
Apache Dubbo 云原生可观测性的探索与实践
*作者:宋小生,平安壹钱包中间件资深工程师、Apache Dubbo committer
可观测建设
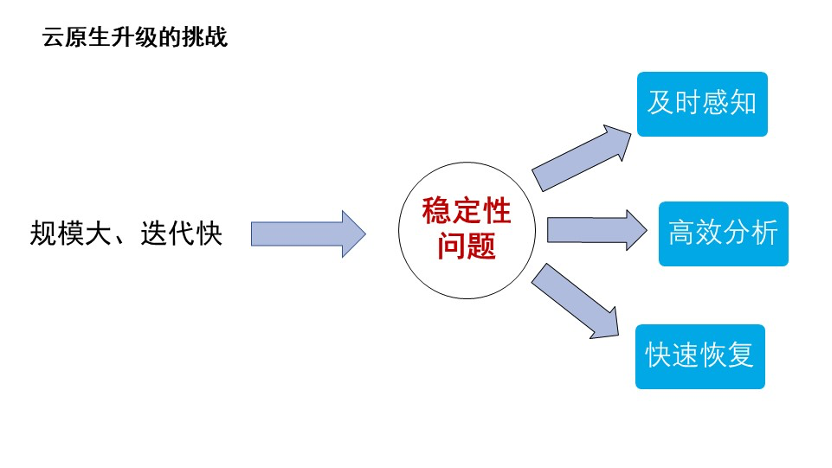
首先介绍一下云原生升级的挑战。 目前大部分公司里基本上都有 CICD、DevOps 来帮助开发、测试、运维提升开发的效率与质量,也会有容器化来帮助提升产线运维的效率与质量。但在云原生时代,大规模容器的频繁变更会带来很多稳定性的问题。这些稳定性问题,包含了很多我们可以提前规避掉的已知的异常,也包含了很多我们无法避免的异常,比如网络故障、机器宕机等系统无法提前避免的的问题。
如果我们能提前发现这些问题,其实是可以规避掉很多风险的。通过可观测系统及时的感知问题,高效的分析异常,快速的恢复系统。因此可以判定,在云原生时代,可观测系统的建设是非常重要的。
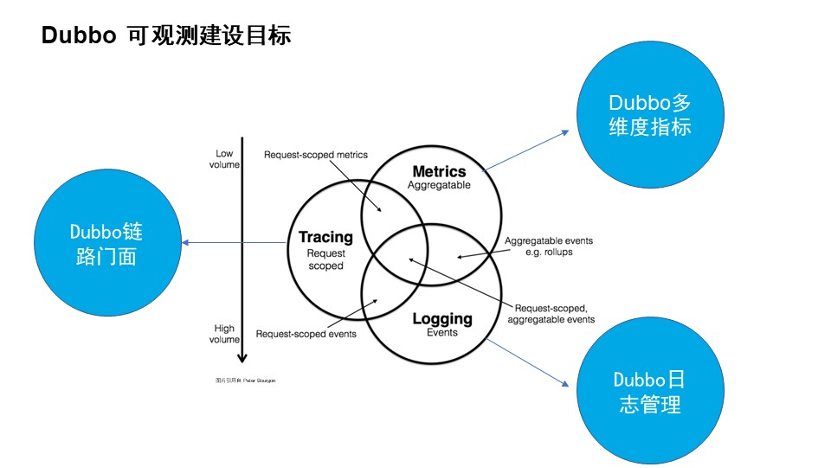
Dubbo 作为微服务 RPC 的框架,直接建设一个大而全的可观测性系统或者平台是不现实的,而且与定位也不是很符合。可观测性系统更强调关联性,通过单维度或者多维度进行系统的观测与问题的诊断。
首先看一下可度量系统的健康状态的指标。Dubbo 通过采集系统内部的 Dubbo 指标的同时,把指标内部的数据指标暴露给外部的监控系统。这些监控指标中包含了很多的应用信息、主机信息、Dubbo 服务等标签信息。当我们发现问题的时候,可以通过这些标签信息关联到全链路系统。之后全链路系统可以做到请求级或者应用级的系统性能或者系统异常的分析诊断。
