
Prometheus监控系统资源故障报警
准备环境:
|
主机 |
环境 |
部署内容 |
|
192.168.220.130 |
centos7.6 |
node_exporter-1.2.0.linux-amd64 |
|
192.168.220.131 |
centos7.6 |
node_exporter-1.2.0.linux-amd64 |
|
192.168.220.129 |
centos7.6 |
prometheus-2.28.1.linux-amd64 alertmanager-0.21.0 grafana-8.0.6-1.x86_64.rpm node_exporter-1.2.0.linux-amd64 |
安装node_exporter
下载解压下载地址:
https://github.com/prometheus/node_exporter/releases/download/v1.2.0/node_exporter-1.2.0.linux-amd64.tar.gz
tar -xzvf node_exporter-1.2.0.linux-amd64.tar.gz -C /opt ln -s /opt/node_exporter-1.2.0.linux-amd64 /opt/node_exporter vim /usr/lib/systemd/system/node_exporter.service [Unit] Description=node_exporter After=network.target [Service] Type=simple User=prometheus ExecStart=/opt/node_exporter/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target chown prometheus:prometheus /usr/lib/systemd/system/node_exporter.service chown prometheus:prometheus /opt/node_exporte
设置开机启动
systemctl daemon-reload
systemctl enable node_exporter.service
systemctl start node_exporter.service
systemctl status node_exporter.service
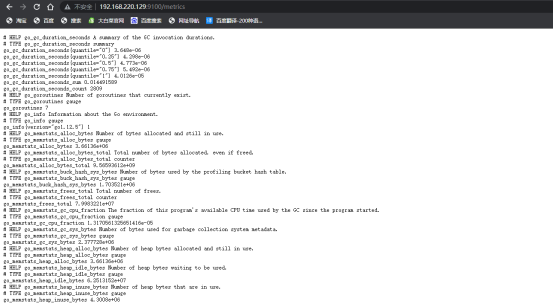
浏览器访问http://192.168.220.129:9100/metrics,会跳转到metrics页面,通过轮询的方式更新数据
修改prometheus.yml
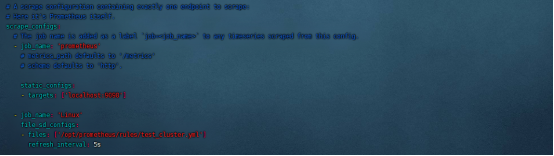
将 node_exporter 加入 prometheus.yml配置中
vim /opt/prometheus/prometheus.yml - job_name: 'Linux' file_sd_configs: - files: ['/opt/prometheus/rules/test_cluster.yml'] refresh_interval: 5s
vim /opt/prometheus/rules/test_cluster.yml - targets: ['192.168.220.129:9100'] labels: name: Linux-test1 - targets: ['192.168.220.130:9100'] labels: name: Linux-test2 - targets: ['192.168.220.131:9100'] labels: name: Linux-test3
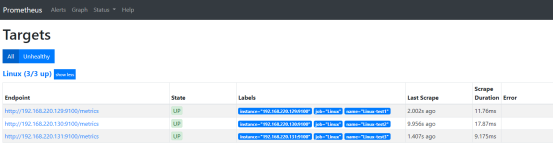
重启prometheus服务
systemctl restart prometheus.service 或者热加载 curl -X POST http://localhost:9090/-/reload

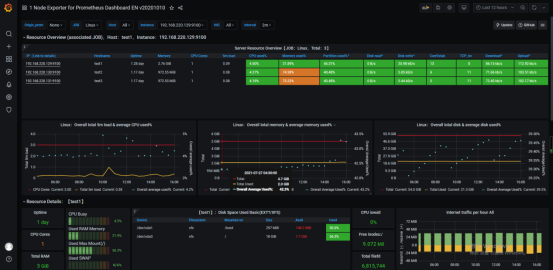
Grafana模板导入
下载模板
https://grafana.com/grafana/dashboards/11074
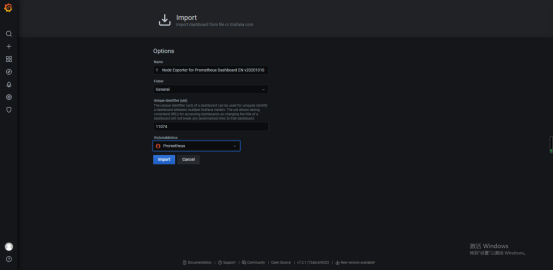
在grafana中导入dashboard

