
云原生时代的运维体系进化
作者 | 易立
云原生已经成为数字经济技术的创新基石,并且正在深刻地改变企业上云和用云的方式。云原生的用云方式可以帮助企业最大化获得云价值,也给企业的计算基础设施、应用架构、组织文化和研发流程带来新一轮变革。而业务和技术挑战也催生了新一代云原生运维技术体系。
本文整理自阿里云资深技术专家、容器服务研发负责人易立在阿里云联合主办的“2021云上架构与运维峰会”中的演讲实录,分享了云原生时代运维技术发出的重要改变,以及源自阿里云超大规模云原生应用发展进程中的CloudOps实践。

新商业带来新机遇与新挑战
阿里云对云原生的定义是因云而生的软件、硬件和架构,帮助企业最大化获得云价值。云原生技术带来的变化包含几个维度:
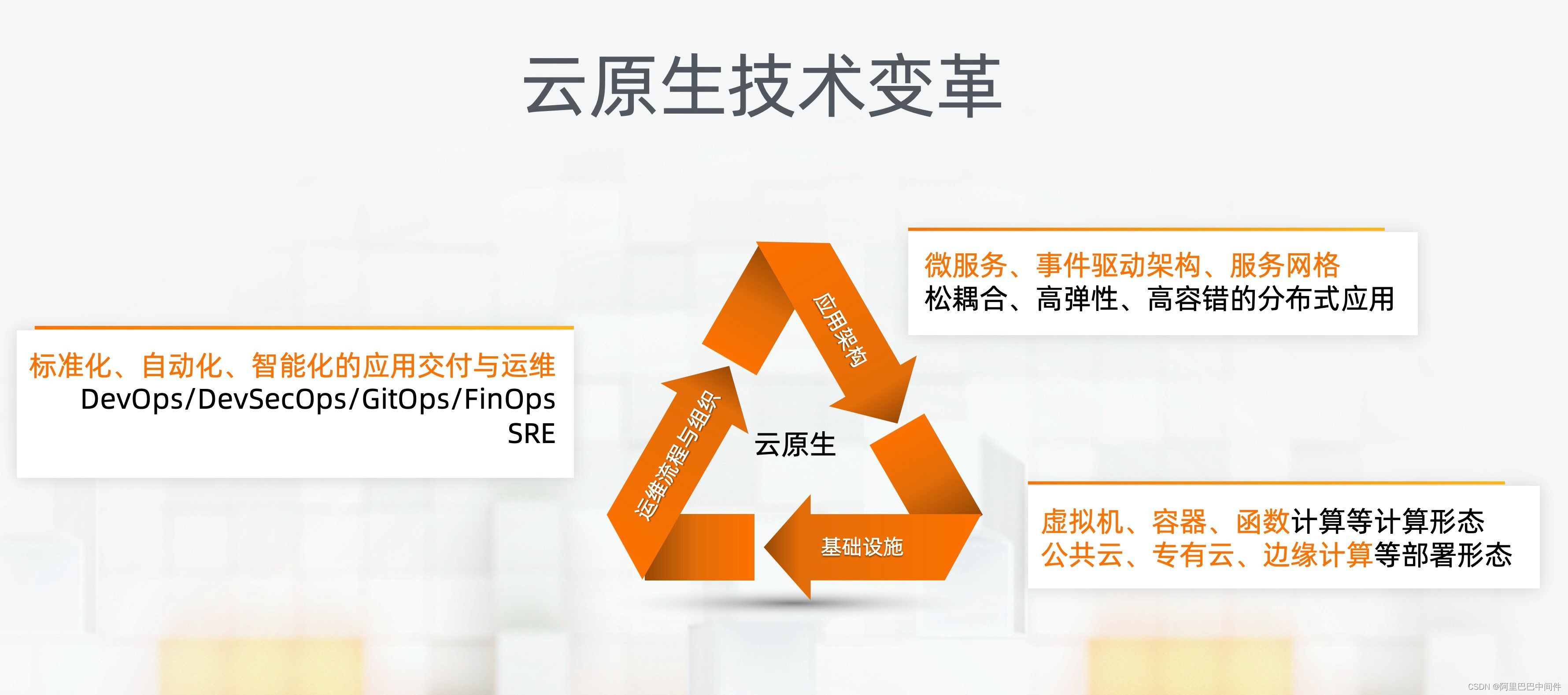
• 首先是计算基础设施的变化,包含虚拟化、容器、函数计算的新的计算形态,帮助应用高效地运行在公共云、私有云、边缘云等不同的云环境。
• 其次是应用架构的变化。利用微服务、服务网格等技术帮助企业构建分布式、松耦合、高弹性、高容错的现代化应用。
• 最后是组织、文化和流程的变化。比如 DevOps、DevSecOps、FinOps、 SRE 等理念持续推动现代化的软件开发流程和组织升级。
回顾云原生出现的时代背景,移动互联网的出现改变了商业的形态,改变了人与人沟通的方式,让任何人在任何时间、任何地点都可以轻松获取自己所需的服务。IT 系统需要能够应对互联网规模的快速增长,并且能够快速迭代、低成本试错。
以 Netflix、阿里为代表的一系列互联网公司推动了新一代应用架构的变革,Spring Cloud、Apache Dubbo 等微服务架构应运而生。微服务架构解决了传统单体式应用存在的几个问题:每个服务可以独立部署和交付,大大提升了业务敏捷性;每个服务可以独立横向扩容,应对互联网规模的挑战。
与传统单体应用相比,分布式的微服务架构具备更快的迭代速度、更低的开发复杂性和更好的可扩展性。但同时,它的部署和运维的复杂性却大大增加。我们需要如何应对?