Dubbo 侧通过适配各大全链路厂商形式提供全链路门面,只需进行非常简易的依赖引入和配置就可以直接把数据导出到各大全链路平台。无论企业使用哪个流行的全链路平台,在后期升级 Dubbo 后都可以直接把链路数据导出去。
另外,链路系统还包含全链路的 Traceid 或者局部的 SpanId。通过全链路的 ID,我们可以在链路系统直接跳转到日志平台。在日志平台里包含非常详细的日志上下文,这些日志上下文可以提供非常精确的异常问题诊断。
Dubbo 也提供了非常详细的错误码机制和专家建议的形式,在官网上通过日志的形式可以通过错误码直接导航到官网上的帮助文档。
多维指标体系
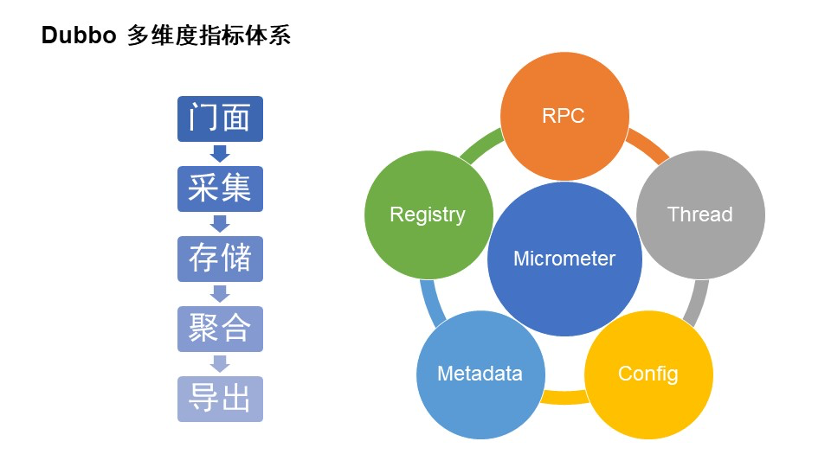
Dubbo 在多维度指标体系实践的时候,我们主要从两个维度来看它。
第一个是纵向的维度。 Dubbo 指标在采集的时候有一个接入导出的流程。Dubbo 为用户和开发者提供了简单易用的接入门面。接入后服务在运行过程中通过指标器进行指标的采集。Dubbo 中提供了非常多的指标采集器,包括聚合和非聚合的指标采集等等。
然后采集的指标会通过变量值临时存储在内存里,之后会有部分指标(QPS 等带有滑动窗口的最小值、最大值的聚合指标)进行聚合计算,最后这些指标会导出到外部系统。我们支持在 Dubbo QPS 服务质量服务中进行指标导出,或者把指标导出到 Prometheus,又或者 http 直接访问也可以进行指标的查询。
第二个是横向的维度。 Dubbo 指标采集覆盖了非常容易出现异常的地方。比如 Dubbo 3 提供了三大中心,包括注册中心、元数据中心、配置中心,存在外部网络交互的地方也是非常容易出现问题的。
另外一个比较关键的是 RPC 链路上的数据采集,比如请求相关的耗时、异常、Netty、IO 的指标等等。此外还有一些关于 Dubbo 线程池资源信息的指标采集。