安装alertmanager
下载安装包并配置
下载地址:
https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
tar -xzvf alertmanager-0.21.0.linux-amd64.tar.gz -C /opt ln -s /opt/alertmanager-0.21.0.linux-amd64 /opt/alertmanager vim /opt/alertmanager/conf/alertmanager.yml global: smtp_smarthost: smtp.exmail.xxx.com:465 # 发件人邮箱smtp地址 smtp_auth_username: xxxx@xxx.com # 发件人邮箱账号 smtp_from: xxx@xxx.com # 发件人邮箱账号 smtp_auth_password: xxxxxx # 发件人邮箱密码(邮箱授权码) resolve_timeout: 5m smtp_require_tls: false route: # group_by: ['alertname'] # 报警分组依据 group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知 group_interval: 10s # 在发送新警报前的等待时间 repeat_interval: 1m # 发送重复警报的周期 对于email配置中多频繁 receiver: 'email' receivers: - name: email email_configs: - send_resolved: true to: xxx@xxx.com # 收件人邮箱账号
设置alertmanager系统服务,并配置开机启动
vim /usr/lib/systemd/system/alertmanager.service [Unit] Description=Prometheus Documentation=https://prometheus.io/ After=network.target [Service] Type=simple User=prometheus ExecStart=/opt/alertmanager/alertmanager --config.file=/opt/alertmanager/conf/alertmanager.yml --storage.path=/opt/alertmanager/data Restart=on-failure [Install] WantedBy=multi-user.target
设置开机启动
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
systemctl status alertmanager.service
prometheus配置
在prometheus目录下编辑报警模版system_rules.yml,添加一些自定义报警项。
groups: - name: Host rules: - alert: 主机状态报警 expr: up == 0 for: 1m labels: serverity: high annotations: summary: "{{$labels.instance}}:服务器宕机" description: "{{$labels.instance}}:服务器延时超过5分钟" - alert: CPU报警 expr: 100 * (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) > 90 for: 1m labels: serverity: middle annotations: summary: "{{$labels.instance}}: High CPU Usage Detected" description: "{{$labels.instance}}: CPU usage is {{$value}}, above 90%" - alert: 内存报警 expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 85 for: 1m labels: serverity: high annotations: summary: "{{$labels.instance}}: High Memory Usage Detected" description: "{{$labels.instance}}: Memory Usage i{{ $value }}, above 85%" - alert: 磁盘报警 expr: 100 * (node_filesystem_size_bytes{fstype=~"xfs|ext4"} - node_filesystem_avail_bytes) / node_filesystem_size_bytes > 90 for: 1m labels: serverity: middle annotations: summary: "{{$labels.instance}}: High Disk Usage Detected" description: "{{$labels.instance}}, mountpoint {{$labels.mountpoint}}: Disk Usage is {{ $value }}, above 90%" - alert: IO报警 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60 for: 1m labels: serverity: high annotations: summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})" - alert: 网络报警 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 1m labels: serverity: high annotations: summary: "{{$labels.mountpoint}} 流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话报警 expr: node_netstat_Tcp_CurrEstab > 1000 for: 1m labels: serverity: high annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
在prometheus目录下编辑prometheus的配置文件,将监控的配置信息添加到prometheus.yml。如下图所示:

重启Prometheus加载配置
systemctl restart prometheus.service
访问验证:http://192.168.220.129:9090/alerts

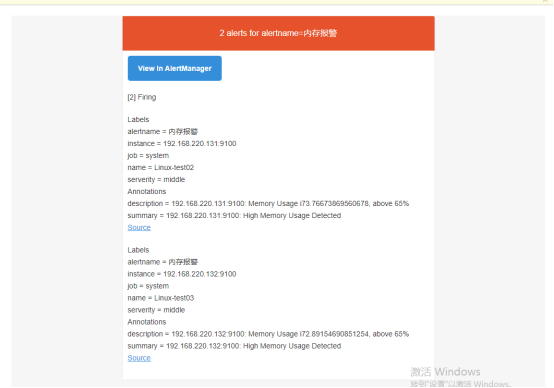
验证邮件报警
登陆prometheus的web页面,查看报警信息。
浏览器输入Prometheus_IP:9090 ,可以看到各个报警项的状态。


邮箱验证报警邮件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号