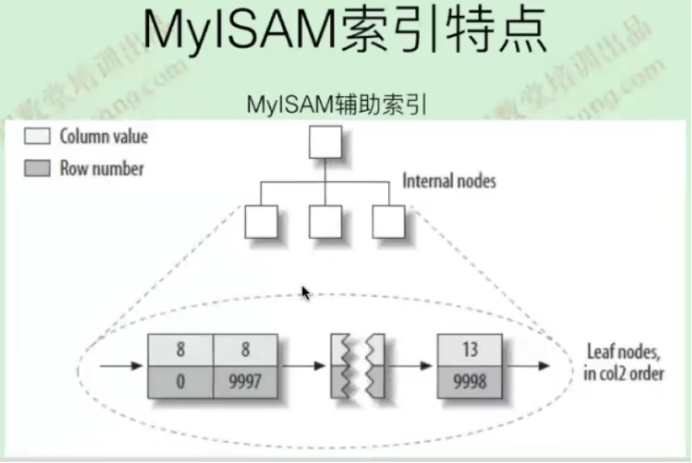
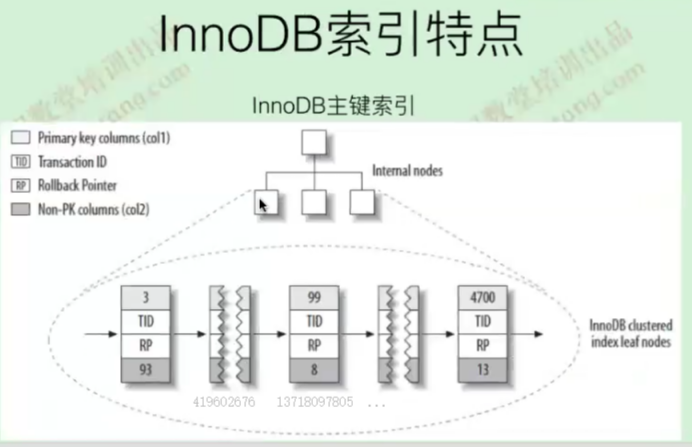
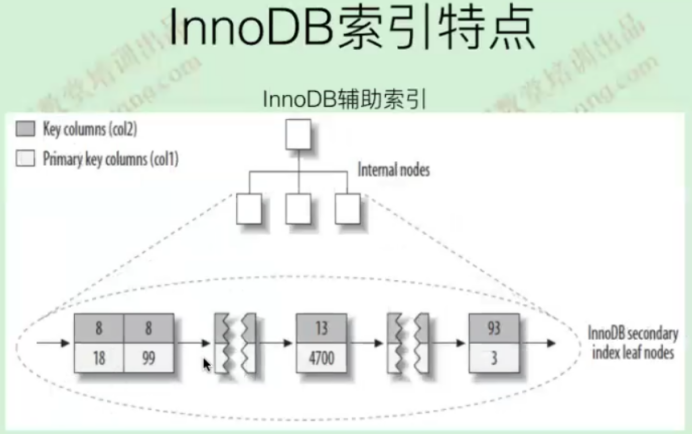
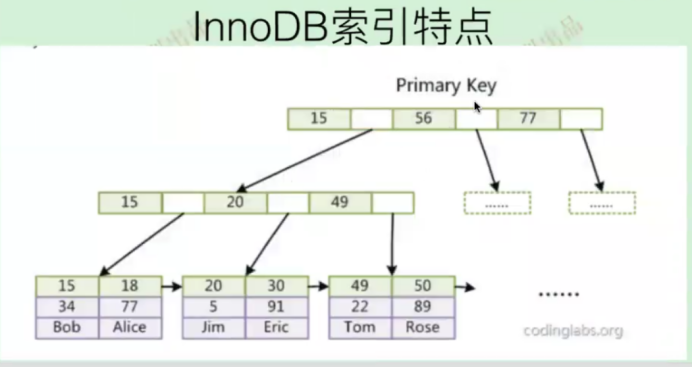

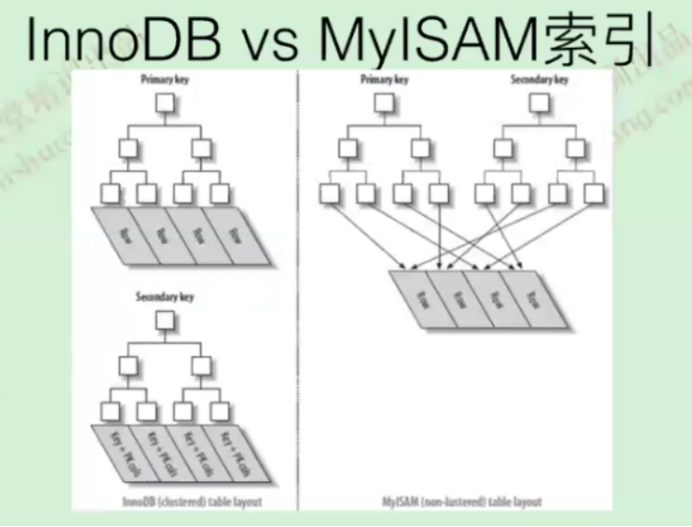
聚集索引
聚集索引是一种索引,该索引中键值的逻辑顺序决定了表数据行的物理顺序
每张表只能建一个聚集索引,除了TokuDB引擎
InnoDB中,聚集索引即表,表即聚集索引
MyISAM没有聚集索引的概念
create table t1(
a int(11) not null auto_increment,
b int(11) not null,
c int(11) not null,
d int(11) not null,
primary key (a),
key k2(c)
);
INDEX: name PRIMARY, FIELDS: a DB_TRX_ID DB_ROLL_PTR b c d
聚集索引优先选择列:
A.INT/BIGINT
B.数据连续(单调顺序)递增/自增
不建议的聚集索引:
A.修改频繁的列
B.新增数据太过离散随机
主键索引
InnoDB表一定有聚集索引
但是聚集索引不一定是主键
主键索引一定是聚集索引
主键索引是逻辑概念,聚集索引是物理概念
聚集索引里面包含db_trx_id,db_roll_ptr用来做mvcc
InnoDB的主键采用聚簇索引,二级索引不采用聚簇索引
<=5.6才支持innodb_table_monitor特性

主键由表中的一个或多个字段组成,它的值用于唯一地标识表中地某一条记录
在表引用中,主键在一个表中引用来自于另一个表中特定记录(外键foreign key应用)
保证数据的完整性
加快数据的操作速度
主键值不能重复,也不能包含NULL
主键选择建议:
A.对业务透明,无意义,免受业务变化的影响
B.很少修改和删除
C.最好是自增的
D.不要具有动态属性,例如随机值
InnoDB主键特点:
A.索引定义时,不管有无显示包含主键,实际都会存储主键值
B.在5.6.9后,优化器已能自动识别索引末尾的主键值(Index Extensions),在这之前则需要显示加上主键列才可以被识别:
where c1 = ? and pk = ?;
where c1 = ? order by pk;
InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置.
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
唯一索引(UNIQUE KEY)
不允许具有索引值相同的行,从而禁止重复的索引或键值
严格意义上讲,应该叫做唯一约束
在唯一约束上,和主键一样(以MyISAM引擎为代表)
其他不同的方面:
A.唯一索引允许有空值(NULL)
B.一个表只能有一个主键,但可以有多个唯一索引
C.InnoDB表中主键必须是聚集索引,但聚集索引可能不是主键
D.唯一索引约束可临时禁用,但主键不行
联合索引(Combined Indexes,Multiple-Column Indexes)
多列组成,所以也叫多列索引
适合WHERE条件中的多列组合
有时候,还可以用于避免回表(覆盖索引)
