InfiniBand 与Intel Omni-Path Architecture
Intel Omni-Path Architecture (OPA) 是一种与InfiniBand相似的网络架构
可以用来避免以下PCI总线一些缺陷:
1、由于采用了基于总线的共享传输模式,在PCI总线上不可能同时传送两组以上的数据,当一个PCI设备占用总线时,其他设备只能等待;
2、随着总线频率从33MHz提高到66MHz,甚至133MHz(PCI-X),信号线之间的相互干扰变得越来越严重,在一块主板上布设多条总线的难度也就越来越大;
3、由于PCI设备采用了内存映射I/O地址的方式建立与内存的联系,热添加PCI设备变成了一件非常困难的工作。目前的做法是在内存中为每一个PCI设备划出一块50M到100M的区域,这段空间用户是不能使用的,因此如果一块主板上支持的热插拔PCI接口越多,用户损失的内存就越多;
4、PCI的总线上虽然有buffer作为数据的缓冲区,但是它不具备纠错的功能,如果在传输的过程中发生了数据丢失或损坏的情况,控制器只能触发一个NMI中断通知操作系统在PCI总线上发生了错误;
首先来看Infiniband的协议层次与网络结构
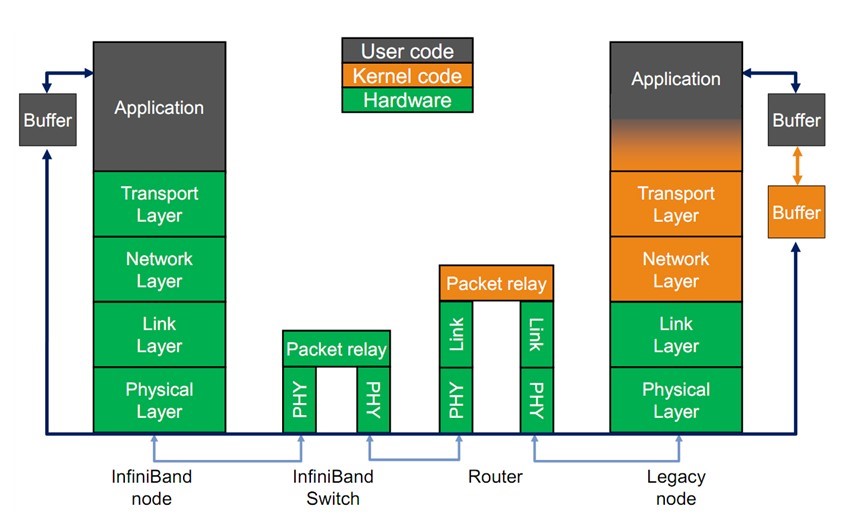
Infiniband的协议采用分层结构,各个层次之间相互独立,下层为上层提供服务。其中,物理层定义了在线路上如何将比特信号组 成符号,然后再组成帧、 数据符号以及包之间的数据填 充等,详细说明了构建有效包的信令协议等;链路层定义了数据包的格式以及数据包操作的协议,如流控、 路由选择、 编码、解码等;网络层通过在数据包上添加一个40字节的全局的路由报头(Global Route Header,GRH)来进行路由的选择,对数据进行转发。在转发的过程中,路由 器仅仅进行可变的CRC校验,这样就保证了端到端的数据传输的完整性;传输层再将数据包传送到某个指定 的队列偶(QueuePair,QP)中,并指示QP如何处理该数据 包以及当信息的数据净核部分大于通道的最大传输单 元MTU时,对数据进行分段和重组。
Omni-Path Network Layers
Layer 1 – Physical Layer
Leverages existing Ethernet and InfiniBand PHY standards
Layer 1.5 – Link Transfer Protocol
Provides reliable delivery of Layer 2 packets, flow control and link control across
a single link
Layer 2 – Data Link Layer
Provides fabric addressing, switching, resource allocation and partitioning
support
Layers 4-7 – Transport to Application Layers
Provide interfaces between software libraries and HFIs
Leverages Open Fabrics as the fundamental software infrastructure
网络拓扑结构

Infiniband的网络拓扑结构如图,其组成单元主要分为四类:
(1)HCA(Host Channel Adapter),它是连接内存控制器和TCA的桥梁;
(2)TCA(Target Channel Adapter),它将I/O设备(例如网卡、SCSI控制器)的数字信号打包发送给HCA;
(3)Infiniband link,它是连接HCA和TCA的光纤,InfiniBand架构允许硬件厂家以1条、4条、12条光纤3种方式连结TCA和HCA;
(4)交换机和路由器;
无论是HCA还是TCA,其实质都是一个主机适配器,它是一个具备一定保护功能的可编程DMA(Direct Memory Access,直接内存存取 )引擎