此外,“脉冲”计算成为常态。比如双十一大促期间,零点需要的算力是平时的数十倍;一个突发的新闻事件,可能让上千万用户涌向社交媒体。云计算无疑是处理突发流量洪峰的更加经济、高效的方式。如何上好云、用好云、管好云,如何让应用可以更加充分利用基础设施的弹性,成为企业运维团队的关注重点。这些业务和技术挑战也催生了云原生的运维技术体系 – CloudOps。
云原生时代运维技术变革
1、云原生运维解决之道
CloudOps 要解决几个关键问题:
• 标准化:标准化可以促进开发团队与运维团队的沟通和协同,标准化也有助于生态分工,推动更多自动化工具的出现。
• 自动化:只有自动化运维,才能支撑互联网规模的挑战,才能持续支撑业务的快速迭代与稳定性。
• 数智化:数据化、AI 增强的自动化运维成为未来发展的必然趋势
2、容器 “应用集装箱”重塑软件供应链
在传统的应用分发、部署过程中,常会由于缺乏标准导致工具碎片化,比如 Java 应用和 AI 应用的部署,需要完全不同的技术栈,交付效率低。此外,为了避免应用之间的环境冲突,我们经常需要将每个应用单独部署在一个独立的物理机或者虚拟机上,这也造成了很多资源浪费。
2013 年开源的容器技术 Docker 出现,开创性地提出了基于容器镜像的应用分发和交付方式,重塑了软件开发、交付和运维的整个生命周期。

就像传统的供应链体系为例,不管什么样的产品都是通过使用集装箱来进行运输,极大提升了物流效率,使得全球化的分工协同成为可能。
容器镜像将应用和其依赖的应用环境一同打包。镜像可以通过镜像仓库进行分发,可以一致的方式运行在开发、测试和生产环境中。
容器技术是一种轻量化 OS 虚拟化能力,可以提升应用部署密度,优化资源利用率,与传统的虚拟化技术相比,更加敏捷、轻量,具备更好的弹性和可移植性。
容器作为云时代的“应用集装箱”,重塑了整个软件供应链,也开启了云原生技术浪潮。
3、容器技术加速不可变基础设施理念落地
在传统的软件部署和变更过程中,经常会出现因为环境间的差异导致应用出现不可用的问题。比如,新版本应用需要依赖 JDK11 的能力,而如果部署环境中没有更新 JDK 版本,就会导致应用失败。“It works on my machine”也成了开发人员打趣的口头禅。而且随着时间的推移,系统的配置已经不可考,采用原地升级的方式在变更的时候一不留神就会掉进坑里。
不可变基础设施(Immutable Infrastructure)是由 Chad Fowler 于 2013 年提出的一个理念,其核心思想是“任何基础设施实例一旦创建,就变成为只读状态,如需要修改和升级,则使用新的实例进行替换。”
