
消息中间件(十三)-----kafka集群、kafka入门demo
硬件配置对Kafka性能的影响
磁盘吞吐量/磁盘容量
磁盘吞吐量会影响生产者的性能。因为生产者的消息必须被提交到服务器保存,大多数的客户端都会一直等待,直到至少有一个服务器确认消息已经成功提交为止。也就是说,磁盘写入速度越快,生成消息的延迟就越低。
磁盘容量的大小,则主要看需要保存的消息数量。如果每天收到1TB的数据,并保留7天,那么磁盘就需要7TB的数据。
内存
Kafka本身并不需要太大内存,内存则主要是影响消费者性能。在大多数业务情况下,消费者消费的数据一般会从内存中获取,这比在磁盘上读取肯定要快的多。
网络
网络吞吐量决定了Kafka能够处理的最大数据流量。
CPU
Kafka对cpu的要求不高,主要是用在对消息解压和压缩上。所以cpu的性能不是在使用Kafka的首要考虑因素。
Kafka的集群
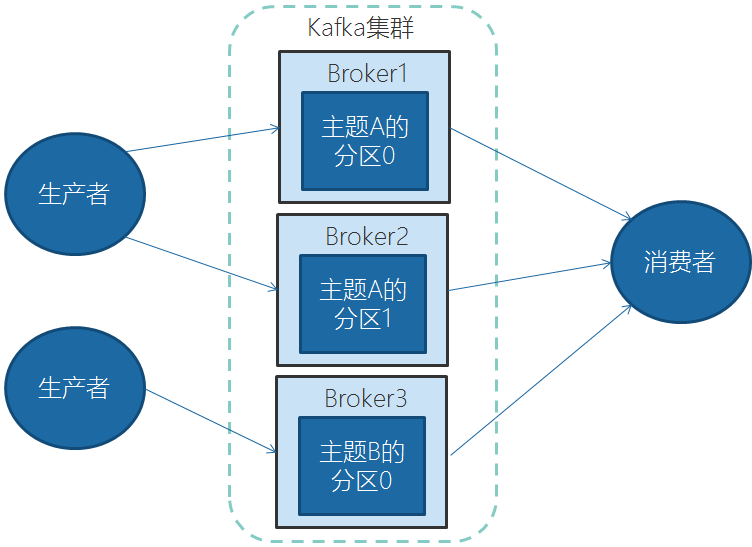
为何需要Kafka集群
本地开发,一台Kafka足够使用。在实际生产中,集群可以跨服务器进行负载均衡,再则可以使用复制功能来避免单独故障造成的数据丢失。同时集群可以提供高可用性。
如何估算Kafka集群中Broker的数量
要估量以下几个因素:
需要多少磁盘空间保留数据,和每个broker上有多少空间可以用。比如,如果一个集群有10TB的数据需要保留,而每个broker可以存储2TB,那么至少需要5个broker。如果启用了数据复制,则还需要一倍的空间,那么这个集群需要10个broker。
集群处理请求的能力。如果因为磁盘吞吐量和内存不足造成性能问题,可以通过扩展broker来解决。
Broker如何加入Kafka集群
非常简单,只需要两个参数。第一,配置zookeeper.connect,第二,为新增的broker设置一个集群内的唯一性id。
第一个Kafka程序
生产者发送消息
必选属性
创建生产者对象时有三个属性必须指定。
bootstrap.servers
该属性指定broker的地址清单,地址的格式为host:port。清单里不需要包含所有的broker地址,生产者会从给定的broker里查询其他broker的信息。不过最少提供2个broker的信息,一旦其中一个宕机,生产者仍能连接到集群上。
key.serializer
生产者接口允许使用参数化类型,可以把Java对象作为键和值传broker,但是broker希望收到的消息的键和值都是字节数组,所以,必须提供将对象序列化成字节数组的序列化器。key.serializer必须设置为实现org.apache.kafka.common.serialization.Serializer的接口类,Kafka的客户端默认提供了ByteArraySerializer,IntegerSerializer, StringSerializer,也可以实现自定义的序列化器。
value.serializer
同 key.serializer。
HelloKafkaProducer
package cn.enjoyedu.hellokafka; import cn.enjoyedu.config.BusiConst; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class HelloKafkaProducer { public static void main(String[] args) { Properties properties = new Properties(); properties.put("bootstrap.servers","127.0.0.1:9092"); properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties); try { ProducerRecord<String,String> record; try { record = new ProducerRecord<String,String>(BusiConst.HELLO_TOPIC, "teacher02","lison"); producer.send(record); System.out.println("message is sent."); } catch (Exception e) { e.printStackTrace(); } } finally { producer.close(); } } }
BusiConst
package cn.enjoyedu.config; public class BusiConst { public static final String HELLO_TOPIC = "hello-topic-12"; public static final int CONCURRENT_PARTITIONS_COUNT = 2; public static final String CONCURRENT_USER_INFO_TOPIC = "concurrent-test"; public static final String SELF_SERIAL_TOPIC = "self-serial"; public static final String SELF_PARTITION_TOPIC = "self-partition-test"; public static final String CONSUMER_GROUP_TOPIC = "consumer-group-test"; public static final String CONSUMER_GROUP_A = "groupA"; public static final String CONSUMER_GROUP_B = "groupB"; public static final String CONSUMER_COMMIT_TOPIC = "simple"; public static final String REBALANCE_TOPIC = "rebalance-topic-three-part"; }
消费者接受消息
必选参数
bootstrap.servers、key.serializer、value.serializer含义同生产者
group.id
并非完全必需,它指定了消费者属于哪一个群组,但是创建不属于任何一个群组的消费者并没有问题。
HelloKafkaConsumer