MySQL还不支持多列不同排序规则(MySQL8.0起支持)
联合索引建议:
A.WHERE条件中,经常同时出现的列放在放在联合索引中
B.把选择性(过滤性/基数)大的列放在联合索引的最左边
create table t1(
a int(11) not null auto_increment,
b int(11) not null,
c int(11) not null,
d int(11) not null,
primary key (a,b),
key k2(c,d,a),
key k3(d),
key k4(b,c)
);
TABLE: name t1, FIELDS: a b DB_TRX_ID DB_ROLL_PTR c d
INDEX: name k2, FIELDS: c d a b
INDEX: name k3, FIELDS: d a b
INDEX: name k4, FIELDS: b c a
覆盖索引
通过索引数据结构,即可直接返回数据,不需要回表
执行计划中,Extra列会显示关键字using index
回表:读取的列不在索引中,需要回到表找到整条记录取出相应的列
假设有这样的索引:key idx1(id,user,passwd)
覆盖索引都被用到
A.select id,user,passwd from t1 where id=?;
B.select id,user,passwd from t1 where id=? and user=?;
C.select id,user,passwd from t1 where id=? and user=? and passwd=?;
D.select id,user,passwd from t1 where passwd=? and id=?;
用到部分覆盖索引
E.select id,user from t1 where id=? order by passwd;
F.select id,user from t1 where id=? order by user;
倒序索引
create table t1(
id bigint(20) unsigned not null auto_increment,
u1 int(10) unsigned not null default '0',
u2 int(10) unsigned not null default '0',
u3 varchar(20) not null default '',
u4 varchar(35) not null default '',
primary key (id),
key u1(u1 desc,u2)
);
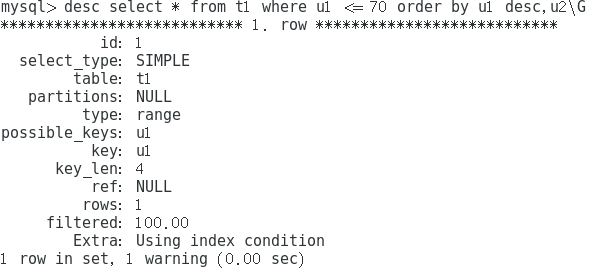
不可见索引
设置invisible
alter table t1 alter index u1 invisible;

前缀索引(prefix indexes)
部分索引的原因:
A.char/varchar太长全部做索引的话,效率太差,存在浪费
B.或者blob/text类型不能整列作为索引列,因此需要使用前缀索引
部分索引选择建议:
A.统计平均值
B.满足80%~90%覆盖度就够
缺点:
无法利用前缀索引完成排序
函数索引、表达式索引
8.0.13开始,支持函数索引、表达式索引
本质上是generated column
index skip scan
8.0.13开始,支持skip index scan
