剖析XSS
2018/01/14 建立提纲
2018/01/15 更新了1,2两部分的部分内容
2018/01/23 调整了顺序,编写了内容
2018/02/02 完成了XSS Vector一章的编写以及浏览器解析的部分内容
2018/02/14 基本完成浏览器解析一章节
2018/02/22 基本完成
2018/02/28 更新了目录
前言:
到今天为止,终于基本算是写完了,进度还是有点缓慢的。整篇内容大部分讲的都是一些基础的东西以及一些自己的方法论。我还在好几个章节,
挖了很深的坑,暂时没有填,也许无限期延迟,就不填了。
全文我都是边敲好word复制的,本人语文水平实在是不怎么样,语句不通有歧义等还望谅解,如果有空,我会自己再整理一下。
目录
一、 XSS
1. 原理
2. 三类XSS的区别
二、 XSS Vector 分析
1. 执行脚本的条件
2. Vector 分析
2.1 整体结构
2.2 Payload样例
3. Vector构造
3.1 输出位置在标签块内文本
3.2 输出位置在属性值
3.3 其他
三、浏览器解析
1. 例子分析
2. 组件介绍
3. 解析过程
3.1 字节流解码
3.2 标记化
4. 容错机制
四、防御机制
1. 数据流
2. 防御机制
2.1 应用层面
2.2 外部网络层面
2.3 内部网络层面
2.4 代码层面
五、绕过姿势
1. 绕过分析
2. 构造绕过的必要信息
六、测试/利用之道
七、参考
一、 XSS
提纲:
这一部分大概就是说一说什么是XSS漏洞吧
1. 原理
一般而言,把XSS漏洞分成三类反射型XSS漏洞、存储型XSS漏洞、DOM型XSS漏洞。从根本来说,都是一致的——就是在处理数据时,部分数据跨越了数据的边界被解析了代码。
数据,就是允许用户提交的数据。代码,在这个场景下含义比较多,一部分是HTML(超文本标记语言),另一部分是脚本(包括javascript和vbscript等)。脚本其实也可以当成只有一个javascript。因为vbscript用的人现在比较少,actionscript呢,随着flash的不流行,应该也会比较少(个人感觉)。另外呢,单单HTML的各个标签功能毕竟还是有限的,在考虑利用时,还是会转回到执行脚本。
大部分的注入漏洞、溢出漏洞都是这个道理,数据变成数据和代码两个部分。
数据à数据 + 代码
分析一个例子,了解一下:
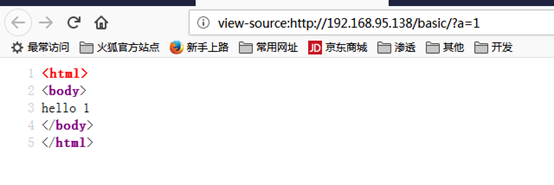
输入 1<svg/onload=alert('1')>,浏览器收到的html文本如下:
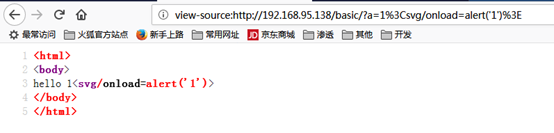
浏览器解析这个html文本时触发了svg标签的onload事件会执行alert('1')函数,如下:
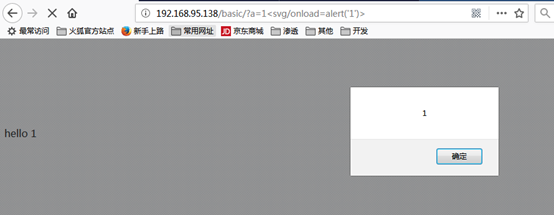
具体怎么构造,怎么让数据变成代码去执行,在后面XSS Vector分析中会说明。
2. 三类XSS的区别
三类XSS漏洞,除了DOM型的XSS,另外两类其实没什么多大的区别,不同的只有 payload在哪,导致利用的方式不同,甚至构造的思路的略微不同。DOM型的XSS,则是数据被带入到了javascript的执行过程中,在操作DOM树(一般来说是的)时,数据中嵌入的脚本被执行了。反射/存储XSS在测试上稍微简单一点,只需要看返回的HTML文本内容,而DOM则复杂一点,不可避免的需要去调试前端的JS代码。
二、 XSS Vector 分析
提纲:
这一部分主要是介绍一下XSS Vector是怎么起作用、Vector各个部分组成以及构造的思路。
常见的几类payload都会有, <svg/onload=> “ onfocus= “;alert();a=” #xxxxxx ( Flash XSS 这一块没怎么接触过,而且现在flash基本上越来越少见了,但是如果有空会补上
1. 执行脚本的条件
在谈如何能执行脚本之前不可避免的需要先谈谈客户端的浏览器是什么。涉及到这就很复杂了。不过至少可以在相应的环境下进行模拟,来测试XSS Vector 是不是能起作用。