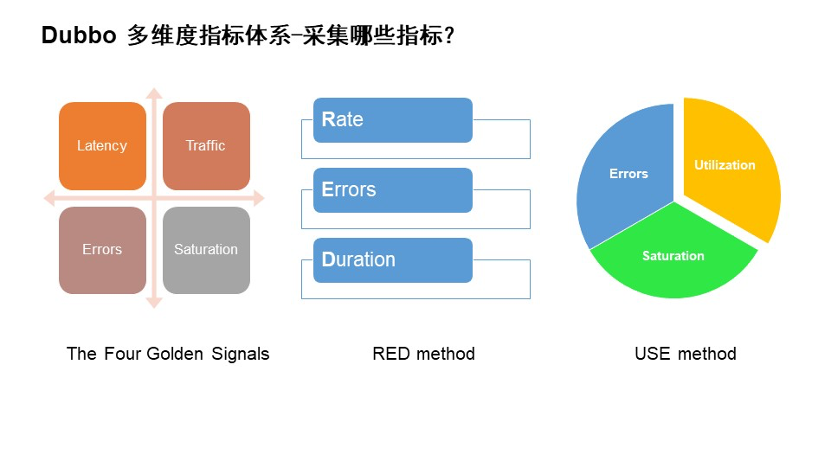
前面说的是比较大面上的指标采集,具体 Dubbo 的采集需要哪些指标我们也调研了很多比较流行的方法论。
- 图中第一张图是谷歌 SRE 书中提到的四大黄金指标。它是谷歌总结大规模的分布式服务监控总结出来的,它可以进行请求级别的服务质量的衡量,主要包含延迟、流量、错误以及饱和度。
- 图中第二张图是 RED 方法。它更侧重于请求,从外部视角来查看服务的健康状态,主要包含速率、错误与持续时间。
- 图中第三张图是 USE 方法。它更侧重于系统内部的资源使用情况,包含利用率、饱和度与错误。
可以看到,以上三个指标的方法论中都包含的指标是错误,错误也是每个开发者比较关注的。

然后我们进行了指标的系统完善。在 Dubbo 3.2 版本中,多维度指标体系已经完成,而且也在快速持续的版本迭代中。在这个版本中我们只需要引入一个快速集成的 Spring Boot 中的 Starter 包就可以实现指标的自动采集。之后我们通过 Dubbo 的 QPS 服务质量端口可以直接访问到。如果是本机可以通过浏览器,如果是服务器上可以通过 curl 命令访问 22222 端口,后面加一个 metrics 路径,这样就可以看到非常详细的默认指标的导出。
通过指标名字可以看到这些带有 Dubbo 前缀指标,类型是 Dubbo 的不同模块,比如消费者提供的请求级别,三大注册中心一起线程。
下面是 Dubbo 当前指标的行为,然后响应时间,最后会加一些单位,这个格式参考的是 Prometheus 的官方格式。