执行计划的Extra会显示Using index for skip scan
针对单表,不能是多表JOIN
SQL中不能有GROUP BY或DISTINCT
多列联合索引中,第一列的唯一值很少,且在WHERE条件中未被用到
索引并行读
从8.0.14开始,支持主键索引并行读
不支持辅助索引上的并行读
使用CHECK TABLE的速度更快
新增选项innodb_parallel_read_threads
innodb_parallel_read_threads=4 (默认),CHECK TABLE耗时减少20%
外键约束(FOREIGN KEY Constraints)
确保存储在外键表中的数据一致性,完整性
外键前提:本表列须与外键列类型相同(外键须是外表主键)
外键选择原则:
A.为关联字段创建外键
B.所有的键都必须唯一
C.避免使用复合键
D.外键总是关联唯一的键字段
全文检索
5.6以前,FULLTEXT只支持MyISAM引擎
5.6以后,也开始支持InnoDB引擎
5.7以前,中文支持很差
优先使用Shpinx/Lucene/Solr等实现中文检索
哈希索引
建立在哈希表的基础上,它只对使用了索引中的每个值的精确查找有用
对于每一行,存储引擎计算出了被索引的哈希码(Hash Code),它是一个较小的值,并且有可能和其他行的哈希码不同
把哈希码保存在索引中,并且保存了一个指向哈希表中每一行的指针
也叫散列索引

B+树索引 vs 哈希索引
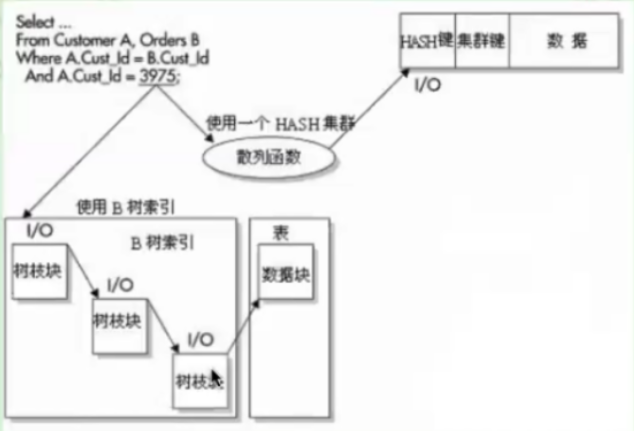
大量唯一值的等值查询,HASH索引效率通常比B+TREE高
HASH索引不支持模糊查找
HASH索引不支持联合索引中的最左匹配规则
HASH索引不支持排序
HASH索引不支持范围插叙
HASH索引只能显示应用于HEAP/MEMORY、NDB表
索引建议
一个索引里包含的列数,最好不要超过5个
一个表的索引树,也不要太多,一般也不要超过5个
联合索引中,把过滤性高(基数大)的列放在左边
需要函数索引?使用MySQL5.7的虚拟列,或升级到MySQL8.0
需要表达式索引?使用MySQL5.7的虚拟列,或升级到MySQL8.0
需要倒序索引?升级到MySQL8.0
需要临时禁用索引?升级到MySQL8.0
需要位图(bitmap)索引?抱歉,这个没有~
hash join?升级到8.18
使用like关键字时,前置%会导致索引失效
使用null值会被自动从索引中删除,索引一般不会建立在空值的列上
使用or关键字时,or左右字段如果存在一个没有索引,有索引字段也会失效
使用!=操作符时,将放弃使用索引。因为范围不确定,使用索引效率不高,会被引擎自动改为全表扫描
不要在索引字段进行运算
在使用复合索引时,最左前缀原则,查询时必须使用索引的第一个字段,否则索引失效。并且应尽量让字段顺序与索引顺序一致
避免隐式转换,定义的数据类型与传入的数据类型保持一致
索引使用建议
哪个情况下应该创建索引
A.经常检索的列
B.经常用于表连接的列
C.经常排序/分组的列
索引不使用建议
A.基数很低的列
B.更新频繁但检索不频繁的列
C.BLOB/TEXT等长内容列
D.很少用于检索的列
索引管理
创建/删除索引
1.alter table t add index idx(c1) using btree;
2.create index idx on t(c1) using btree;
3.create table时也可顺便创建索引