OPA组件
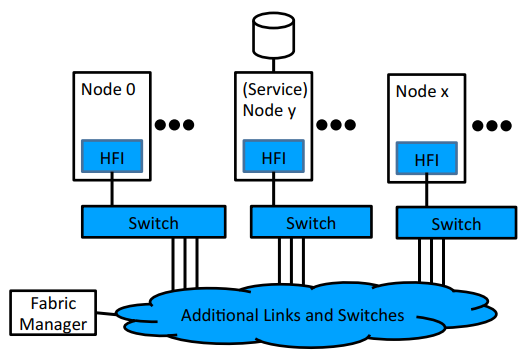
Omni-Path主要有以下3部分组件:
HFI – Host Fabric Interface 提供主机,服务和管理节点的光纤连接
Switches 提供大规模的节点之间的任意拓扑连接
Fabric Manager 提供集中化的对光纤资源的provisioning 和监控
相比InfiniBand ,Intel Omni-Path Architecture 架构设计目标特性:
1. 通过CPU/Fabric integration 来提高cost, power, and density
2. Host主机端的优化实现来高速的MPI消息,低延迟的高扩展性的架构
3. Enhanced Fabric Architecture 来提供超低的端到端延迟,高效的纠错和增强的QoS,并且超高的扩展性
RDMA

RDMA技术,最大的突破是将网络层和传输层放到了硬件中,服务器的网卡上来实现,数据报文进入网卡后,在网卡硬件上就完成四层解析,直接上送到应用层软件,四层解析CPU无需干预
RDMA技术的全称叫做Remote Direct Memory Access,即远程直接数据存取,就是为解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网卡将数据直接传入服务器的存储区,不对操作系统造成任何影响,消除了外部存储器复制和文本交换操作,解放内存带宽和CPU资源。当一个应用执行RDMA读或写请求时,不执行任何数据复制。
在不需要任何内核内存参与的条件下,RDMA请求从运行在用户空间中的应用中发送到本地网卡,然后经过网络传送到远程服务器网卡。RDMA最早专属于Infiniband架构,随着在网络融合大趋势下出现了RoCE(RDMA over Converged Ethernet)和iWARP(RDMA over TCP/IP) ,这使高速、超低延时、极低CPU使用率的RDMA得以部署在目前使用最广泛的数据中心网络上。
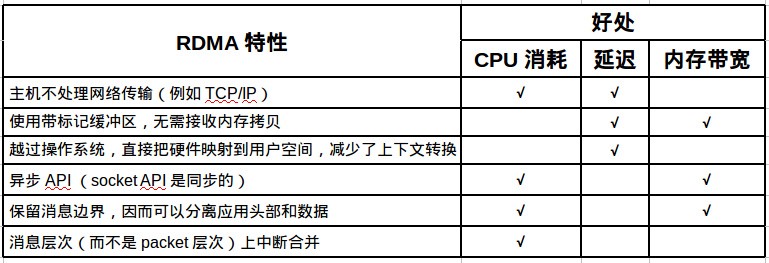
具体来说, RDMA 技术特性带来的好处如下图所示:
NVMe 设备延迟很低,这就要求网络延迟也必须很低, RDMA 正好满足这一点。
以一个 NVMe 写操作为例。 NVMe 主机驱动把写命令及数据(从 NVMe 提交队列取出一项)封装一个与底层传输无关的命令胶囊(capsule);胶囊被放到主机 RDMA 网卡的发送队列中,由 RDMA_SEND 发送出去;目标主机的 RDMA 网卡在接收队列中收到这个胶囊,解除封装,把 NVMe 命令及数据放到目标主机的内存中;目标主机处理 NVMe 命令及数据;完成后,目标主机封装一个 NVMe 命令完成项,由 RDMA 传输到源主机。
三、两种基于以太网的 RDMA 协议
第一种:以太网->IP->UDP->RoCE (RDMA over Converged Ethernet) v2
第二种:以太网->IP->TCP(去掉 TCP/IP 流量控制和管理)->iWARP
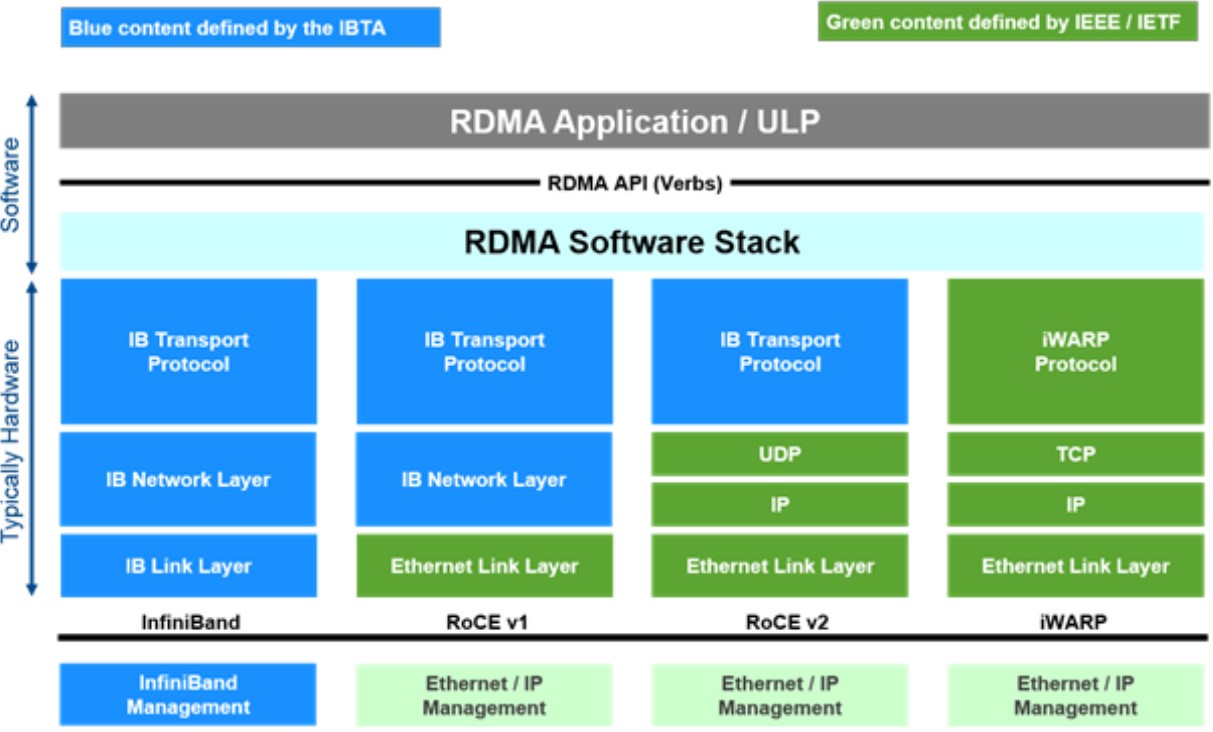
InfiniBand 与RoCE and iWARP同列
InfiniBand采用Cut-Through转发模式,减少转发时延,基于Credit流控机制,保证无丢包。RoCE性能与IB网络相当,DCB特性保证无丢包,需要网络支持DCB特性,但时延比IB交换机时延稍高一些。iWARP则是利用成熟IP网络,继承RDMA优点,但如果采用传统IP网络丢包对性能影响大。

iWARP技术的主要问题在于稳定性,一旦网络有丢包,性能会奇差,而iWARP就是基于以太网协议实现的,以太网协议不可能没有丢包,这使得iWARP技术没有了应用空间。
IB性能最好,RoCE则用得最多,RoCE是伴随着RDMA技术才普及起来的,相比于IB技术,RoCE技术仍基于以太网实现,但是增加了丢包控制机制,确保以太网处于一个无丢包的状态,虽然延时比IB差些,但部署成本要低得多。