另外一个方面就是哪些地方能执行脚本。目前来说,通用的只有两个地方——script标签和标签事件(若有其他地方,欢迎交流),之后的内容也只针对这两块。虽然在iframe/img等标签的src或者data属性中利用javascript伪协议执行脚本在老版浏览器例如IE6中是可行的,但是在目前的火狐和chrome中都是无法执行脚本的。(补充说明: iframe的src可以在执行javascript,而且依然有许多标签支持采用src和data的属性来执行javascript,下文,我也尽力说明一下)
2. Vector 分析
2.1 整体结构
一个XSS Vector撇开用于闭合其他的标签的前置和防止页面显示错误用的后置,中间的payload部分结构基本上就是下面这个图:

没错,就是一个标签的格式。其中标签名为不区分大小写的字母数字,分隔符为0x09, 0x0A, 0x0C, 0x0D, 0x20, 0x2F中的符号,属性块的事件属性、src属性、data属性均可用于执行javascript,其中事件属性数量较多而src和data属性能否执行javascript跟浏览器的关联较大。而标签块内文本里执行javascript呢,一种是继续创建标签,另一种是标签属于script标签或者是style标签(通过css expression执行,具体跟浏览器关联)。
上面讲的内容都是去掉XSS Vector的前置和后置的Vector是什么样,那么放回去呢?其实从漏洞点的上一级标签看是一致,整个HTML都是靠这样或那样的标签构成。
2.2 Payload样例
在标签属性中执行javascript:
<a href="javascript:alert()">
<img src=a onerror=alert()>
<svg/onload=alert()>
标签文本:
<script>alert()</script>
3. Vector构造
3.1 输出位置在标签块内文本
在这样的输出位置,只要判断一些所处的标签是否一些特殊的标签(script,style,textarea,title等),如果不是,直接构造一个标签来触发脚本比如<img src=xxx onerror=alert()>如果是,则首先通过</标签>的方式来闭合标签,然后构造标签触发脚本。当然如果在script和style的标签文本中可以考虑使用其他方式来触发。比如 ‘; alert();a=’。
结构大致如下( [] 内容为可选):
[</标签名>]Payload[<标签名>]
3.2 输出位置在属性值
在这样的输出位置,一种是考虑直接使用事件等属性来执行脚本,比如 "oninput= "alert()。通过双引号(单引号)闭合前一个属性值的读取完成上一个属性块的构造,再引入分隔符构造测试者想要的属性块(触发能够执行javascript脚本的属性),从而达到执行脚本的目的。如果存在相同的属性,会以前一个的值为准。
结构大致如下:
[" || '] 分隔符 属性名=属性值 a=["|']
另一种是考虑闭合当前的标签重新插入一个新的标签来执行脚本,比如 “><svg/onload><a/a=” 。首先通过双引号(单引号)闭合前一个属性值,再使用>或者/>闭合当前的标签,再构造新标签块,再次闭合原有的结构,避免显示错误(当然可以产生错误,主要是看利用的时候需不需要这样的错误)。
结构大致如下:
[" || '][/]>Payload[<任意字符]
3.3 其他
比较典型的两类在之前都已经说明过了也能让读的人有一个基本的了解,其他情况诸如存在在属性名或者标签名,实在是少见,也就不再重复说明了。
更细致地看构造过程,就只需要把握住两点。第一点,就是浏览器是怎么解析HTML的,HTML本质上是作为文本内容存放在服务端,在客户端的浏览器中被解析呈现出内容。类似于解释性语言,了解了它是怎么被解析的,构造出自己想要的内容就简单多了。另一点呢,就是清楚javascript怎么被浏览器读取以及它的语法结构、框架特征等。作为HTML文本内容中的一部分,也是浏览器接受到javascript(解释性语言,如果不了解可以了解一下)代码后,按照代码逻辑进行执行。
很清楚的了解这些特征后,构造就不再有拘泥于这些框框,完全是根据你的利用方式来,你想要页面呈现出怎么样的一个效果,怎么去利用。甚至可以结合一些编码,浏览器的一些容错机制,构造出一些奇奇怪怪的vector来绕过防御策略。比如上文中每次都是闭合一个,是不是可以考虑多闭合几次呢?