package cn.enjoyedu.hellokafka; import cn.enjoyedu.config.BusiConst; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.util.Collections; import java.util.Properties; public class HelloKafkaConsumer { public static void main(String[] args) { Properties properties = new Properties(); properties.put("bootstrap.servers","127.0.0.1:9092"); properties.put("key.deserializer", StringDeserializer.class); properties.put("value.deserializer", StringDeserializer.class); properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test1"); KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties); try { consumer.subscribe(Collections.singletonList(BusiConst.HELLO_TOPIC)); while(true){ ConsumerRecords<String, String> records = consumer.poll(500); for(ConsumerRecord<String, String> record:records){ System.out.println(String.format("topic:%s,分区:%d,偏移量:%d," + "key:%s,value:%s",record.topic(),record.partition(), record.offset(),record.key(),record.value())); //do my work } } } finally { consumer.close(); } } }
Kafka的生产者
生产者发送消息的基本流程

从创建一个ProducerRecord 对象开始, Producer Record 对象需要包含目标主题和要发送的内容。我们还可以指定键或分区。在发送ProducerReco rd 对象时,生产者要先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。
接下来,数据被传给分区器。如果之前在Producer Record 对象里指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。如果没有指定分区,那么分区器会根据Producer Record对象的键来选择一个分区。选好分区以后,生产者就知道该往哪个主题和分区发送这条记录了。紧接着,这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的broker 上。
服务器在收到这些消息时会返回一个响应。如果消息成功写入Kafka ,就返回一个RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。如果写入失败, 则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。
使用Kafka生产者
三种发送方式
我们通过生成者的send方法进行发送。send方法会返回一个包含RecordMetadata的Future对象。RecordMetadata里包含了目标主题,分区信息和消息的偏移量。
发送并忘记
忽略send方法的返回值,不做任何处理。大多数情况下,消息会正常到达,而且生产者会自动重试,但有时会丢失消息。
同步非阻塞发送
获得send方法返回的Future对象,在合适的时候调用Future的get方法。
KafkaConst
package cn.enjoyedu.config; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.Deserializer; import org.apache.kafka.common.serialization.Serializer; import java.util.HashMap; import java.util.Map; import java.util.Properties; public class KafkaConst { /*生产者和消费者共用配置常量*/ public static final String LOCAL_BROKER = "127.0.0.1:9092"; public static final String BROKER_LIST = "127.0.0.1:9093,127.0.0.1:9094,127.0.0.1:9095"; /*======================生产者配置============================*/ public static Properties producerConfig(Class<? extends Serializer> keySerializeClazz, Class<? extends Serializer> valueSerializeClazz){ Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,LOCAL_BROKER); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,keySerializeClazz); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,valueSerializeClazz); return properties; } /*======================消费者配置========================*/ public static Properties consumerConfig(String groupId, Class<? extends Deserializer> keyDeserializeClazz, Class<? extends Deserializer> valueDeserializeClazz){ Properties properties = new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,LOCAL_BROKER); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializeClazz); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializeClazz); properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId); return properties; } public static Map<String,Object> consumerConfigMap(String groupId, Class<? extends Deserializer> keyDeserializeClazz, Class<? extends Deserializer> valueDeserializeClazz){ Map<String,Object> properties = new HashMap<String, Object>(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,LOCAL_BROKER); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializeClazz); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializeClazz); properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId); return properties; } }
