Adversarially Regularized Autoencoders 阅读
发表在 ICML 2018
动机
深度隐变量模型 VAE 和 GAN 在连续结构上表现很好,但应用到离散结构(如文本序列或离散图像)上却表现较差,在此篇论文中,作者针对此提出了一个灵活的方法来训练深度隐变量模型。
方法
基于之前提出的 WAE(Wasserstein Autoencoder,将对抗性自动编码器(AAE)形式化为最佳运输问题)。作者首先将该框架扩展为离散序列建模,然后进一步探索针对可控表示的不同学习先验知识。我们的模型从输入空间到对抗正则化的连续隐空间中学习编码器。但是,与使用固定先验的 AAE 不同,作者像 GAN 一样改为参数化先验学习。 像序列 VAE 一样,该模型不需要使用策略梯度或连续松弛。 与 GAN 一样,该模型通过参数化生成器学习先验提供了灵活性。
形式化
模型(ARAE)
主要是将离散的自编码器和 GAN 的正则化的潜在表示结合起来
-
Discrete Autoencoder
两个过程:编码 X --> Z
解码 Z --> X'
损失函数:交叉熵损失
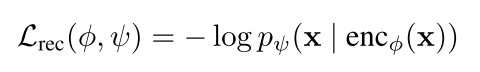
-
Generative Adversarial Networks
生成器 G:z~ = g(s)
判别器 D
Pz 和 P* 分别为生成、真实的分布
使用 Wasserstein-1 distance(WGAN中使用到的)来最小化 W(Pz, P*)
损失函数:
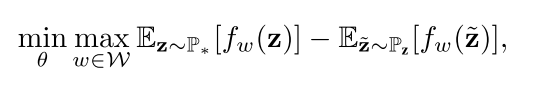
-
ARAE
模型框架:
其实就是上面的两种模型进行了一个结合
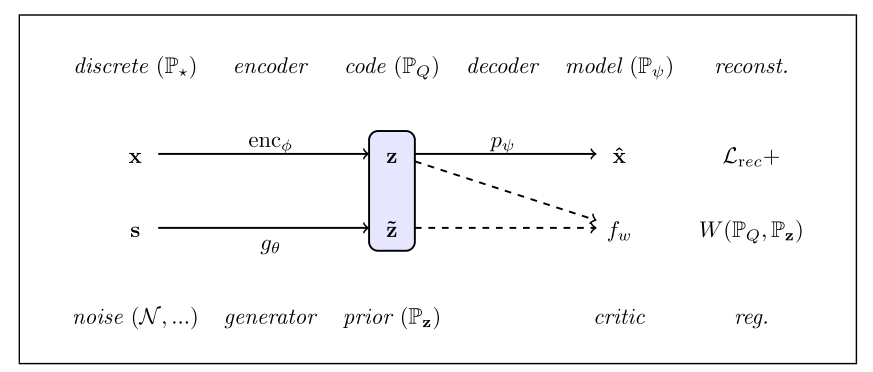
算法:

但是将上面的模型直接用于离散的结构(如文本序列)时,是很难进行优化的,因此当此模型用于非对齐的文本风格迁移时(sentiment and topic),需要能分离出句子中的属性信息,使其能够包含在 y 中,而其他信息包含在 z 中:
因此引入了隐空间的属性分类,其损失函数为:

训练方法
三个步骤:
- 使用离散图像在MNIST的二值化版本上训练一个 encoder(MLP)-decoder(参数逻辑回归)模型
- 在 Stanford Natural Language Inference (SNLI) 语料库上训练一个文本序列模型(RNN)
- 使用 YELP/Yahoo 数据集训练一个非对齐的 情感/主题 的文本风格迁移(同文本序列模型相同并额外添加了一个分类器来判别属性)
实验

PPL(困惑度):用来评价语言模型的好坏,本质上是计算句子的概率
基本思想:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好
计算公式:句子越好(概率大),困惑度越小,也就是模型对句子越不困惑
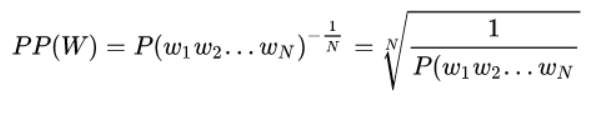
文本风格迁移任务:
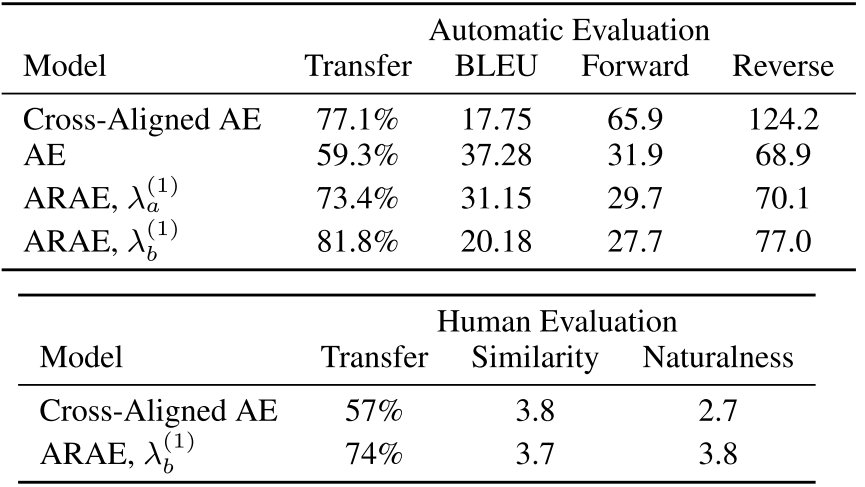
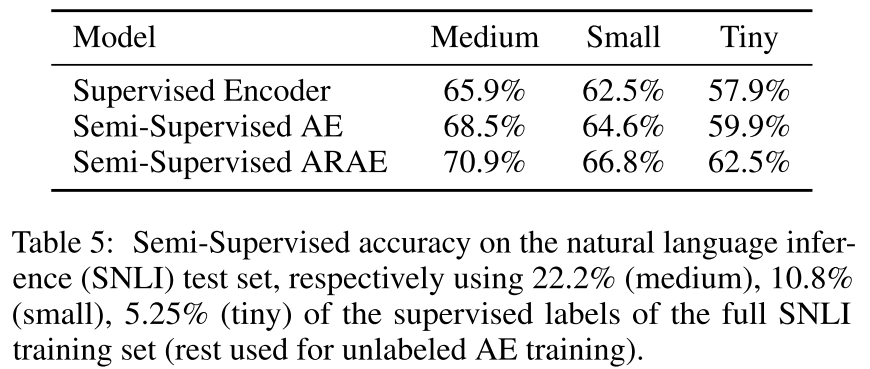
半监督学习模型:
并验证了正则化对离散结构的作用:能够快速收敛

下游任务包括两个:sentiment 和 topic transfer


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端