4.alter table t drop index idx;
5.drop index idx on t;
innodb目前底层还是不支持hash index的
使用show index from t;查看
冗余索引
根据最左匹配原则,一个索引是另一个索引的子集
可使用工具pt-duplicate-key-checker检查,schema_redundant_indexes
无用索引
几乎从未被使用过的索引
pt-index-usage检查低利用率索引,提供删除建议,schema_unused_indexes
InnoDB索引长度
索引最大长度767bytes
启用innodb_large_prefix,增加到3072bytes,只针对DYNAMIC、COMPRESSED格式管用
对于REDUNDANT、COMPACT格式,最大索引长度还是767bytes
MyISAM表索引最大长度是1000bytes
最大排序长度默认是1024(max_sort_length)
explain之key_len
正常的,等于索引列字节长度
字符串类型需要同时考虑字符集因素
若允许NULL,再+1
变长类型(varchar),再+2
案例
1.varchar(10)变长字段且允许NULL
10*(Character Set: utf8mb4=4,utf8=3,gbk=2,latin1=1) + 1(因为允许NULL) + 2(变长字段)
2.varchar(10)变长字段且不允许NULL
10*(Character Set: utf8mb4=4,utf8=3,gbk=2,latin1=1) + 2(变长字段)
3.char(10)固定字段且允许NULL
10*(Character Set: utf8mb4=4,utf8=3,gbk=2,latin1=1) + 1(因为允许NULL)
4.char(10)固定字段且不允许NULL
10*(Character Set: utf8mb4=4,utf8=3,gbk=2,latin1=1)
5.int not null : 4
6.int : 4 + 1 (因为允许NULL)
7.bigint : 8 + 1 (因为允许NULL)
key_len只计算利用索引完成数据过滤时的索引长度
不包括用于GROUP BY/ORDER BY的索引长度
即:如果ORDER BY也使用了索引,不会将其计算在key_len之内
例如,联合索引(c1,c2,c3),三个列都是int not null
where c1 = ? and c2 = ? order by c3;
这时候,key_len只会显示c1 + c2的长度(4 + 4 =8)
create table user (
id int unsigned not null auto_increment,
user varchar(30) not null default '',
passwd varchar(32) not null default '',
detail varchar(40) not null default '',
regdate timestamp not null default current_timestamp on update current_timestamp,
primary key(id),
key idx1(user,passwd)
) engine=InnoDB charset=UTF8MB4;
若有个SQL能完整用到IDX1索引,则key_len = ?