所以Vector还是围绕着怎么用来构造,对于我这样的测试的人来说,就是执行alert,confirm等等这些效果显著但是实际上没啥用的payload。
三、 浏览器解析
这一部分想写写浏览器怎么解析html的,更方便说明之后的绕过姿势的原理。如果可以希望能把浏览器自动补全的机制说明一下,这一方面我自己积累也比较少,希望不是留着的坑。
1. 例子分析
具体分析之前先拿第一节中的payload举个例:
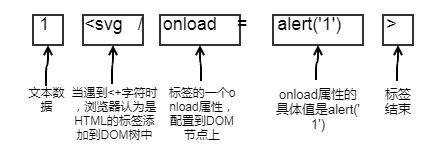
整个执行脚本的过程:浏览在读取HTML文本,构造DOM树,开始渲染页面时,SVG标签有个一个事件属性onload(在加载时触发),触发后就执行其值中的代码。
为什么能执行——用上文中数据和代码的来说就是,程序设计者在原来的考虑中只是输出一个文本的字符串这样的数据,但是浏览器在读取这段数据时,发现0x3C(字符是<)这个字节说明后面可能是一段标签名以及属性,浏览器继续读取便把这段数据解析成了标签加入到DOM树中,而不是作为文本数据展示出来。因为这个原因——浏览器接的只是文本数据,在进行解析时遇到某些包含特殊意义的字节(例如0x3c)时进行一些其他的解析而不是将其作为字符(character)呈现,所以需要采用html实体编码对文本中的一些特殊符号进行转义,让原先这些字节代表的字符能正常显示出来。
2. 组件介绍
从《how browsers work》里拖了一个图一段话,简单的了解一下浏览器,都有哪些部分。
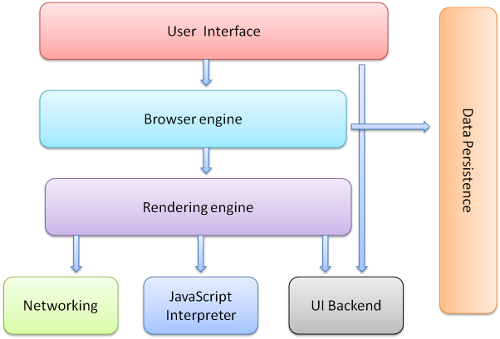
图:浏览器的主要组件
用户界面(User Interface): 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
浏览器引擎(Browser Engine) : 在用户界面和呈现引擎之间传送指令。
呈现引擎( Rendering Engine) : 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
网络(Networking) : 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
用户界面后端( UI Backend) : 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
JavaScript解释器( JavaScript Interpreter): 用于解析和执行 JavaScript 代码。
数据存储(Data Persistence):这是持久层(意思就是涉及需要保存一段时间的数据操作部分)。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
3. 解析过程
从上面的组件介绍可以发现,单从XSS看,关联比较密切的是呈现引擎(Rendering Engine)和JavaScript解释器。其主要有两个框架分别是webkit和gecko,但是在处理流程上大致还是相同的:

流程(《how browsers work》里扒的)
对常规的XSS的漏洞来说,主要考虑第一个过程——paring HTML to construct the DOM tree。它主要就是对从网络上接受回来的字节流标记化构建成DOM树结构,供之后的呈现和渲染使用。 这一部分主要参考了 https://html.spec.whatwg.org/multipage/parsing.html#parsing 一文学习整理。
第一个过程大概上的工作流程如下:
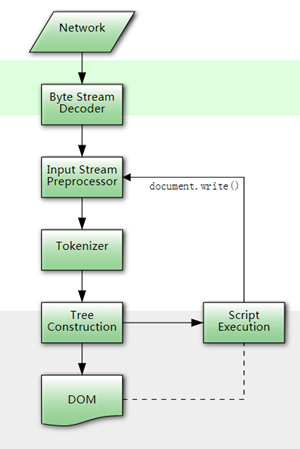