多维度指标体系有些人可能会直接复用 Spring Boot 默认的 manager 管理端口,Dubbo 也适配了一下 Spring Boot Actuator 的扩展。
操作和刚刚一样,只是引入 Spring Boot Starter 包。后面也无需做任何其他的配置,就可以在 Spring 端口里看到详细的指标了。包括 Spring Boot 内置的 jvm 指标、Dubbo 指标等等。
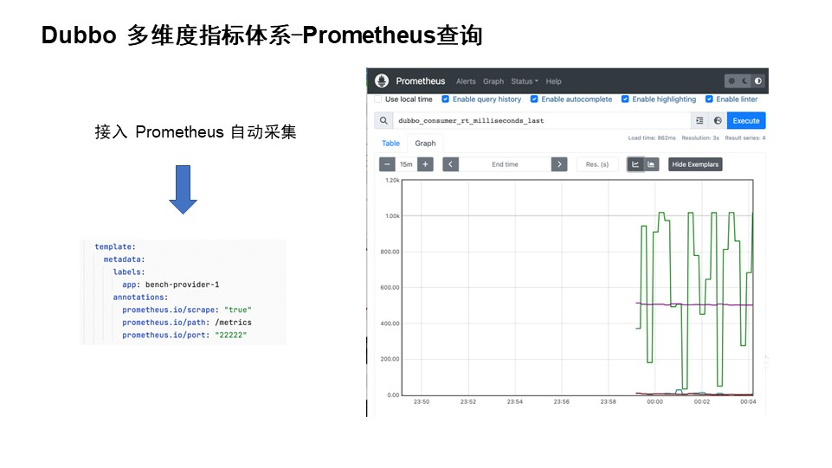
指标体系接入之后,我们如果直接通过命令行访问只能看到一些瞬时的数据,但在监控指标体系我们其实更关注的是多维度的向量数据。如果我们把这些数据看作是一个点其实是比较难看出问题的,所以我们需要把这些数据存储起来,看作是一个实际化的向量数据。
Dubbo 默认提供对 Prometheus 采集的接入。Prometheus 作为指标存储与监控一体的监控系统,提供了很多的服务发现模型。比如我们直接把服务部署在 K8s 上,可以直接基于 K8s 的服务发现机制进行指标采集。如果公司有自建的 cmdb 系统,可以自己扩展服务发现接口进行指标采集。此外,还有文件或者静态的服务发现机制,只要能发现 Dubbo 服务的 IP 和服务接口,就可以进行指标采集。采集到的指标会自动存储在 Prometheus 的时序数据库里。
上图是我们通过 Prometheus 的查询框查询出来的响应时间的最新指标。
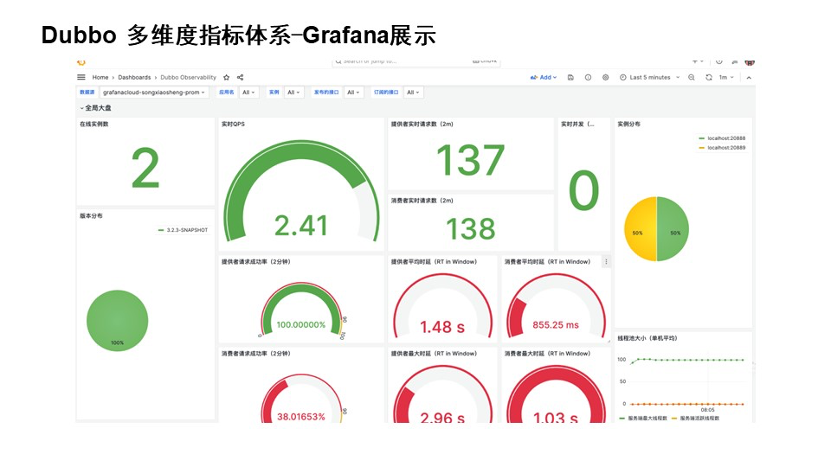
Prometheus 的指标更侧重于存储与报警,如果我们想更直观的体现还需要接入 Grafana。Grafana 的目标是为企业提供简易接入的监控面板,上图是一个简易的全局大盘。