30 * 4 + 2 + 32 * 4 + 2 = 252
下面的SQL,key_len = ?
select ... where user = 'xxx' order by passwd limit 5;
30 * 4 + 2 = 122,不能计算order by的那部分
查看冗余索引
index k1(a,b,c)
index k2(a,b)
一般认为,k2是k1的冗余索引
但下面的SQL则只有k2才管用
where a = ? and b = ? and pk = ?;
where a = ? and b = ? order by pk;
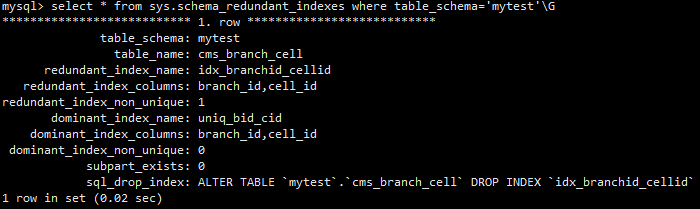
查看无用索引
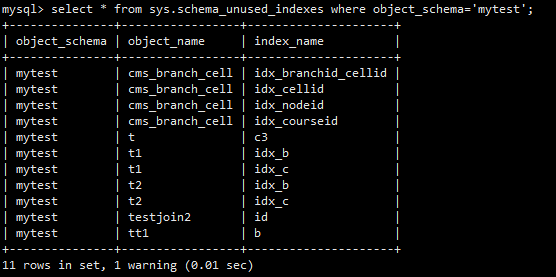
还要看索引的创建时间
使用索引
1.让MySQL自动选择
select ... from t where ...
2.自主建议索引
select ... from t use index(idx) where ...
3.强制(hint)索引
select ... from t force index(idx) where ...
4.甚至可以这样
select ... from t force index(idx1,idx2) where ...
select ... from t force index(idx1) force index for join(idx2) where ...
use/force/ignore index for join/order by/group by
查看每个索引利用率

当一个表从未被访问过时,从sys schema查询不到它的索引使用情况,这时候要看索引的创建时间
索引统计
表统计信息
show table status like 'tableName' \G
select * from I_S.tables;
mysql.innodb_table_stats;
索引统计信息
show index from table;
select * from I_S.statistics;
mysql.innodb_index_stats;
相关参数及变量
innodb_stats_auto_recalc 默认启用,当修改数据量>10%时,自动更新统计信息
innodb_stats_persistent 统计信息持久化存储,默认启用
innodb_stats_persistent_sample_pages 统计信息持久化存储时,每次采集20个page
innodb_stats_on_metadata 默认禁用,访问meta data时更新统计信息
innodb_stats_method 控制统计信息针对索引中NULL值的算法
innodb_stats_persistent = 0 统计信息不持久化,每次动态采集,存储在内存中,重启失效(需重新统计),不推荐
innodb_stats_transient_sample_pages 动态采集page,默认8个
每个表设定统计模式 create/alter table ... stats_persistent=1,stats_auto_recalc=1,stats_sample_pages=200;
索引如何提高SQL效率的
1.提高数据检索效率
2.提高聚合函数效率,sum()、avg()、count()
3.提高排序效率,order by asc/desc
4.有时可以避免回表
5.减少多表关联时扫描行数
6.唯一、外键索引还可以作为辅助约束
7.列定义为DEFAULT NULL时,NULL值也会有索引,存放在索引树的最前端部分,因此尽量不要定义允许NULL
索引怎么影响insert效率的
结论:有辅助索引时,纯数据加载耗时比无索引时多2%
索引为何不可用
1.通过索引扫描的记录数超过20%~30%,可能会变成全表扫描
2.联合索引中,第一个索引列使用范围查询(这时用到部分索引)
3.联合索引中,第一个查询条件不是最左索引列