这种模式可以减少配置管理的复杂性,确保系统配置变更可以可靠地、重复地执行。而且一旦部署出错时可进行快速回滚。
Docker 和 Kubernetes 容器技术正是实现 Immutable Infrastructure 模式的最佳方式。当我们为容器应用更新一个镜像版本的时候,Kubernetes 会新创建一个容器,并且通过负载均衡将新请求路由到新容器,然后销毁老容器,这避免了令人头疼的配置漂移问题。
4、Kubernetes:分布式资源调度的标准及 CloudOps 最佳载体
目前,容器镜像已经成为了分布式应用交付的标准。Kubernetes 已经成为了分布式资源调度的标准。
越来越多的应用,通过容器方式进行管理、交付:从无状态的 Web 应用,有状态的数据库、消息等应用,再到数据化、智能化应用。
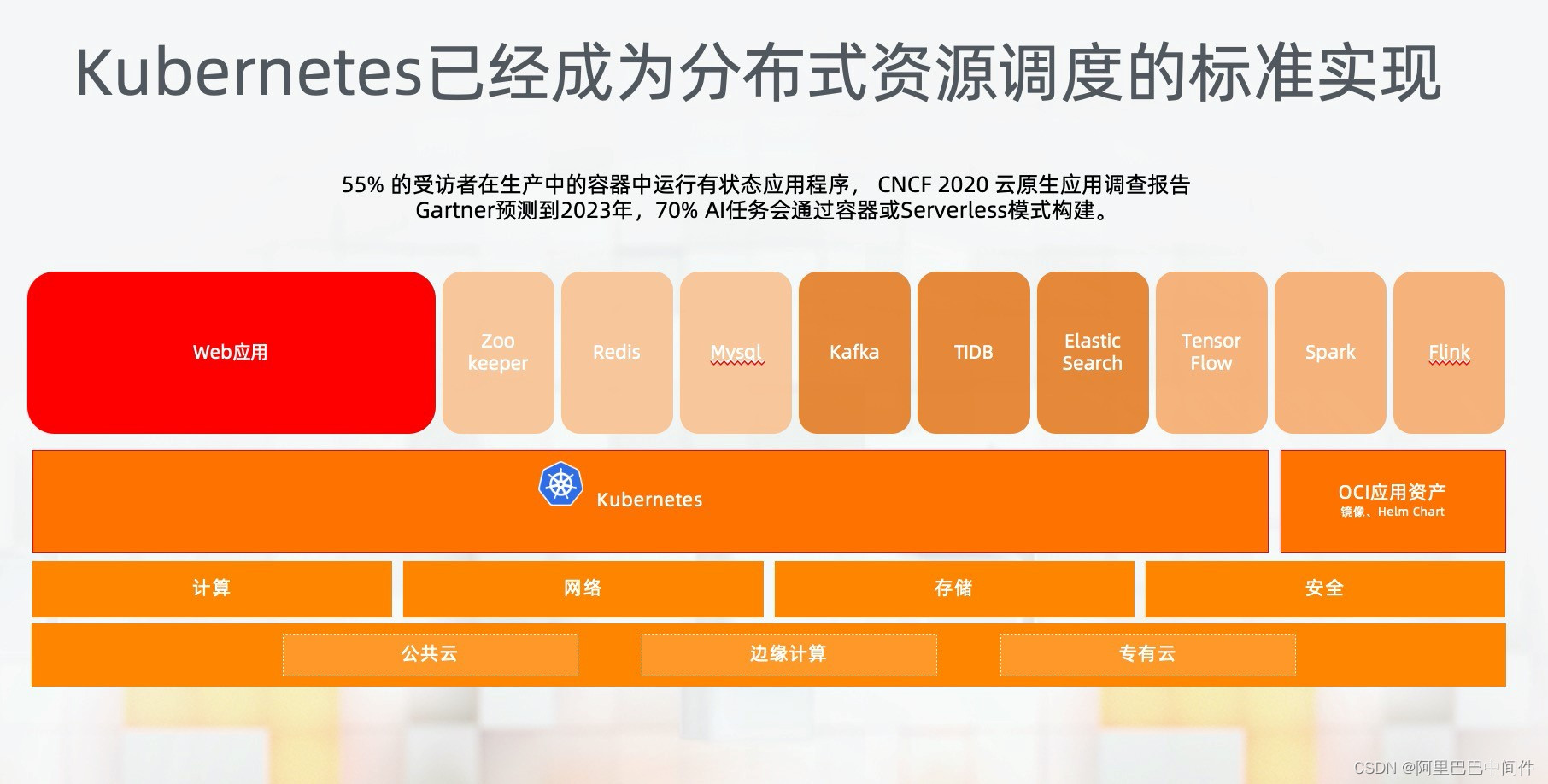
CNCF 2020 年调查报告指出,55%的受访者已经在生产中的容器中运行有状态应用;Gartner 预测到 2023 年,70%的 AI 任务会通过容器或 Serverless 模式构建。
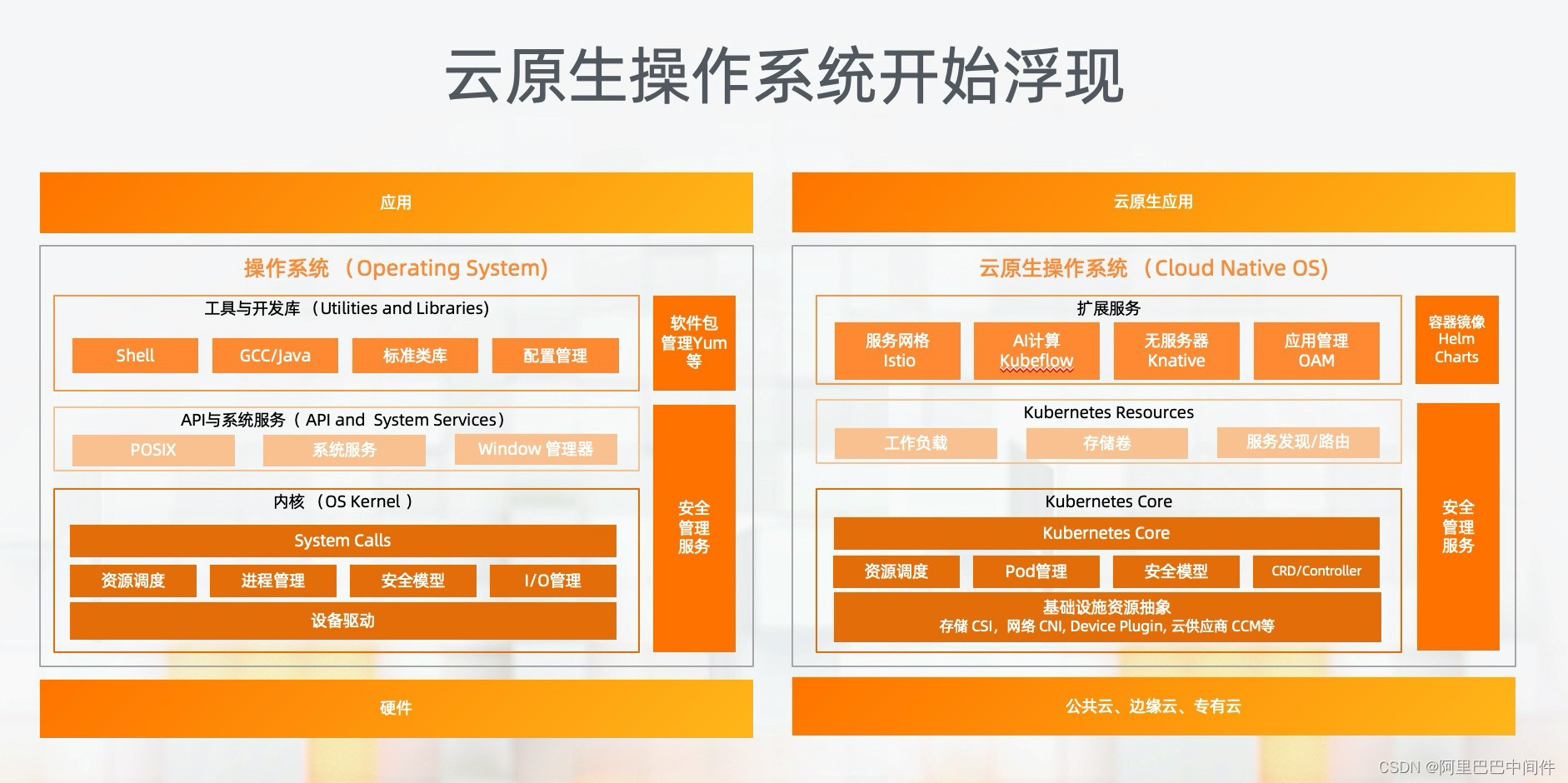
对比一下经典的 Linux 操作系统和 Kubernetes 的概念模型,他们的目标都是向下封装资源,向上支撑应用,提供了标准化的 API 来支持应用生命周期,并且提升应用的可移植性。
不同的是,Linux 的计算调度单元是进程,调度范围限制在一台计算节点。而 Kubernetes 的调度单位是 Pod 一个进程组,它的调度范围是一个分布式集群,支持应用在公共云、专有云等不同环境间进行迁移。
对于运维团队而言,Kubernetes 成为实现 CloudOps 理念的最佳平台。
首先是 K8s 采用声明式 API,让开发者可以专注于应用自身,而非系统执行细节。比如,在 Kubernetes 之上,提供了 Deployment、StatefulSet、Job 等不同类型应用负载的抽象。声明式 API 是云原生重要的设计理念,有助于将系统复杂性下沉,交给基础设施进行实现和持续优化。
此外,K8s 提供了可扩展性架构,所有 K8s 组件都是基于一致的、开放的 API 进行实现和交互。开发者也可通过 CRD(Custom Resource Definition)/ Operator 等方式提供领域相关的扩展,极大拓宽了 K8s 的应用场景。
最后,K8s 提供平台无关的技术抽象:如 CNI 网络插件, CSI 存储插件等等,可以对上层业务应用屏蔽基础设施差异。
5、为什么是 Kubernetes?