3.1 字节流解码
首先浏览器根据accept-encoding头的解一层压缩(常见的gzip等),获取到真正的用于标记化的字节流。按参考文档所述,浏览器会按照编码探测算法,先预置一个字符集进行解码,直到获取到meta标签中定义的content-type,再将这个字符集作为解码的字符集,重新解码一次内容(如果没有,就会按照原来的探测出的字符集进行解码)。但是在我尝试chrome时,似乎没有进行编码探测的方式,而是按照默认的字符集进行解码(UTF-8)。
像比较早的时候 UTF-7编码绕过XSS检测的方式,就是在这个过程上的绕过尝试。
(如果搞XSS研究的话,这一部分的内容我还有待学习)
3.2 标记化
标记化(Tokenization)的过程,基本上是反射和存储型XSS的Vector能否正常运行的关键。
3.2.1 整体的过程
整个解析标签的过程大致如下(看不清楚可以下载附件):

在走完这个流程以后呢,标签和标签之间的关系大致也确定下来了。标签文本的数据状态如下:
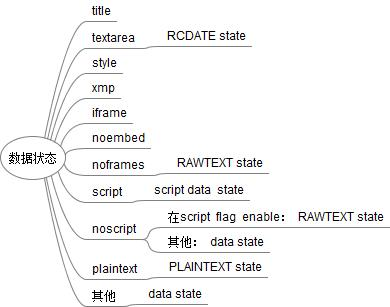
列表中没有列的state主要是两块:属性名和属性值。
3.2.2 涉及编码
在涉及一些的数据状态的读取时,先说明一类编码——字符引用。
字符引用
字符引用里面就包含了通常所有的HTML实体编码。
以&开头,有三类形式
- 一种了定义好的转义如" 中间是字符对应的名字,结尾是一个分号(似乎可以省略)
- &#十进制数; 转成对应的字符 ascii码
- &x十六进制数; 转成对应的字符 ascii码
&X十六进制数;
URL编码
%20 来表示一个字节
%u编码
%u0020 来表示一个unicode字符,具体是采用的字符集确认。
主要由unescape和espcape函数产生。若是网站采用了AJAX的技术,那么基本上可以肯定服务器会对该编码进行解码。(PHP不提供函数解码该编码,也不进行默认解码)。
字符编码
十六进制: \x20
八进制: \x040
Unicode: \u0020
JS混淆
JS混淆在线的内容比较多了,比如jsfuck。
3.2.3 数据状态
Data state:
支持字符引用。
支持嵌入新的标签。
RCDATA state:
支持字符引用。
RAWTEXT state:
不支持字符引用。
Script data state:
不支持字符引用。
PLAINTEXT state:
不支持字符引用。
Attribute Name state:
不支持字符引用。
Attribute Value state:
支持字符引用。
3.2.4 URL解析
当HTML解析器工作完成后,URL解析器开始解析href属性值里的链接。比如 href 属性的值为: javascript:alert('1'),进行url解析时,javascript:这一部分不支持url编码,但是alert('1')部分可以支持url编码。
3.2.5 Javascript解析
到javascript解析时可以解码字符编码中的unicode编码,将其转换成一个字符常量,但是由于被处理成的字符常量,不能用于绕过(),=等涉及到javascript语义解析的特殊字符。
在处理字符串时,支持字符编码中的十六进制和八进制。
4. 容错机制
这是留下的坑,没有找到太完整的资料。
四、 防御机制
这一部分主要想从各个层面去考虑下防御的机制。 思路上还是白名单和黑名单。一方面就是就是从网络层面,应用层面,代码-全局过滤,代码-输出位置的特殊防御机制这些方面简单描述下防御机制。另一方面最好能介绍下,配置在客户端浏览器的一些相关策略,诸如同源策略、沙盒。
1. 数据流