4.模糊查询条件列最左以通配符%开始
5.HEAP表使用HASH索引时,使用范围检索或者ORDER BY
6.多表关联时,排序字段不属于驱动表,无法利用索引完成排序
7.两个独立索引,其中一个用于索引,一个用于排序(只能用到一个)
8.JOIN查询时,关联列数据类型(以及字符集)不一致也会导致索引不可用
类型隐式转换

字符串字段传入整性
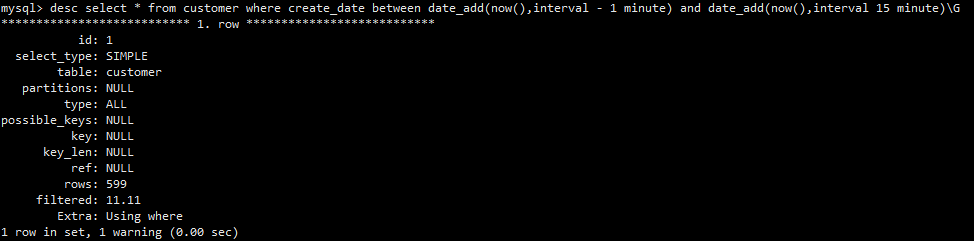
小于5.6版本字符串列存时间底层是用字符串形式存储的。5.6/5.7版本字符串列存时间底层是用整形存储的
join列类型不一致
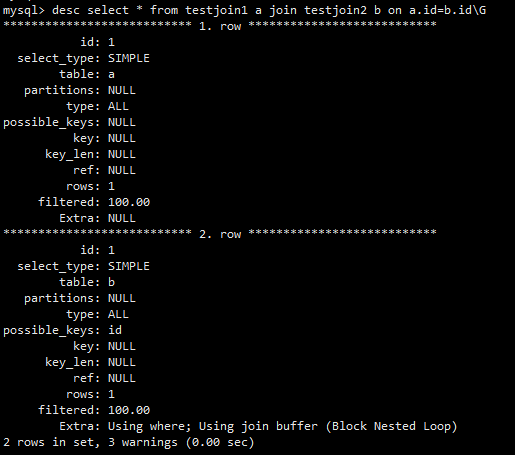
join列字符集/校验集不同
t1,utf8mb4 ,2,utf8
联合索引最左匹配
假设有联合索引idx1(a,b,c)
下面的SQL可完整用到索引
1.b = ? and c = ? and a = ?;
2.b = ? and a = ? and c = ?;
3.a = ? and b in (?,?) and c = ?;
4.a = ? and b = ? order by c;
5.a = ? order by b,c;
6.order by a,b,c;
而下面几个SQL则只能用到部分索引,或者可利用到ICP特性(5.6起)
1.b = ? and a = ?; -只用到(a,b)部分
2.a in (?,?) and b = ?; -只能用到(a,b)部分,同时有ICP
3.(a BETWEEN ? AND ?) and b = ?; -只用到(a,b)部分,同时有ICP
4.a = ? and b in (?,?); -只用到(a,b)部分,同时有ICP
5.a = ? and (b BETWEEN ? AND ?) and c = ?; -可用到(a,b,c)整个索引,同时有ICP
6.a = ? and c = ?; -只用到(a)部分索引,同时有ICP
7.a = ? and c >= ?; -只用到(a)部分索引,同时有ICP
8.a in (?,?,?) order by b,c; -只能用到(a)部分索引,且会有ICP和filesort
9.a > ? order by b; -只能用到(a)部分索引,且会有ICP和filesort
10.a > ? order by a; -只能用到(a)部分索引
ICP(index condition pushdown)是MySQL5.6的新特性,其机制会让索引的其他部分也参与过滤,减少引擎层和server层之间的数据传输和回表请求,通常情况下可大幅提升查询效率
下面的几个SQL完全用不到索引
1.select ... where b = ?;
2.select ... where b = ? and c = ?;
3.select ... where b = ? and c >= ?;
4.select ... order by b;
5.select ... order by b,a;
索引(gender,country)
country = 'USA' 是type = ALL
gender in ('F','M') and country = 'USA' 是type = range 同时还有ICP
索引(a,b)
a in (?,?) order by b; 是filesort
min/max优化

group by优化
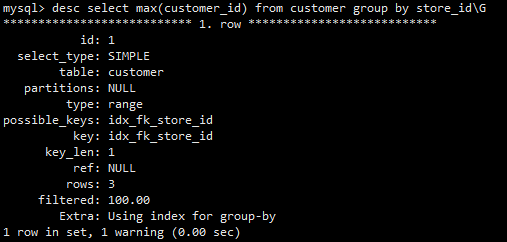
index merge
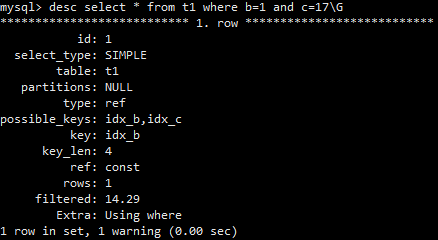
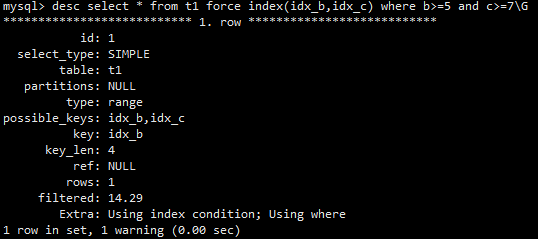
小表可以不建索引吗
看情况,通常最好要建索引
案例:
用mysqlslap对只有一万行记录的表进行简单压测,一种是对该表先排序后读取30条记录,另一种是对该表随机读取一行记录,分别对比有索引和没有索引的表现,结论:
1、排序后读取时,没索引时慢了约37倍时间。压测期间出现大量的Creating sort index状态