解析RDMA over TCP(iWARP)协议栈和工作原理
具备RNIC(RDMA-aware network interface controller)网卡的设备,不论是目标设备还是源设备的主机处理器都不会涉及到数据传输操作,RNIC网卡负责产生RDMA数据包和接收输入的RDMA数据包,从而消除传统操作中多余的内存复制操作。
RDMA协议提供以下4种数据传输操作(RDMA Send操作、RDMA Write操作、RDMA Read操作和Terminate操作),除了RDMA读操作不会产生RDMA消息,其他操作都会产生一条RDMA消息
以太网凭借其低投入、后向兼容、易升级、低运营成本优势在目前网络互连领域内占据统治地位,目前主流以太网速率是100 Mb/s和1000 Mb/s,下一代以太网速率将会升级到10Gb/s。将RDMA特性增加到以太网中,将会降低主机处理器利用率,增加以太网升级到10 Gb/s的优点,消除由于升级到10 Gb/s而引入巨大开销的弊端,允许数据中心在不影响整体性能的前提下拓展机构,为未来扩展需求提供足够的灵活性。
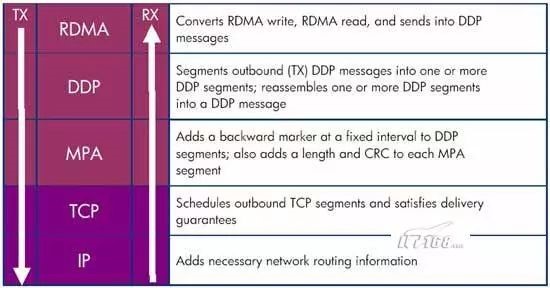
图4.2 RDMA over TCP (Ethernet)协议栈
图4.2是RDMA over TCP (Ethernet)的协议栈,最上面三层构成iWARP协议族,用来保证高速网络的互操作性。
RDMA层协议负责根据RDMA写操作、RDMA读操作转换成RDMA消息,并将RDMA消息传向Direct Data Placement (DDP)层。
DDP层协议负责将过长的RDMA消息分段封装成DDP数据包继续向下转发到Marker-based, Protocol-data-unit-Aligned (MPA)层。
MPA层在DDP数据段的固定间隔位置增加一个后向标志、长度以及CRC校验数据,构成MPA数据段。
TCP层负责对TCP数据段进行调度,确保发包能够顺利到达目标位置
IP层则在数据包中增加必要的网络路由数据信息。
RDMA应用和RNIC(RDMA-aware Network Interface Controller)之间的传输接口层(Software Transport Interface)被称为Verbs或RDMA API,RDMA API (Verbs)主要有两种Verbs:
· 内存Verbs(Memory Verbs),也叫One-SidedRDMA。包括RDMA Reads, RDMA Writes, RDMA Atomic。这种模式下的RDMA访问完全不需要远端机的任何确认。
. 消息Verbs(Messaging Verbs),也叫Two-SidedRDMA。包括RDMA Send, RDMA Receive。这种模式下的RDMA访问需要远端机CPU的参与。
IB、以太网RoCE、以太网iWARP这三种RDMA技术使用统一的API
上层协议
InfiniBand为不同类型的用户提供了不同的上层协议,并为某些管理功能定义了消息和协议。InfiniBand主要支持SDP、SRP、iSER、RDS、IPoIB和uDAPL等上层协议。
- SDP(SocketsDirect Protocol)是InfiniBand Trade Association (IBTA)制定的基于infiniband的一种协议,它允许用户已有的使用TCP/IP协议的程序运行在高速的infiniband之上。
- SRP(SCSIRDMA Protocol)是InfiniBand中的一种通信协议,在InfiniBand中将SCSI命令进行打包,允许SCSI命令通过RDMA(远程直接内存访问)在不同的系统之间进行通信,实现存储设备共享和RDMA通信服务。
- iSER(iSCSIRDMA Protocol)类似于SRP(SCSI RDMA protocol)协议,是IB SAN的一种协议 ,其主要作用是把iSCSI协议的命令和数据通过RDMA的方式跑到例如Infiniband这种网络上,作为iSCSI RDMA的存储协议iSER已被IETF所标准化。