我们通过筛选框可以做应用级别/机器 IP 维度/服务接口维度的筛选查询,查询服务的健康状态。可以看到,这些指标基本上都是基于前面总结的方法论实现的。比如 QPS、请求数量、成功率、失败率、请求的时延等等。
此外,还有一些应用信息的指标,比如升级 Dubbo 3时,想看到哪些应用已经升级到新的版本,就可以看到新的应用的版本号,也会有应用信息的实例 IP 分布,还有一些线程资源。
链路追踪门面
刚才说的指标比较抽象,它更利于帮助我们发现问题,更多的场景下需要进行系统之间的问题的诊断。微服务系统往往是多个系统之间有关联关系,所以服务之间的诊断更依赖于全链路系统。
全链路系统的建设,当时考虑使用 Agent 的方式,这种方式对于用户接入是非常方便的,在代理层直接注入一些指标采集的方式即可。如果用这种方式在企业里做全链路的覆盖是非常方便的,但如果 Dubbo 只做 Dubbo 的链路数据采集,风险会比较大。因为 Agent 接入后会进行字节码修改出现无法提前发现的问题或者其他的不兼容的问题,有些时候很难在前期发现。
另外,Dubbo 也调研了一些开源的链路追踪门面。Dubbo 选择通过原生内置门面的形式,让专业的事情交给专业人做。Dubbo 通过适配各大厂商的全链路追踪系统,快速适配接入的用户,只需增加少量的配置就可以实现链路数据的导出。
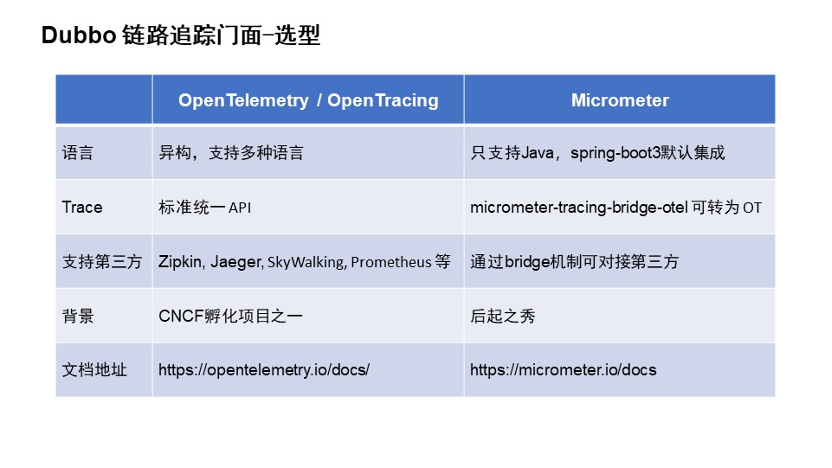
在链路追踪门面的选型方面,我们参考了业界比较流行的几个链路,从中挑选了两个进行选型,分别是 OpenTelemetry 和 Micrometer。
OpenTelemetry,大家应该非常熟悉,它支持多语言,规范标准统一的 API,支持大部分流行的第三方厂商的全链路追踪系统,是 CNCF 孵化的项目之一,很多中间件应用都已经接入了这种规范。