在谈谈有什么样的防御机制时,我个人觉得可以先考虑一下攻击者提交的一段XSS Vector都经过哪些环节,每个环节上都有哪一些防御的措施,而为之后的绕过作一个铺垫。
对于常见的需要与服务端交互的XSS漏洞的数据流如下:
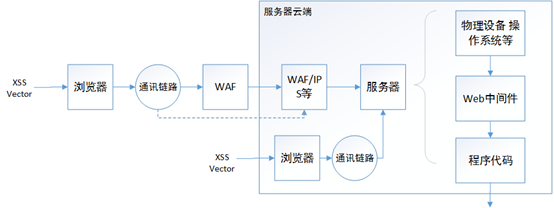
XSS Vector 数据流
注:图中服务器云端指的是Web服务的拥有者所能控制的所有的主机以及网络设备等。
从外面发起的一个包含了XSS Vector的向量请求,数据首先经过浏览器的xss auditor,之后被封装发送到通信的链路中,之后被各种WAF、IPS等防御设备从数据流中还原出原始的http协议内容,进而进行检测,之后被送入到提供Web的服务器中。在进入服务器后,又可能经过系统应用的流量监控应用、中间件,最后作为程序的数据带入到程序的代码逻辑中。在代码逻辑中,数据可能发生了变化,又沿着之前的路径返回到浏览器中,被浏览器解析呈现。
图中的虚线则是说明其他可能,例如可能存在特殊的链路可以直接链接到服务器云端或者是服务器所处的相连区域处发出了XSS Vector。
根据上述过程,为了方便理解,我大致把这些东西划了一个层,并重新制图如下:
应用层面: 包括操作系统中的防护软件、中间件以及浏览器等。(图中红色的块)
外部网络层面: 包括一些公有的防护设备,例如云WAF等。(图中黄色的部分)
内部网络层面: 包括可能进行过专门定制的私有防护设备等。(图中绿色的部分)
代码层面: 包括应用中自实现的过滤或防御机制、SDK、框架下的防御机制。(图中蓝色的部分)
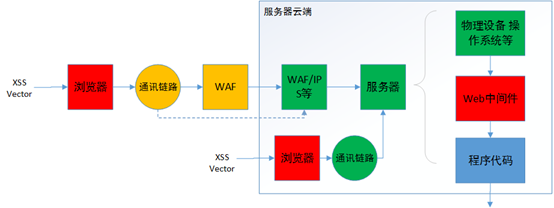
另一类不依赖与服务器交互的DOM型XSS漏洞只与客户端的浏览器进行交互,防御只能靠客户端浏览器的机制以及前端代码中也对数据进行处理。这一部分代码层面的防护实际上与服务器交互的XSS漏洞一致,不同是一个控制的代码位于远程服务器中,一个控制的代码位于客户端的前端代码。
2. 防御机制
2.1 应用层面
2.1.1 浏览器
同源策略(Same origin policy)
同源策略限制从一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的关键的安全机制。(https://developer.mozilla.org/zh-CN/docs/Web/Security/Same-origin_policy)。在使用XMLHttprequest和<img>标签时均会受到该策略的限制。
同源策略虽然不影响测试XSS漏洞,但是是在利用XSS漏洞时必须跨过的一道坎。
Cookie HttpOnly
该配置与同源策略相似,不影响测试XSS漏洞但是会影响漏洞的利用。配置httponly后,javascript脚本无法直接获取到cookie字段信息,从而解决了身份令牌被盗用的情况。具体配置方法,就是设置在set-cookie的头的属性值中添加;HTTPOnly。另外有些语言中提供API直接设置set-cookie属性,例如PHP。
2.1.2 HTTP request-浏览器
在提交HTTP请求时,可能已经经过了一层过滤。比如在chrome中的XSS Auditor和IE中的xss filter 会对一些反射型XSS和DOM型XSS的Vector进行过滤。但是目前在firefox中仍未有相关机制,在这个阶段进行过滤。
且这阶段的防御机制依赖于用户,提供服务的一方没有能力对这个防御机制进行控制。
2.1.3 HTTP response-浏览器
Xss filter/auditor
在http的响应数据包的响应头中插入X-XSS-Protection属性,来启用浏览器的防御策略,具体的使用方法可以自行查询或者参考:http://www.freebuf.com/articles/web/138769.html一文。
