

分库分表
分库分表
拆分的目的是什么?
拆库,还是拆表?两者结合?
拆库方便进行扩容
其规则设计的好,表也可以移动
拆成多少合适
单实例最多1千张表
单表按1千万~1亿条数据规划,10G左右
对于大字段blob,text字段建议拆分并压缩,用主键关联(查询)
每个表必须有主键,主键采用自增int/bigint
单库200~400张表
Hash拆分
拆分成10库10表
dbRule: db + (id/10 % 10)
tbRule: t + (id % 10)
Range拆分
id < 1千万在DB0
1千万 <= id <2千万 DB1
按日期拆分
create_time按月一个表
按业务垂直拆分
用户基本资料库
好友关系库
等等
数据库拆分后续
拆分策略最好一开始就想清楚,不要在实施过程中多变
优先采用可控性强的策略,也就是更方便后续扩展的策略
不单纯追求拆分后的均衡离散性
拆分之后,需要选择一个合适的proxy方案
不一定非要proxy,单整体改造代价一定不能太高
proxy方案选择更适合自己场景的
数据分级决定缓存策略不同
第一级:订单数据和流水数据,这两块数据对实时性和精确性要求很高,所以不添加任何缓存,读写操作将直接操作数据库
第二级:用户相关数据,这些数据和用户相关,具有读多写少的特征,所以我们适用redis进行缓存
第三级:配置信息,这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,可以使用本地内存进行缓存
架构方案关键点
如何保证多节点的写入可用性
keepalived+双主,但只写一个节点
PXC,多库多表并行写入
MHA,一主多从,或者双主多从
大杀器,MGR
如何提高读可用性
一主一从,从故障时切换到主
一主多从,多从可做高可用,或者根据情况切到主
双主多从,同上
写压力分摊
垂直拆分
水平拆分
混合方案
读压力分摊
多从
nosql/cache
并且采用多级分层方案
大数据量,并且进行分库分表后,不建议的SQL
复杂连接查询
跨库、跨表查询
分布式事务
子查询
涉及到跨库跨表查询时,通常需要好的中间层来解决
这个中间层大多靠自主开发,很少有现成的通用方案
跨表JOIN代价较高时,甚至可以考虑反范式,把多列存放在一个冗余表中,更方便查询
如何应对瞬间暴增的业务压力
快速响应,但延迟服务
前端利用CDN、缓存、静态内容抗住第一道访问
前端页面/APP端/转发层,增加刷新频率控制
动态请求需要有流控
业务隔离
区分不同业务所在资源池
重点业务,重点保障
弹性资源池(云)
秒杀业务
面临问题:高并发、超卖
前端提前准备措施:静态化、扩容、限流、服务降级机制
后端:限制MySQL的并发线程(并启用thread pool)、订单提交时再次判断,是否还有库存,可以直接使用AliSQL分支版本(应对秒杀场景特别有效)
提前把商品分摊到多个Redis实例中,根据用户ID哈希分配到各实例
Redis中保存2个队列,一个被秒的,一个待秒的
还有个队列保存已经参加过秒杀的用户列表
秒杀成功后,被秒队列+1,待秒队列-1,加入已秒用户列表
读取已秒队列及已秒用户列表,更新到MySQL中
重点:入口请求有序排队避免蜂拥,合并写请求减小写压力
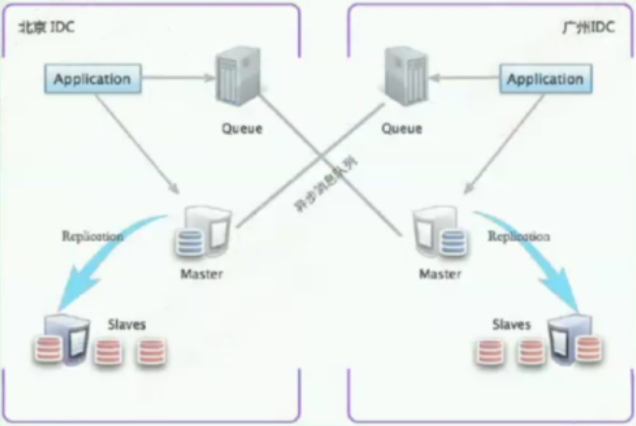
互联网常用高可用架构方案
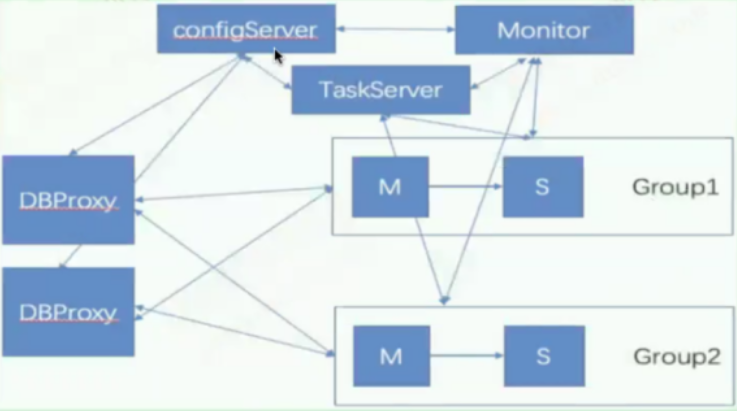
架构案例
NOSQL、NEWSQL对MySQL的影响
无论NOSQL还是NEWSQL,都不能很好支持事务原子性
NOSQL更多的是cache作用
简单的KV数据,可以用innodb memcached plugin解决
复杂的文档数据,可以用JSON数据类型解决
NOSQL由于弱关系约束,后期反倒可能是灾难
NEWSQL主要解决数据分布式存储
真正需要存储海量数据时,更多的是考虑用大数据解决方案
数据库安全
防止SQL注入
SQLmap
BSQL Hacker
Havij
Safe3 SQL Injector
防止长时间运行的SQL
及时干掉
启用timeout