KafkaFutureProducer
package cn.enjoyedu.sendtype; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.serialization.StringSerializer; import java.util.concurrent.Future; /** * 类说明:发送消息--未来某个时候get发送结果 */ public class KafkaFutureProducer { private static KafkaProducer<String,String> producer = null; public static void main(String[] args) { /*消息生产者*/ producer = new KafkaProducer<String, String>(KafkaConst.producerConfig(StringSerializer.class, StringSerializer.class)); try { /*待发送的消息实例*/ ProducerRecord<String,String> record; try { record = new ProducerRecord<String,String>(BusiConst.HELLO_TOPIC,"teacher10","james"); Future<RecordMetadata> future = producer.send(record); System.out.println("do other sth"); RecordMetadata recordMetadata = future.get(); if(null!=recordMetadata){ System.out.println("offset:" + recordMetadata.offset() + "-" + "partition:" + recordMetadata.partition()); } } catch (Exception e) { e.printStackTrace(); } } finally { producer.close(); } } }
异步发送
实现接口org.apache.kafka.clients.producer.Callback,然后将实现类的实例作为参数传递给send方法。
KafkaAsynProducer
package cn.enjoyedu.sendtype; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.serialization.StringSerializer; /** * 类说明:发送消息--异步模式 */ public class KafkaAsynProducer { private static KafkaProducer<String,String> producer = null; public static void main(String[] args) { /*消息生产者*/ producer = new KafkaProducer<String, String>(KafkaConst.producerConfig(StringSerializer.class, StringSerializer.class)); /*待发送的消息实例*/ ProducerRecord<String,String> record; try { record = new ProducerRecord<String,String>(BusiConst.HELLO_TOPIC,"teacher14","deer"); producer.send(record, new Callback() { public void onCompletion(RecordMetadata metadata, Exception exception) { if(null!=exception){ exception.printStackTrace(); } if(null!=metadata){ System.out.println("offset:" + metadata.offset() + "-" + "partition:" + metadata.partition()); } } }); } finally { producer.close(); } } }
多线程下的生产者
KafkaProducer的实现是线程安全的,所以我们可以在多线程的环境下,安全的使用KafkaProducer的实例,如何节约资源的使用呢?
KafkaConProducer
package cn.enjoyedu.concurrent; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import cn.enjoyedu.vo.DemoUser; import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.serialization.StringSerializer; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * 类说明:多线程下使用生产者 */ public class KafkaConProducer { //发送消息的个数 private static final int MSG_SIZE = 1000; //负责发送消息的线程池 private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()); private static CountDownLatch countDownLatch = new CountDownLatch(MSG_SIZE); private static DemoUser makeUser(int id){ DemoUser demoUser = new DemoUser(id); String userName = "xiangxue_"+id; demoUser.setName(userName); return demoUser; } /*发送消息的任务*/ private static class ProduceWorker implements Runnable{ private ProducerRecord<String,String> record; private KafkaProducer<String,String> producer; public ProduceWorker(ProducerRecord<String, String> record, KafkaProducer<String, String> producer) { this.record = record; this.producer = producer; } public void run() { final String id = Thread.currentThread().getId() + "-" + System.identityHashCode(producer); try { producer.send(record, new Callback() { public void onCompletion(RecordMetadata metadata, Exception exception) { if(null!