Kubernetes 的成功背后的魔法就是控制循环,Kubernetes 有几个简单的概念。
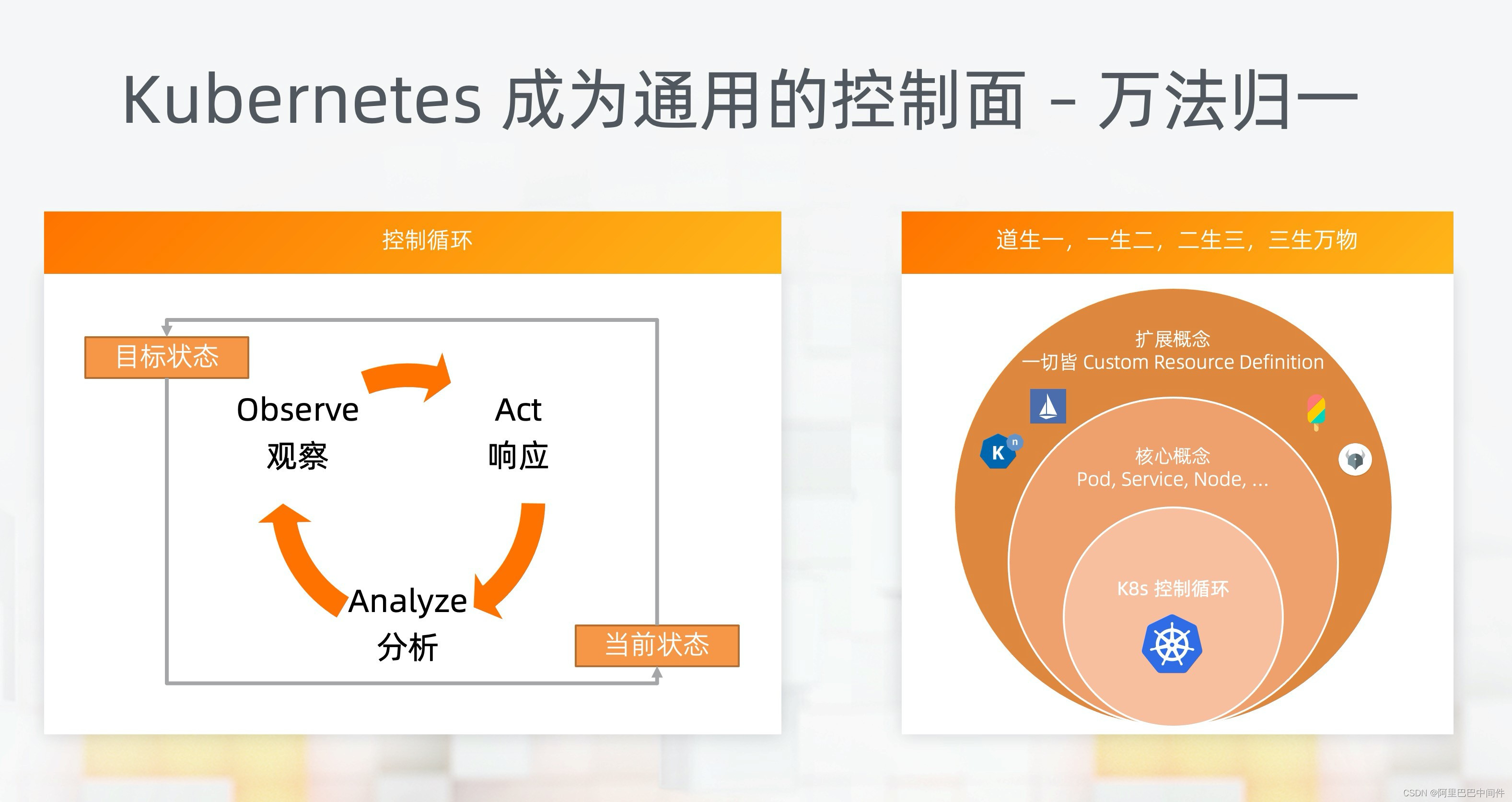
首先,一切都是资源,通过控制器对资源进行自动化管理。
用户可以声明资源的目标状态。当控制器发现资源当前状态与目标状态存在不一致,就会持续调整,让资源状态趋近于目标状态。通过这个方法,可以统一处理各种情况,比如,根据调整应用副本数进行扩缩容,或者节点宕机后应用自动迁移,等等。
正因如此,Kubernetes 支持资源范围已经远超容器应用。比如服务网格,可以对应用通信流量进行声明式管理;Crossplane 可以利用 K8s CRD 对 ECS,OSS 等云资源进行管理和抽象。
6、云原生应用自动化管理探索与开源实践
K8s 控制器 “把复杂留给自己,把简单交给用户”的理想非常美好,然而实现一个高效、健壮的控制器却充满技术挑战。
OpenKruise 是阿里云开源的云原生应用自动化管理引擎,也是捐献到 Cloud Native Computing Foundation (CNCF) 下的沙箱项目。它来自阿里巴巴多年来容器化、云原生的技术沉淀,解决容器应用在大规模生产环境的自动化和稳定性挑战。
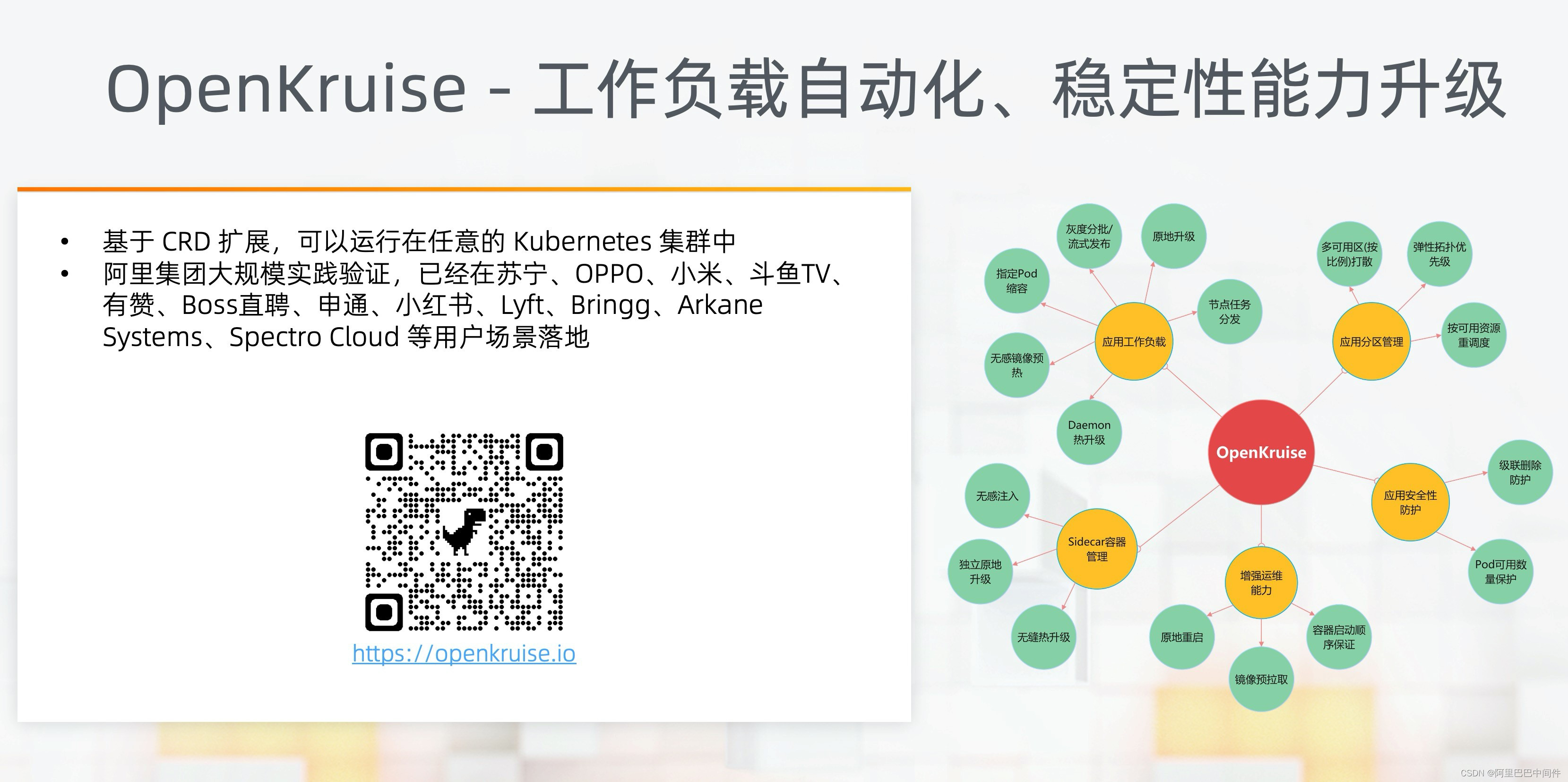
OpenKruise 提供了增强的应用灰度发布,稳定性防护,Sidecar 容器扩展等多种能力。
OpenKruise 开源实现和集团内部版本代码保持一致。支撑了阿里集团应用 100%云原生化,也已经在苏宁、OPPO、小米、Lyft 等企业得到广泛应用。欢迎大家社区共建和使用反馈。
7、GitOps:声明式 API 催生的应用交付流程与协同新方式