Micrometer,大家可能对它的印象是指标采集的接入。它的缺点是只能支持 Java,但它在语言方面,优点是 Spring Boot 3 默认的指标采集,链路采集默认支持 micrometer-tracing 的功能。此外,Micrometer 它还可以通过桥接包直接转化为 OTEL 的协议,间接也支持各种第三方的采集。并且 Micrometer 自身也通过桥接机制可以桥接很多的全链路厂商。
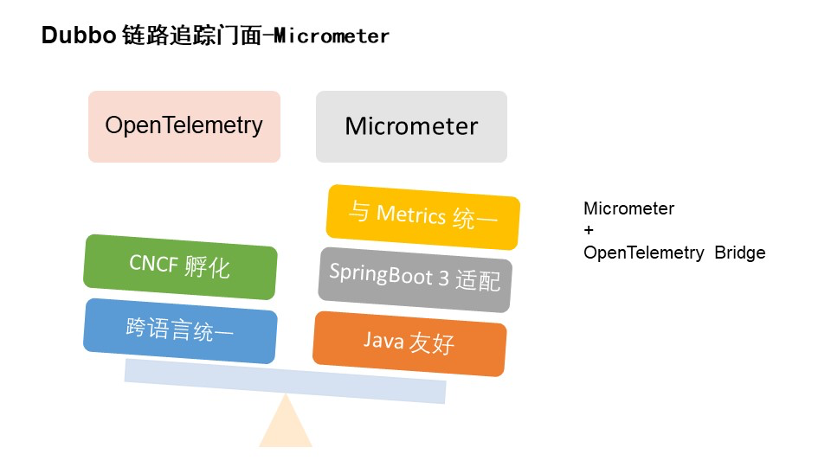
我们为了和前面使用到的指标采集进行统一,使用 Micrometer 后无需额外引入第三方的依赖,只需使用 Micrometer Tracing 的桥接包,就可以快速的接入。
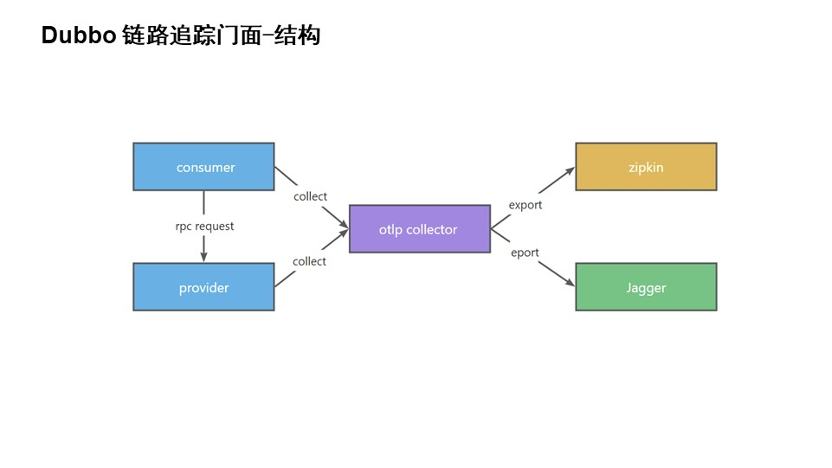
上图是链路追踪系统的简单结构。Dubbo 的链路采集主要采集 rpc 请求的链路。在消费者发起请求的时候,如果存在链路 ID 就直接复用,没有的话会产生链路 ID,然后把它们上报给采集器。同样消费者也会通过 rpc 的上下文把链路数据透传给提供端。提供端拿到这个链路数据后,会对它进行父子关系的关联。最后把这些链路数据上报采集器。
采集器在前面的时候主要是内存级别的操作,对系统的损耗比较小。后面将进行异步的导出,和前面指标体系是一样的。内存级的同步采集,异步的把数据导出到第三方的链路系统。

链路系统接入也比较简单,主要是引入 Spring Boot Starter 的依赖包,进行一些比较简单的配置,包括不同厂商的导出地址配置等等。