2、随机读取一行记录时,没索引时慢了约44倍时间。压测期间出现大量的Send data状态,有索引时,则更多的是出现Sending to client状态
3、不管是大表还是小表,需要时还是乖乖加上索引吧,否则有可能它就是瓶颈
using filesort/temporary
filesort
sort的item仅包括排序列,待排序完成后,根据rowid查询所需要的列,<4.1采用的方式
sort的item包括全部列,排序完成后,无需再回表,4.1~5.6新增
第二种可以明显减少额外的I/O,但需要更多内存
更紧凑格式数据排序模式,5.7.3后新增的优化模式
order by + limit 时进一步优化,使用Priority queue机制(用堆结构保存结果),只保留top n的数据满足limit条件
filesort仅用于单表排序,若多表join时有排序,则走tempory,再基于temp table进行filesort
适当加大read_rnd_buffer_size和sort buffer size
temporary
外部临时表,CREATE TEMPORARY TABLE,只对当前session可见,关闭连接后删除
内部临时表,SQL运行时using temporary
先创建MEMORY表(8.0以前),当数据超过max_heap_table_size时,自动转换成disk temp table
5.7起新增internal_tmp_disk_storage_engine选项,可设置InnoDB,以前默认是MyISAM。但该选项8.0.16后消失,因为只能使用InnoDB引擎
8.0后,temp table默认引擎改成TempTable,意欲取代MEMORY引擎,新增选项internal_tmp_mem_storage_engine(TempTable)、temptable_max_ram(1GB)
几种需要temporary的常见情况
1.表JOIN时使用BNL/BKA
2.表JOIN时,GROUP BY的列不属于驱动表
3.GROUP BY和ORDER BY的列不同
4.UNION
5.多表关联查询后update
6.聚合查询中包含distinct、group_concat
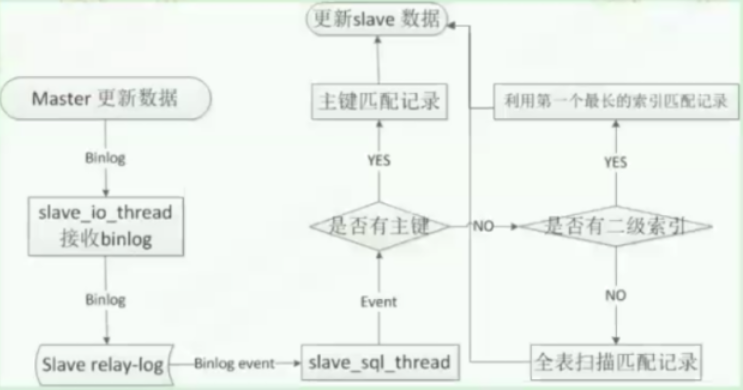
表没有主键会怎样
字段nullable
索引查找、统计、值比较,会更加复杂
在B+树里,所有null值放在最左边,增加搜索代价
主从复制环境中,表中有UN(含NULL),也有PK及其他普通SK,有个删除的SQL,在主库执行时,选择普通SK效率更高,但是在从库时,却选择了含NULL的UK,效率极低,造成主从延迟严重
原因分析:
binlog_format = row
slave执行sql时,索引选择次序如下:
PK
UK without NULL
other keys
table_scan
解决办法:
修改不允许为NULL
只在从库删除UK,或者重建一个效率更高的UK
将该UK设置为invisible index
索引实践
表t1的DDL如下:
CREATE TABLE t1 (
c1 int not null,
c2 int default null,
c3 int unsigned not null,
xx int default null,
c4 int unsigned not null default 0,
dt timestamp not null default current_timestamp on update current_timestamp,
primary key (c1)
);
下面的查询需求,怎么建索引
select * from t1 where c2 = 200 order by c1;
#1、只有主键索引时
mysql> desc select * from t1 where c2 = 200 order by c1;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | PRIMARY | 4 | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