基础架构即代码(Infrastructure-as-Code,IaC)是一种典型的声明式 API,它改变了云上资源管理、配置和协同的方式。利用 IaC 工具,我们可以将云服务器、网络和数据库等不同云资源进行自动化的创建、组装和变配。

将 IaC 概念进行延伸,可以覆盖整个云原生软件的交付、运维流程,即 Everything as Code。本图列出来云原生应用涉及的各种模型,从基础设施、到应用定义、到应用交付管理和安全体系,我们都可以通过声明式方式对应用的配置进行管理。
比如,我们可以通过 Istio 来对应用流量切换进行声明式处理,可以利用 OPA(Open Policy Agent)来定义运行时安全策略等等。
更近一步,我们可以将应用的所有环境配置都通过源代码控制系统 Git 进行管理,并通过自动化的流程进行交付和变更。这样就是 GitOps 的核心理念。
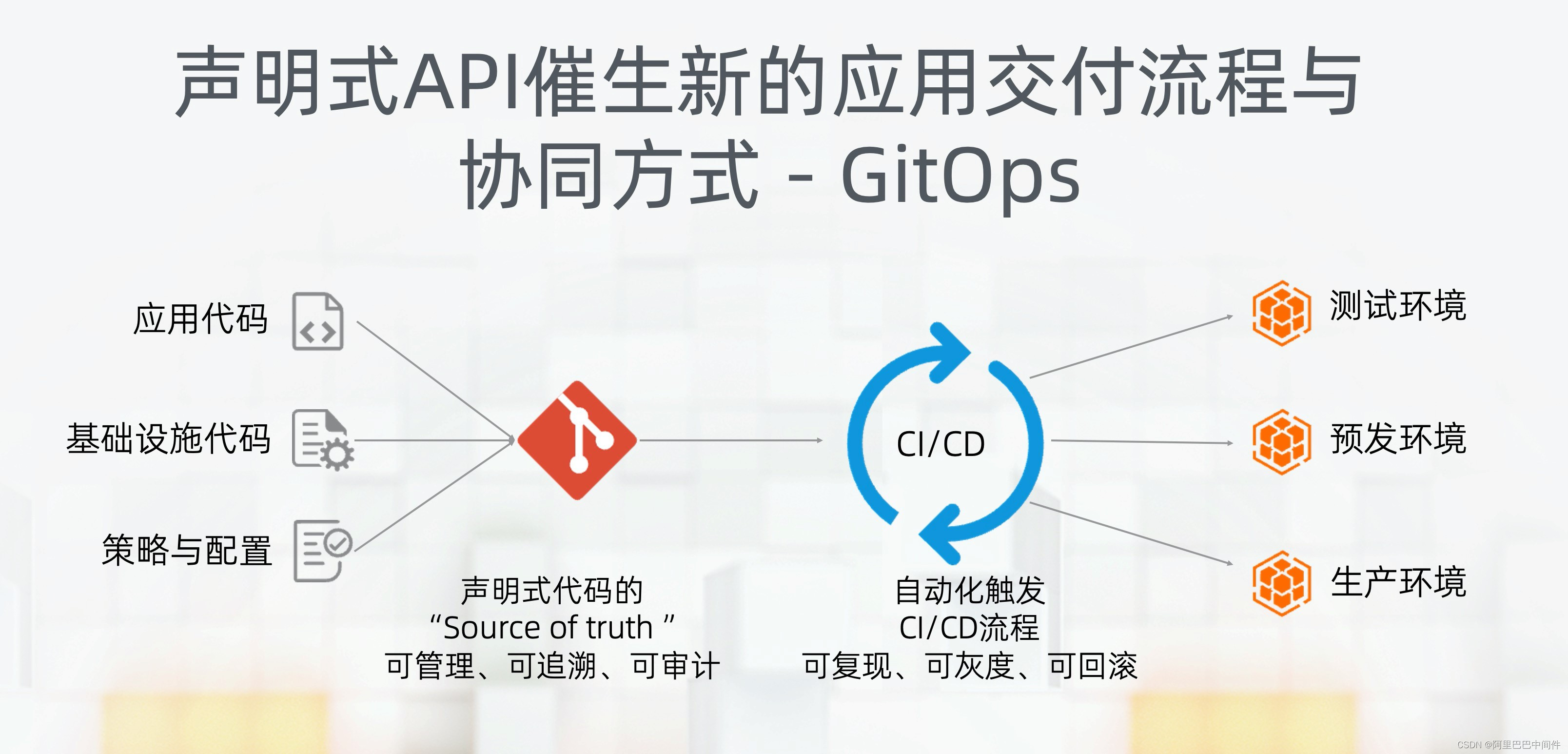
首先,从应用定义到基础设施环境,所有的配置都以源代码的方式保存在 Git 中;所有变更、审批记录也记录在 Git 的历史状态中。这样 Git 成为 sourceof truth,我们可以追溯变更历史、可以回滚到指定版本。
GitOps 与声明式 API、不可变基础设施相结合,保障了应用环境的可复现性,提升了交付与管理效率。GitOps 在阿里集团已经被广泛使用,在阿里云容器服务 ACK 中也有支持。目前 GitOps 开源社区也在不断完善相关的工具和最佳实践,大家可以关注相关进展。
8、云原生催生稳定性思想变革
分布式系统存在高度复杂性,在应用、基础设施、部署过程中任何一个地方的问题,都可能导致业务系统的故障。
面对这样的不确定性风险,我们有两种做法:一种是“听天由命”,信佛祖,不宕机;一种是通过系统化的方法进行主动出击,提升系统的确定性。