链路系统可以帮助大家分析性能与异常,但一些系统问题原因的排查可能需要更详细的日志上下文来进行关联。这个时候这个链路系统会把数据放到日志系统的上下文 MDC 里面,然后在日志在上下文里把链路系统存入的内容取出来,展示到日志的文件里。
日志文件可能也会接触到第三方的日志平台,如果有二次开发能力,可以在这种系统平台里加上链接,让这些 Traceid 自动跳转,即全链路系统自动跳转到日志平台,日志平台也可以自动跳转到全链路系统,查询问题会非常高效。
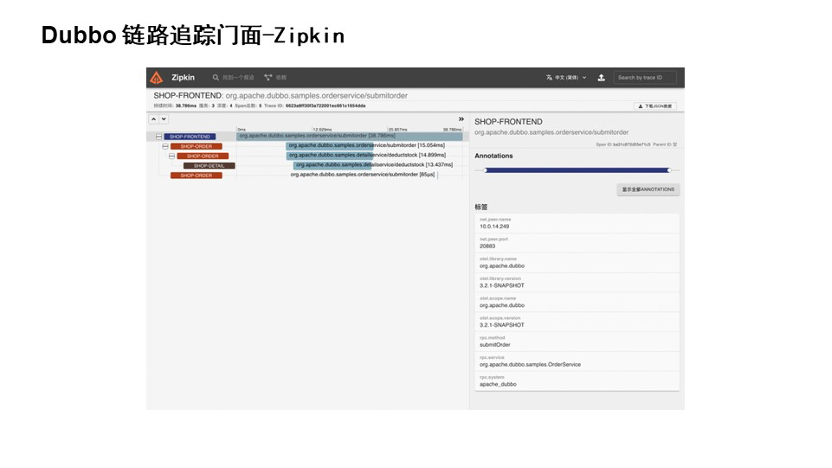
上图是接入 Zipkin 的展示页面。可以看到它可以进行应用级的性能分析和接口级的性能分析。还可以看到一些 Dubbo 元数据,它的标签可以和指标大盘指标体系进行关联关系。
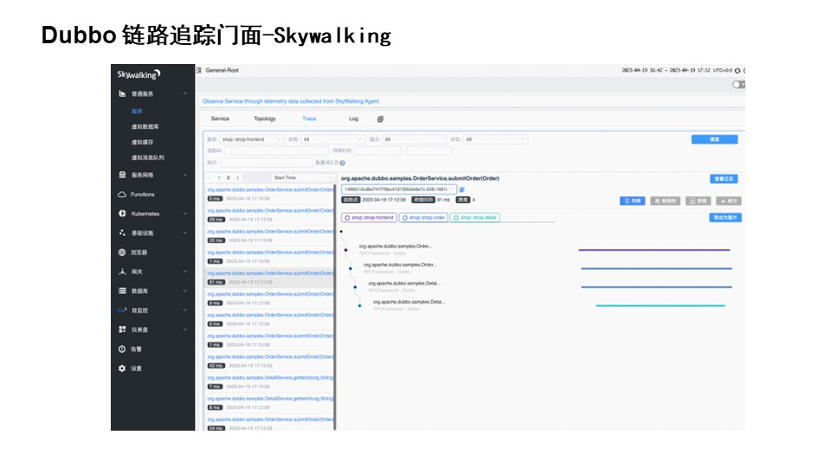
这是 Skywalking 的格式,包括列表形式、表格形式等等。它通过 Traceid 搜到全链路的请求链路,也可以进行性能和异常的诊断。
日志管理分析
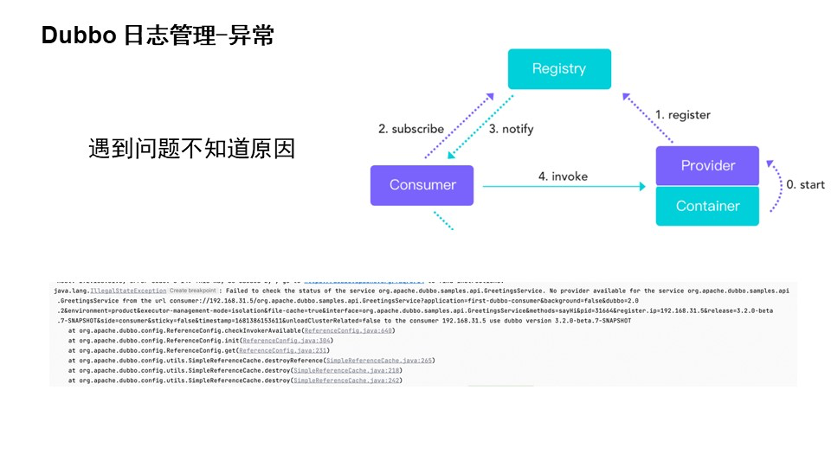
Dubbo 通过日志门面的形式适配了各大日志组件。因为我们的日志组件在后期发展的体系是非常多的,可能是历史原因。不过 Dubbo 已经通过门面的形式适配了各大日志组件。
系统运行过程中,非常容易出现问题的地方包括,服务的注册与发现,注册服务发现模型,服务提供端的注册,服务消费端的订阅与通知,服务 rpc 请求链路。
当出现这些问题的时候,系统会出现异常。如果我们直接查看异常/网上检索/通过源码形式分析的话,不仅比较困难而且非常耗时。
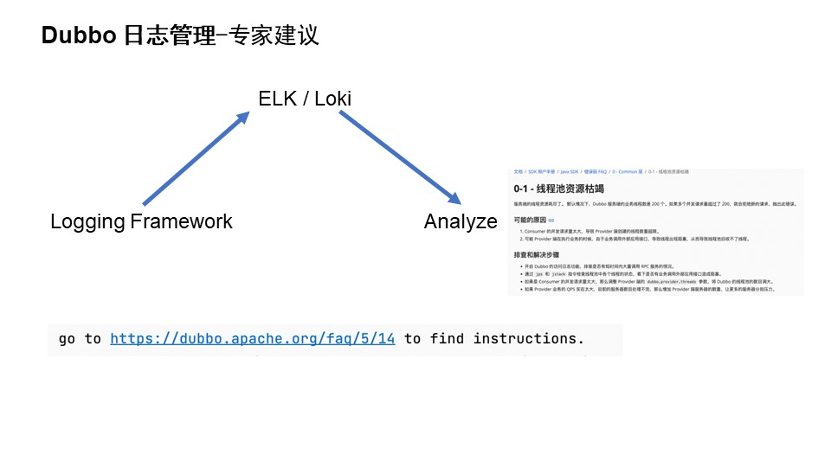