#2、添加c2列上的索引
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t1 | NULL | ref | c2 | c2 | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
#3、需要对c2列进行group by
mysql> desc select c2,count(*) as c from t1 group by c2;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | index | c2 | c2 | 5 | NULL | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
#4、对c2列group by之后,又要求count(),而且还要排序,需要临时表+额外排序
mysql> desc select c2,count(*) as s from t1 group by c2 order by s desc;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------+
| 1 | SIMPLE | t1 | NULL | index | c2 | c2 | 5 | NULL | 1 | 100.00 | Using index; Using temporary; Using filesort |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------+
#5、既有where条件,又有group by
mysql> desc select c2,c3 from t1 where c2 = 100 group by c3;
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-----------------+
| 1 | SIMPLE | t1 | NULL | ref | c2 | c2 | 5 | const | 1 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-----------------+
#添加新索引后,可以使用新索引,消除了临时表
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ref | c2,c2_2 | c2_2 | 5 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
使用索引
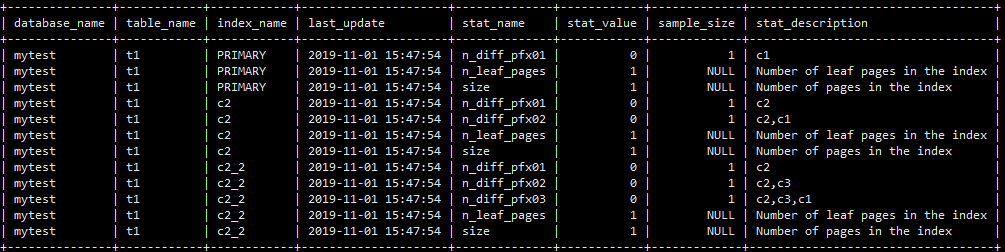
mysql> show index from t1;

information_schema库
mysql> select * from statistics where index_schema='mytest' and table_name='t1';

mysql> select * from innodb_index_stats where database_name='mytest' and table_name='t1';
MySQL索引
B+树索引结构是主流,哈希索引适用场景不多
不支持bitmap索引,低基数列不适合创建独立索引
字符串、大对象列,创建部分索引
InnoDB表创建索引时,要额外考虑聚集索引的特性(Index Extensions)
适当利用覆盖索引特性提高SQL效率
利用MySQL5.7t特性,找出低效&无用索引
发现执行计划不正确时,优先考虑统计信息因素
索引不可用:非最左匹配、30%原则、非驱动表字段排序、完全模糊查询、隐式类型转换
利用key_len判断索引利用率