=exception){ exception.printStackTrace(); } if(null!=metadata){ System.out.println(id + "|" + String.format("偏移量:%s,分区:%s", metadata.offset(),metadata.partition())); } } }); System.out.println(id+":数据["+record+"]已发送。"); countDownLatch.countDown(); } catch (Exception e) { e.printStackTrace(); } } } public static void main(String[] args) { KafkaProducer<String,String> producer = new KafkaProducer<>(KafkaConst.producerConfig(StringSerializer.class, StringSerializer.class)); try { for(int i=0;i<MSG_SIZE;i++){ DemoUser demoUser = makeUser(i); ProducerRecord<String,String> record = new ProducerRecord<>(BusiConst.CONCURRENT_USER_INFO_TOPIC,null, System.currentTimeMillis(), demoUser.getId()+"", demoUser.toString()); executorService.submit(new ProduceWorker(record,producer)); } countDownLatch.await(); } catch (Exception e) { e.printStackTrace(); } finally { producer.close(); executorService.shutdown(); } } }
DemoUser
package cn.enjoyedu.vo; @Data @ToString public class DemoUser { private int id; private String name; public DemoUser(int id) { this.id = id; } public DemoUser(int id, String name) { this.id = id; this.name = name; } }
KafkaConConsumer
package cn.enjoyedu.concurrent; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.util.Collections; import java.util.Map; import java.util.Properties; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * 类说明:多线程下正确的使用消费者,需要记住,一个线程一个消费者 */ public class KafkaConConsumer { private static ExecutorService executorService = Executors.newFixedThreadPool(BusiConst.CONCURRENT_PARTITIONS_COUNT); private static class ConsumerWorker implements Runnable{ private KafkaConsumer<String,String> consumer; public ConsumerWorker(Map<String, Object> config, String topic) { Properties properties = new Properties(); properties.putAll(config); this.consumer = new KafkaConsumer<String, String>(properties); consumer.subscribe(Collections.singletonList(topic)); } public void run() { final String id = Thread.currentThread().getId() + "-" + System.identityHashCode(consumer); try { while(true){ ConsumerRecords<String, String> records = consumer.poll(500); for(ConsumerRecord<String, String> record:records){ System.out.println(id+"|"+String.format("主题:%s,分区:%d,偏移量:%d," + "key:%s,value:%s", record.topic(),record.partition(), record.offset(),record.key(),record.value())); //do our work } } } finally { consumer.close(); } } } public static void main(String[] args) { /*消费配置的实例*/ Map<String, Object> config = KafkaConst.consumerConfigMap("concurrent", StringDeserializer.class, StringDeserializer.class); for(int i = 0; i<BusiConst.CONCURRENT_PARTITIONS_COUNT; i++){ executorService.submit(new ConsumerWorker(config, BusiConst.CONCURRENT_USER_INFO_TOPIC)); } } }
更多发送配置
生产者有很多属性可以设置,大部分都有合理的默认值,无需调整。有些参数可能对内存使用,性能和可靠性方面有较大影响。可以参考org.apache.kafka.clients.producer包下的ProducerConfig类。
acks:
指定了必须要有多少个分区副本收到消息,生产者才会认为写入消息是成功的,这个参数对消息丢失的可能性有重大影响。
acks=0:生产者在写入消息之前不会等待任何来自服务器的响应,容易丢消息,但是吞吐量高。
acks=1:只要集群的首领节点收到消息,生产者会收到来自服务器的成功响应。如果消息无法到达首领节点(比如首领节点崩溃,新首领没有选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新首领,消息还是会丢失。默认使用这个配置。