2012 年,Netflix 提出了“混沌工程”的理念,通过主动注入故障的方式,提前发现系统的薄弱环节,推进架构的改进,最终实现业务韧性。我们可以将混沌工程的工作方式比作疫苗,通过“接种灭活疫苗”的方式,让我们的免疫系统受到锻炼,具备抵挡 “疾病” 的能力。
阿里双十一购物节的顺利成功,离不开全链路压测等对混沌工程的大规模实践,为此阿里团队在这个领域积累了丰富的实战经验。
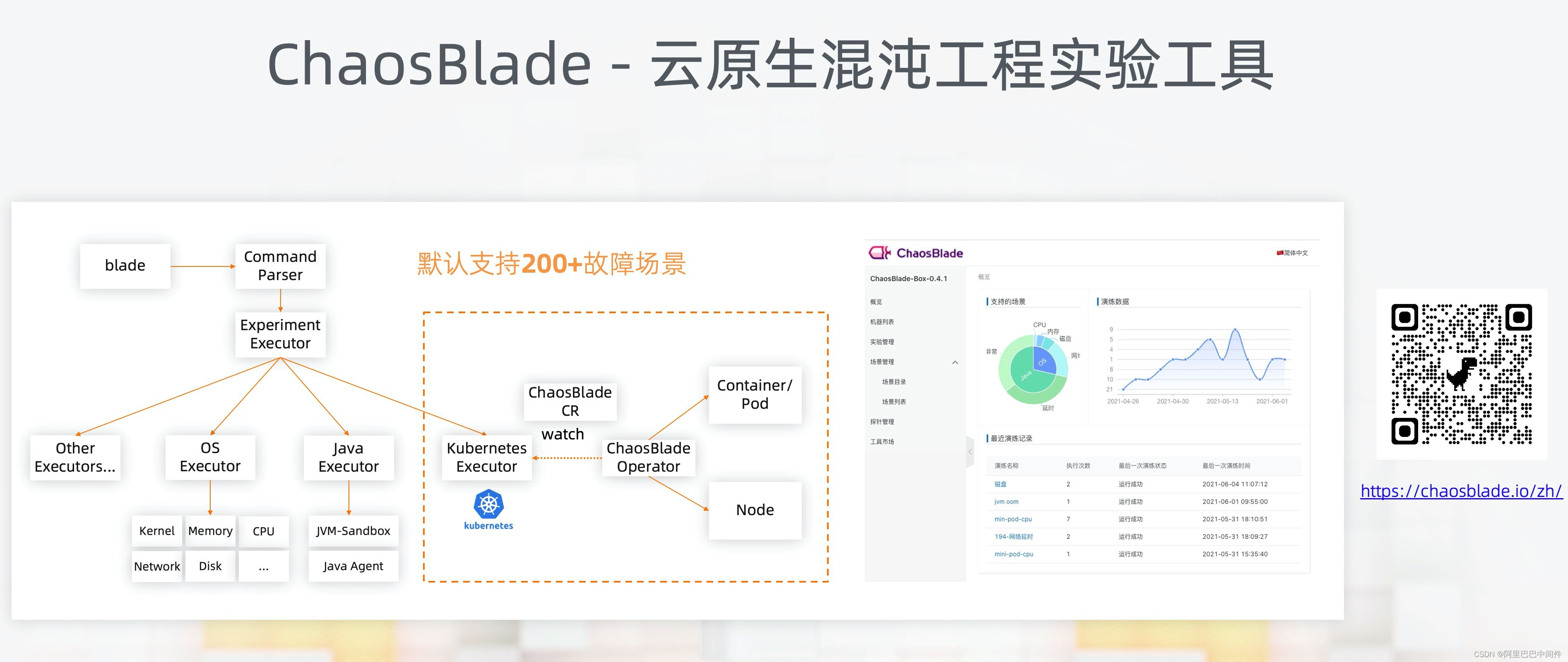
ChaosBlade 是一组遵循混沌工程理念的实验工具,具有场景丰富、简单易用等特点,已经成为 CNCF 沙箱项目。它支持 Linux、Kubernetes、Docker 等不同运行环境,以及 Java、NodeJS、C++、Golang 等多种语言。内置了 200 多个场景的测试方案。
chaosblade-box 是新引入的混沌工程控制台,可实现实验环境平台化管理,进一步简化用户体验,降低使用门槛。欢迎大家加入 Chaosblade 社区共建,也可以使用阿里云应用高可用服务 AHAS 云服务。
云原生 CloudOps 之路
最后我将结合阿里实践,介绍我们在 CloudOps 上的一些探索。
在传统组织中,开发和运维角色是严格分开的。而不同业务线也构建了一个一个的烟囱化架构,从基础设施环境与运维,到应用运维与开发,都是独立的团队,缺乏良好的协同与复用。
云时代的到来也在改变着现代 IT 组织和流程。
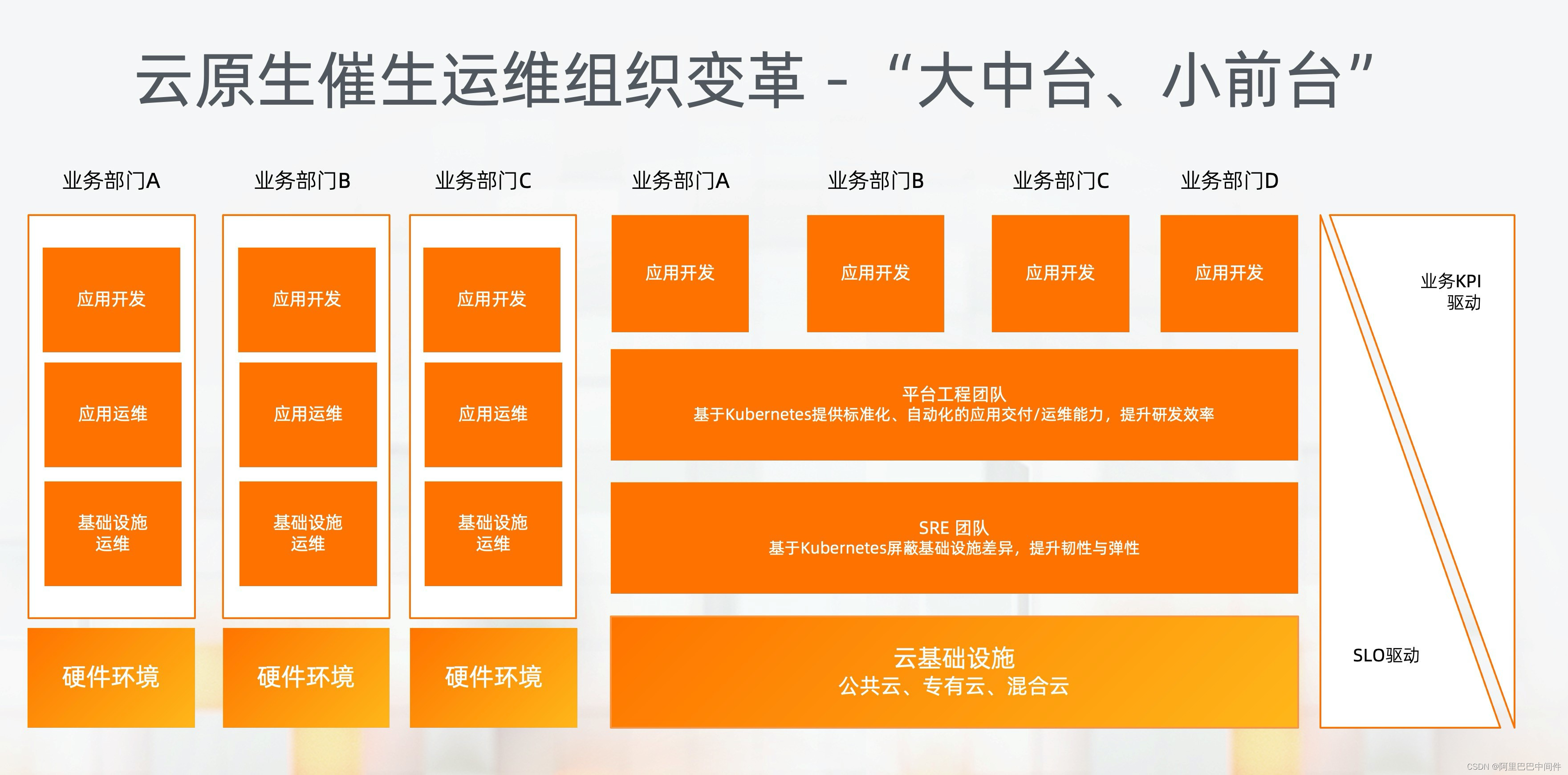
首先,公共云、专有云成为了不同业务部门间共享的基础设施。
然后,SRE (Site ReliabilityEngineering)理念开始得到广泛接受。是通过软件和自动化手段,来解决系统的运维复杂性和稳定性问题。由于 Kubernetes 的标准化、可扩展性和可移植性等优势,越来越多企业的SRE团队基于 K8s 管理云环境,极大提升了企业运维效率与资源效率。