该方法在防御检测上采用黑名单的思路进行检测,在检测到相关攻击代码后根据不同的属性值进行不同的处理。
内容安全策略(Content-Security-Policy)
内容安全策略 (CSP, Content Security Policy) 是一个附加的安全层,用于帮助检测和缓解某些类型的攻击,包括跨站脚本 (XSS) 和数据注入等攻击。 这些攻击可用于实现从数据窃取到网站破坏或作为恶意软件分发版本等用途。
尽管内容安全策略在 Firefox 4 中已经包含,使用 X-Content-Security-Policy 头部来实现,但它使用的是过时的 CSP 标准。Firefox 23 包含了更新的 CSP 实现,使用的是 W3C CSP 1.0 标准中描述的没有前缀的 Content-Security-Policy 头部和指令。
参考:https://developer.mozilla.org/zh-CN/docs/Web/Security/CSP
CSP主要就是对内容源(包括style,img,script,iframe等在内的远程资源)进行配置,对这些内容进行控制,从而是前端的Web位于安全的运行环境下。CSP较之同源策略,更加灵活方便。通过在HTTP返回头中插入Content-Security-Policy来进行配置,该头的值就是配置的具体规则。
前端JS框架防御机制
虽然一些前端框架提供了相关的防御能力,但是必须才程序编码时就采用相关的机制。另外由于框架较多较复杂,本文不会涉及。
2.1.4 中间件
目标我并不了解这方面有什么涉及XSS的防御机制。一方面XSS漏洞的攻击体现在客户端,另一个方面中间件离实际的代码逻辑还有点距离,不方便进行处理。
如果有影响XSS漏洞的话,大概是rewrite技术,对功能接口的变量进行一定的隐藏和组合,不易于自动化测试的发现。
2.2 外部网络层面
这个层面上就是一些防御设备,而且是外部的防御设备,诸如云WAF。通过分析数据流中的相关的协议数据包,还原出上层(应用层)的数据。进而,对其中的数据进行分析、处理、判断(实际上与全局过滤器类似,只是规则更加丰富、精确)。但是可能与实际中间件中的处理的方式存在差异。
2.3 内部网络层面
与外部的网络层面不同的是,这一层面的防御设备由提供服务方直接控制。通过分析数据流中的相关的协议数据包,还原出上层(应用层)的数据。进而,对其中的数据进行分析、处理、判断(实际上与全局过滤器类似,只是规则更加丰富、精确)。但是可能与实际中间件中的处理的方式存在差异。
2.4 代码层面
2.4.1 全局过滤器
这一类防御一般是通过拦截器等方式,将使用数据之前对数据进行一次过滤。由于不清楚,之后的实际代码中采用的数据格式情况,一般采用黑名单的策略进行过滤。
而对于触发了机制的黑名单上数据,一般有以下几种处理方式:①截断请求,不执行其中的功能逻辑代码;②删除其中的黑名单数据,继续执行其中的功能逻辑代码;③替换其中的黑名单数据,继续执行其中的功能逻辑代码,按是否需要可以对原始数据进行还原(实际上类似于转义)。
而黑名单一般有以下几种: ① 标签名黑名单,通过字符串搜索或者正则匹配的方式锁定存在风险的标签名 ②事件黑名单,检测方式与标签名黑名单一致 ③ 特殊符号黑名单,防止对原有的DOM结构造成影响,例如' " < > % & # 等特殊符号,④ Javascript危险函数黑名单,在实际测试中经常有遇到,但是实际上这个黑名单并没有什么实际的防御效果,到了javascript解析器这一层,绕过方式实在是太多了,匹配的方式可能没有多大的效果。
2.4.2 局部过滤器
