
小师妹拿来某公司的一道笔试题,要求指出下列C++代码的问题:
2 array.push_back(1);
3 array.push_back(2);
4 array.push_back(3);
5 for(vector<int>::size_type i=array.size()-1; i>=0; --i ) // 反向遍历
6 cout << array[i] << endl;
如果不仔细,很容易发现不了问题。但事实上题目不难,只要注意到,作为专指下标的类型size_type,STL规定它是unsigned int,所以循环条件i>=0总是为真。
比这个答案更有意思的是不同版本的STL在执行这段程序时的不同反应。
STLport会忠实执行死循环,一发不可收拾地输出大量无意义数字,然后崩溃。而PJ STL会在输出3、2、1后立刻报错:
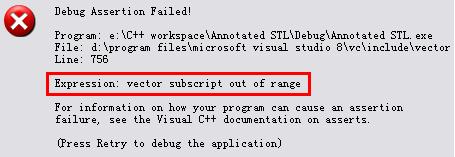
换言之,STLport不检查array的下标,而PJ STL检查。类似的差异可以说是无处不在。例如对之前提过的list::splice函数(回忆一下,它的声明是void splice(iterator position, list& x, iterator i),功能是把i所指的元素插入到position的前面)和如下代码:
2 w.splice(x.begin(), y, z.begin());
STLport会忽略y,将z的第一个元素插入到x的头部,而这一切却是由于调用了w的成员函数!程序的世界几乎因为STLport的不作为而变得疯狂。但是,当使用PJ STL时,同样的代码会得到一个如上图那样的错误提示,说“list splice iterator outside range”。
提升到一个高度上来讲,这个差异是设计思路的差异,即,STLport相信用户的输入总是正确的,而PJ STL则宁愿对此有所怀疑。
事实上呢?事实上我觉得假如我要设计一套软件,我绝不会放任用户拿一堆莫名其妙的输入折腾出一堆莫名其妙的结果然后再莫名其妙地转过头来诿过于我。但采取PJ STL的设计方法(我想应该属于defensive programming范畴)有时候也是累人的:也许真正的功能代码就几行,却要为各种可能出现的输入错误花费数十行进行处理,而且这还是发生在可以很幸运地预知全部可能错误的情况下。
“Design by Contrast (DbC)”倒是一种值得考虑的方式,它把用户和程序各自的权利义务用一纸契约规定下来:倘若用户的输入符合前置约束P,那么程序的输出符合后置约束Q。编译器将负责监管契约的履行。
Eiffel从机制上支持DbC。下面的简单例子(也许太过简单……)展示了Eiffel的DbC设计方式(require-do-ensure)。如果make中调用getInverse的参数设成0,那么编译器会指出该参数违背了第12行的契约。
2 INVERSE
3
4 create
5 make
6
7 feature -- Initialization
8 inverse: REAL
9
10 getInverse(number: REAL) is
11 require
12 number /= 0
13 do
14 inverse := 1 / number
15 ensure
16 inverse * number - 1 <= 0.001
17 inverse * number - 1 >= -0.001
18 end
19
20 display is
21 do
22 io.put_double (inverse)
23 end
24
25 make is
26 do
27 getInverse(3)
28 display
29 end
30
31 end -- class INVERSE