在此之上,平台工程团队开始浮现,基于 Kubernetes 构建企业的 PaaS 平台和 CI/CD 流程,支持中间件和不同业务部门的应用部署与运维。提升企业的标准化和自动化水平,进一步提升应用研发、交付效率。
这样的分层结构中,向下的团队更多是通过 SLO 驱动,从而让上层系统对底层依赖技术具备更好的可预期性。越向上的团队更多是业务驱动,更好地支撑业务发展。
1、阿里云容器服务 SRE 团队的最佳实践
阿里云容器服务 SRE 团队一直也在践行 CloudOps 的最佳实践,简单总结如下:

第一项是全局稳定性架构设计,让整个平台防范与未然:
• 首先 Securityby-design:让系统做到默认安全,同时通过安全软件供应链保障全生命周期安全
• 其次 Designfor failure:控制爆炸半径、提供限流/降级手段降低故障影响面
• 第三 Designfor automation:类似扩缩容、故障恢复等工作尽可能自动化完成
• 最后 Observabilityby-design:为每个生产应用定义 SLO,并建立相关的可观测性体系,持续关注请求量,延迟、错误数、饱和度等黄金指标
第二项是建设稳定性应急体系,也就是我们日常所说的 1-5-10 快恢能力,它包含:
• 1 分钟发现 - 包括通过黑盒、白盒监控能力
• 5 分钟定位 - 提供诊断大盘,利用工具实现自动化根因定位
• 10 分钟止损 - 包含系统化的预案的设计与持续积累,和自动化预案执行
最后一项是日常稳定性保障,主要包含:
• 变更管理规范化 – 所有发布做到可灰度、可监控、可回滚
• 问题跟踪流程化 - 凡事有交代,件件有着落,做一个靠谱青年
• 故障演练常态化 – 通过巡检、突袭、压测等手段查漏补缺,让故障预案持续保鲜
2、拥抱云原生运维技术体系
云原生已经成为势不可挡的技术趋势。Gartner 预测到 2025 年,95%数字化运维将通过云原生平台进行支撑。