全局过滤器考虑到了系统的可用性采用的黑名单策略,在大概率上存在遗漏。而到了局部过滤器这一层面上,能够针对当前的业务逻辑的实际场景来设计,更多得采用白名单策略进行过滤。
一般的方式有,① 对数据的格式进行判断,例如纯数字、字符集限制、长度限制等。② 对数据进行HTML实体编码,使数据在输出到前端呈现仅作为数据。
五、 绕过姿势
这一部分就是写写怎么绕过了,大概不会写太具体的例子。
1. 绕过分析
对于应用层面上的浏览器的防御机制而言,弹个窗还是没有问题,不行的话,就关闭相关的xss filter/xss auditor。当然也可以尝试绕过,绕过的方式与后面讲的一致。因为在测试中实在没有必要和浏览器较真,但是如果在实际利用中,那就不得不怼上一怼了。
外部网络层面从三个方面考虑,①常规绕过方式(绕过规则匹配)② 尝试使用设备解析协议与实际应用解析不一致,绕过 ③ 绕过外部网络层面,直接访问内部网络层面(云WAF、CDN等技术)。另外该层面中的规则也更加精确,误报较少。
内部网络层面与外部网络层面一致,但是没有第三类绕过方法——绕过当前的设备直接访问服务。不过存在一种例外,就是受害者本身的数据流不经过内部网络层面的防御设备(例如:内部管理员)。另外该层面中的规则也更加精确,误报较少。
代码层面,只能尝试构造不同的Vector去绕过。规则,可能并不精确,存在一定的模糊性,但是不会影响到系统的实际运行。
2. 构造绕过的必要信息
首要是清楚触发的防御机制采用了什么样的策略(黑名单、白名单),尽可能的了解黑白名单中的内容(参考代码层面过滤器中所述内容);再则就是确认数据的允许的字符集以及长度等,根据这些信息来确定支持哪些编码(具体见编码一节);其次就是判断实际的代码中数据支持的编码,是否存在一些自定义的编码格式(也可以关注一下前端的代码,有时候会有奇妙的收获。);最后就是根据浏览器解析一章,结合各个编码组合构造XSS Vector了。采用编码的同时也可以拼入一些触发容错补全等机制的数据,例如<<<<<svg onload=alert(/1/) <!---。
具体怎么绕过就看经验了,绕过正则就是靠构造一些畸形的输入。
六、 测试/利用之道
这一部分没有意外的话,应该只会简单的写写测试的方法大部分内容都是上面有了。而利用这一块,说实话没有经验,像井底之蛙一样,拍拍脑门,造造车,应该是一个有生之年的坑。
测试方面基本没有好讲的,利用方面有一点点了解的就是Clickjacking方式触发嵌入在点击事件中的payload。
七、 参考
l Deep dive into browser parsing and XSS payload encoding (https://www.attacker-domain.com/2013/04/deep-dive-into-browser-parsing-and-xss.html)
译文:http://bobao.360.cn/learning/detail/292.html
l 浏览器的工作原理:新式网络浏览器幕后揭秘(https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/)
l https://html.spec.whatwg.org/multipage/parsing.html#parsing
l https://www.owasp.org/index.php/XSS_Filter_Evasion_Cheat_Sheet
l Javascript字符串编码 https://www.cnblogs.com/52cik/p/js-string-escape.html
附件:
结:
庆祝一下,跑个步,要去挖一个新坑了。
目录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号