
SQL疑难杂症【4 】大量数据查询的时候避免子查询
前几天发现系统变得很慢,在Profiler里面发现有的SQL执行了几十秒才返回结果,当时的SQL如下:

可以看得出来,在652行用了子查询,恰巧目标表(QS_WIP)中的记录数为100000000+,通过如下SQL可以得到:
SELECT ROWS FROM SYSINDEXES WHERE ID=OBJECT_ID('QS_WIP') AND INDID <2
大量的数据导致子查询的效率非常慢,应用系统一度提示"time out",经过优化,改为如下写法,执行效率明显提升:
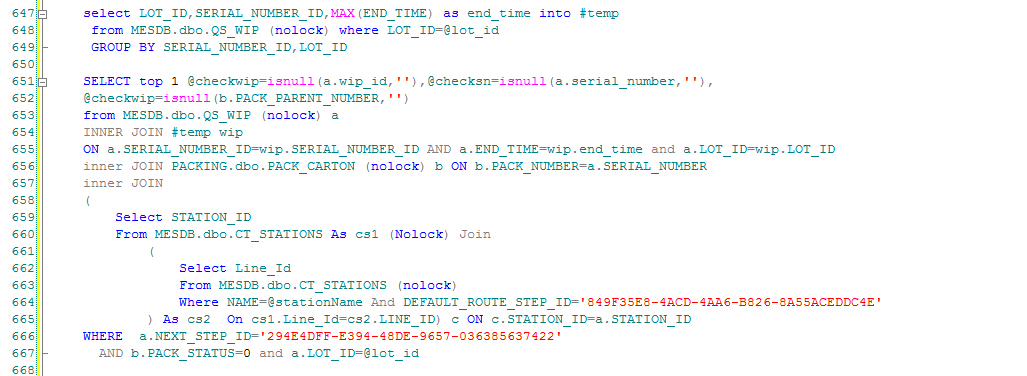
先将子查询里面的内容提取出来作为一个临时表,再次join的时候就快了。
作者:Allen Chen无影
邮箱:allen0717@163.com 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号