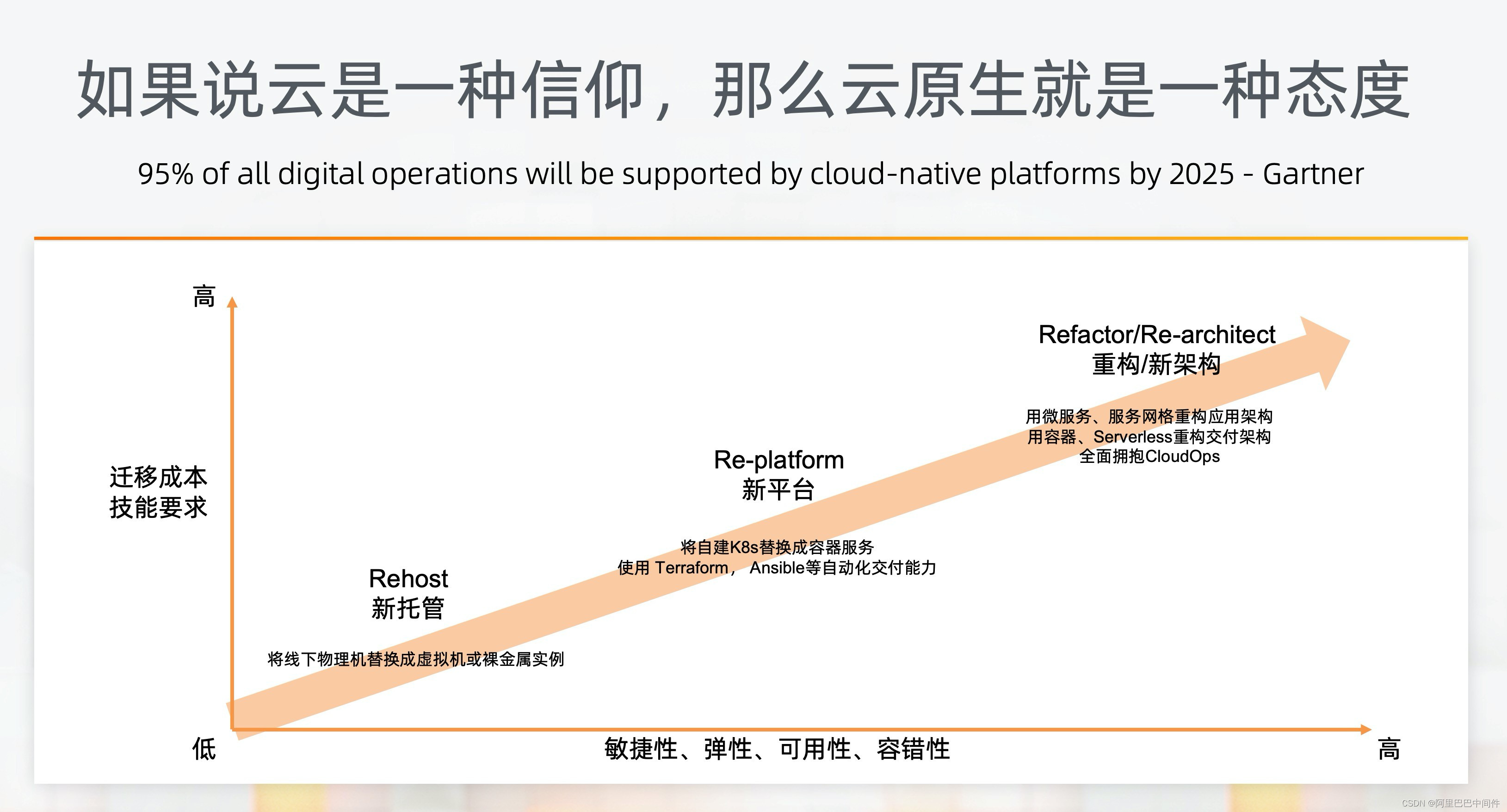
我们可以根据企业能力和业务目标选择合适的迁云之路,大致可以分为几个阶段:
• Rehost 新托管:简单地通过 lift-and-shift 方式,将线下物理机替换成为云上虚拟机或者裸金属实例,不改变原有的运维方式。
• Re-platform 新平台:利用托管的云服务替换线下自建应用基础设施,比如通过 RDS 数据库服务替换自建 MySQL,通过阿里云容器服务 ACK 来取代自建 K8s 集群。托管的云服务通常提供更好的弹性、稳定性和自治运维能力,可以让用户关注于应用而非基础设施管理。
• Refactor/Re-architect 重构/新架构:包括对单体应用的微服务架构改造、容器化和 Serverless 化等现代化改造。
从 Rehost、Re-platform 到 Re-architect,我们可以看到迁移的复杂性和所需技能在增加,但是敏捷性、弹性、可用性、容错性等收益也在持续增加。
阿里集团上云也经历了这样的历程,在2020年业务 100%上公共云的基础之上,2021年实现了应用 100%云原生化。帮助阿里业务的研发效率提升了 20%,资源利用率提升了 30%。

最后做一个快速总结。基于容器、Kubernetes 等云原生技术,提供的开放社区标准、不可变基础设施、声明式 API 会成为企业 CloudOps 的最佳实践,也将在这个基础上推进数据化、智能化体系建设,将运维复杂性进一步下沉,让企业可以聚焦于自己的业务创新。阿里云也将持续向外输出自身在超大规模云原生实践和探索中的能力沉淀,与更多企业、开发者一起,躬身入局,全面拥抱云原生运维技术体系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号