基于此,Dubbo 做了一个专家建议帮助的文档手册。升级到 Dubbo 3 版本后,可以看到出现异常时日志里会有一个帮助文档的 FAQ 链接的形式。这个帮助手册套里提供了一些问题可能出现的原因和排查问题的解决思路。
对排查问题比较感兴趣的同学,可以直接打开官网看一下。里面包含了非常多资深专家提供的问题诊断的思路, 不过专家建议手册的建设更希望社区里的用户和开发者们一起共同建设。
稳定性的实践
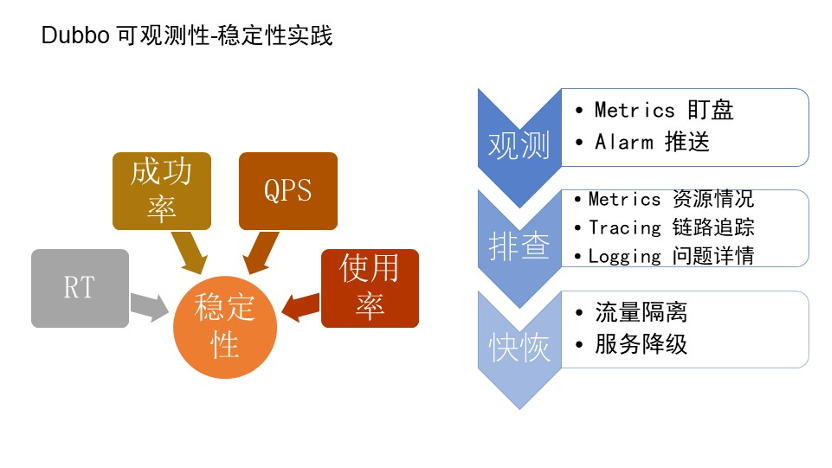
最后我们结合指标、链路、日志进行稳定性实践的介绍。 主要分为两个部分:观测系统的异常和快速的恢复。
观测系统的异常 : 在整体全链路系统建设之后,运营人员 24 小时值班来主动的观测监控大盘发现告警,也有通过邮件、短信、钉钉的形式被动的收到告警。无论通过哪种形式,收到告警之后可以尝试使用可观测性思维,通过一些常见的、和异常相关的指标进行排查。通过这个方法,你可能会发现一些问题,但不一定是根因。这个时候你可以通过指标发生问题的地方找到全链路系统,之后分析哪个系统的哪一段有问题定位到相关位置。如果排查不到问题,再通过链路系统的全链路 ID 关联到日志,通过日志里排查详细原因。
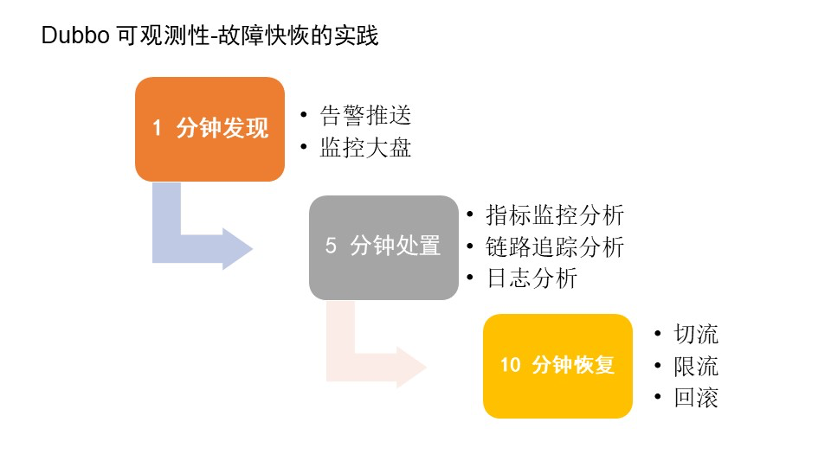
快速的恢复: 有了前面的原因定位后,基本上就可以知道哪里有问题了。这个时候可以根据你的原因进行流量的治理。比如切换机房流量,对流量进行限流,或者你的系统有异常的时候进行系统的降级或者回滚。
如果指标、链路、日志也排查不到根因问题,就尝试先恢复系统,减少损失,然后观测更多的数据或者通过工具进行详细的根因分析定位吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号