- RDS(ReliableDatagram Sockets)协议与UDP 类似,设计用于在Infiniband 上使用套接字来发送和接收数据。实际是由Oracle公司研发的运行在infiniband之上,直接基于IPC的协议。
- IPoIB(IP-over-IB)是为了实现INFINIBAND网络与TCP/IP网络兼容而制定的协议,基于TCP/IP协议,对于用户应用程序是透明的,并且可以提供更大的带宽,也就是原先使用TCP/IP协议栈的应用不需要任何修改就能使用IPoIB。
- uDAPL(UserDirect Access Programming Library)用户直接访问编程库是标准的API,通过远程直接内存访问 RDMA功能的互连(如InfiniBand)来提高数据中心应用程序数据消息传送性能、伸缩性和可靠性。
其中IPoIB
The role of IPoIB is to provide an IP network emulation layer on top of InfiniBand RDMA networks.
Because both iWARP and RoCE/IBoE networks are actually IP networks with RDMA layered on top of their IP link layer, they have no need of IPoIB. As a result, the kernel will refuse to create any IPoIB devices on top of iWARP or RoCE/IBoE RDMA devices.
IPoIB Limitations
IPoIB solves many problems for us. However, compared to a standard Ethernet network interface, it has some limitations:
- IPoIB supports IP-based application only (since the Ethernet header isn't encapsulated).
- SM/SA must always be available in order for IPoIB to function.
- The MAC address of an IPoIB network interface is 20 bytes.
- The MAC address of the network interface can't be controlled by the user.
- The MAC address of the IPoIB network interface may change in consecutive loading of the IPoIB module and it isn't persistent (i.e. a constant attribute of the interface).
- Configuring VLANs in an IPoIB network interface requires awareness of the SM to the corresponding P_Keys.
Non-standard interface for managing VLANs.
参考:
http://www.rdmamojo.com/2015/02/16/ip-infiniband-ipoib-architecture/
http://www.rdmamojo.com/2015/04/21/working-with-ipoib/
https://weibo.com/p/1001603936363903889917


 浙公网安备 33010602011771号
浙公网安备 33010602011771号