acks=all:只有当所有参与复制的节点都收到消息,生产者才会收到一个来自服务器的成功响应。延迟高。
buffer.memory
设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果数据产生速度大于向broker发送的速度,导致生产者空间不足,producer会阻塞或者抛出异常。缺省33554432 (32M)
max.block.ms
指定了在调用send()方法或者使用partitionsFor()方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到max.block.ms时,生产者会抛出超时异常。缺省60000ms
retries
发送失败时,指定生产者可以重发消息的次数。默认情况下,生产者在每次重试之间等待100ms,可以通过参数retry.backoff.ms参数来改变这个时间间隔。缺省0
receive.buffer.bytes和send.buffer.bytes
指定TCP socket接受和发送数据包的缓存区大小。如果它们被设置为-1,则使用操作系统的默认值。如果生产者或消费者处在不同的数据中心,那么可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。缺省102400
batch.size
当多个消息被发送同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次内存被填满后,批次里的所有消息会被发送出去。但是生产者不一定都会等到批次被填满才发送,半满甚至只包含一个消息的批次也有可能被发送。缺省16384(16k)
linger.ms
指定了生产者在发送批次前等待更多消息加入批次的时间。它和batch.size以先到者为先。也就是说,一旦我们获得消息的数量够batch.size的数量了,他将会立即发送而不顾这项设置,然而如果我们获得消息字节数比batch.size设置要小的多,我们需要“linger”特定的时间以获取更多的消息。这个设置默认为0,即没有延迟。设定linger.ms=5,例如,将会减少请求数目,但是同时会增加5ms的延迟,但也会提升消息的吞吐量。
compression.type
producer用于压缩数据的压缩类型。默认是无压缩。正确的选项值是none、gzip、snappy。压缩最好用于批量处理,批量处理消息越多,压缩性能越好。snappy占用cpu少,提供较好的性能和可观的压缩比,如果比较关注性能和网络带宽,用这个。如果带宽紧张,用gzip,会占用较多的cpu,但提供更高的压缩比。
client.id
当向server发出请求时,这个字符串会发送给server。目的是能够追踪请求源头,以此来允许ip/port许可列表之外的一些应用可以发送信息。这项应用可以设置任意字符串,因为没有任何功能性的目的,除了记录和跟踪。
max.in.flight.requests.per.connection
指定了生产者在接收到服务器响应之前可以发送多个消息,值越高,占用的内存越大,当然也可以提升吞吐量。发生错误时,可能会造成数据的发送顺序改变,默认是5 (修改)。
如果需要保证消息在一个分区上的严格顺序,这个值应该设为1。不过这样会严重影响生产者的吞吐量。
request.timeout.ms
客户端将等待请求的响应的最大时间,如果在这个时间内没有收到响应,客户端将重发请求;超过重试次数将抛异常
metadata.fetch.timeout.ms
是指我们所获取的一些元数据的第一个时间数据。元数据包含:topic,host,partitions。此项配置是指当等待元数据fetch成功完成所需要的时间,否则会跑出异常给客户端
timeout.ms
此配置选项控制broker等待副本确认的最大时间。如果确认的请求数目在此时间内没有实现,则会返回一个错误。这个超时限制是以server端度量的,没有包含请求的网络延迟。这个参数和acks的配置相匹配。
max.request.size
控制生产者发送请求最大大小。假设这个值为1M,如果一个请求里只有一个消息,那这个消息不能大于1M,如果一次请求是一个批次,该批次包含了1000条消息,那么每个消息不能大于1KB。注意:broker具有自己对消息记录尺寸的覆盖,如果这个尺寸小于生产者的这个设置,会导致消息被拒绝。
顺序保证
Kafka 可以保证同一个分区里的消息是有序的。也就是说,如果生产者一定的顺序发送消息, broker 就会按照这个顺序把它们写入分区,消费者也会按照同样的顺序读取它们。在某些情况下, 顺序是非常重要的。例如,往一个账户存入100 元再取出来,这个与先取钱再存钱是截然不同的!不过,有些场景对顺序不是很敏感。
如果把retires设为非零整数,同时把max.in.flight.request.per.connection设为比1 大的数,那么,如果第一个批次消息写入失败,而第二个批次写入成功, broker 会重试写入第一个批次。如果此时第一个批次也写入成功,那么两个批次的顺序就反过来了。
一般来说,如果某些场景要求消息是有序的,那么消息是否写入成功也是很关键的,所以不建议把retires设为0 。可以把max.in.flight.request.per.connection 设为1,这样在生产者尝试发送第一批消息时,就不会有其他的消息发送给broker 。不过这样会严重影响生产者的吞吐量,所以只有在对消息的顺序有严格要求的情况下才能这么做。
序列化
创建生产者对象必须指定序列化器,默认的序列化器并不能满足我们所有的场景。我们完全可以自定义序列化器。只要实现org.apache.kafka.common.serialization.Serializer接口即可。
SelfSerialProducer
package cn.enjoyedu.selfserial; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import cn.enjoyedu.vo.DemoUser; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; /** * 类说明:发送消息--未来某个时候get发送结果 */ public class SelfSerialProducer { private static KafkaProducer<String,DemoUser> producer = null; public static void main(String[] args) { /*消息生产者*/ producer = new KafkaProducer<>(KafkaConst.producerConfig(StringSerializer.class, SelfSerializer.class)); try { /*待发送的消息实例*/ ProducerRecord<String,DemoUser> record; try { record = new ProducerRecord<>(BusiConst.SELF_SERIAL_TOPIC,"user01", new DemoUser(1,"mark")); producer.send(record); System.out.println("sent "); } catch (Exception e) { e.printStackTrace(); } } finally { producer.close(); } } }
SelfSerializer
package cn.enjoyedu.selfserial; import cn.enjoyedu.vo.DemoUser; import org.apache.kafka.common.errors.SerializationException; import org.apache.kafka.common.serialization.Serializer; import java.nio.ByteBuffer; import java.util.Map; public class SelfSerializer implements Serializer<DemoUser> { public void configure(Map<String, ?> configs, boolean isKey) { //do nothing } public byte[] serialize(String topic, DemoUser data) { try { byte[] name; int nameSize; if(data==null){ return null; } if(data.getName()!=null){ name = data.getName().getBytes("UTF-8"); //字符串的长度 nameSize = data.getName().length(); }else{ name = new byte[0]; nameSize = 0; } /*id的长度4个字节,字符串的长度描述4个字节, 字符串本身的长度nameSize个字节*/ ByteBuffer buffer = ByteBuffer.allocate(4+4+nameSize); buffer.putInt(data.getId());//4 buffer.putInt(nameSize);//4 buffer.put(name);//nameSize return buffer.array(); } catch (Exception e) { throw new SerializationException("Error serialize DemoUser:"+e); } } public void close() { //do nothing } }
SelfSerialConsumer
package cn.enjoyedu.selfserial; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import cn.enjoyedu.vo.DemoUser; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; import java.util.Collections; public class SelfSerialConsumer { private static KafkaConsumer<String,DemoUser> consumer = null; public static void main(String[] args) { /*消息消费者*/ consumer = new KafkaConsumer<String, DemoUser>(KafkaConst.consumerConfig("selfserial", StringDeserializer.class, SelfDeserializer.class)); try { consumer.subscribe(Collections.singletonList(BusiConst.SELF_SERIAL_TOPIC)); while(true){ ConsumerRecords<String, DemoUser> records = consumer.poll(500); for(ConsumerRecord<String, DemoUser> record:records){ System.out.println(String.format("主题:%s,分区:%d,偏移量:%d,key:%s,value:%s", record.topic(),record.partition(),record.offset(), record.key(),record.value())); //do our work } } } finally { consumer.close(); } } }
SelfDeserializer
package cn.enjoyedu.selfserial; import cn.enjoyedu.vo.DemoUser; import org.apache.kafka.common.errors.SerializationException; import org.apache.kafka.common.serialization.Deserializer; import java.nio.ByteBuffer; import java.util.Map; /** * 类说明:反序列化器 */ public class SelfDeserializer implements Deserializer<DemoUser> { public void configure(Map<String, ?> configs, boolean isKey) { //do nothing } public DemoUser deserialize(String topic, byte[] data) { try { if(data==null){ return null; } if(data.length<8){ throw new SerializationException("Error data size."); } ByteBuffer buffer = ByteBuffer.wrap(data); int id; String name; int nameSize; id = buffer.getInt(); nameSize = buffer.getInt(); byte[] nameByte = new byte[nameSize]; buffer.get(nameByte); name = new String(nameByte,"UTF-8"); return new DemoUser(id,name); } catch (Exception e) { throw new SerializationException("Error Deserializer DemoUser."+e); } } public void close() { //do nothing } }
自定义序列化需要考虑的问题
自定义序列化容易导致程序的脆弱性。举例,在我们上面的实现里,我们有多种类型的消费者,每个消费者对实体字段都有各自的需求,比如,有的将字段变更为long型,有的会增加字段,这样会出现新旧消息的兼容性问题。特别是在系统升级的时候,经常会出现一部分系统升级,其余系统被迫跟着升级的情况。
解决这个问题,可以考虑使用自带格式描述以及语言无关的序列化框架。比如Protobuf,或者Kafka官方推荐的Apache Avro。
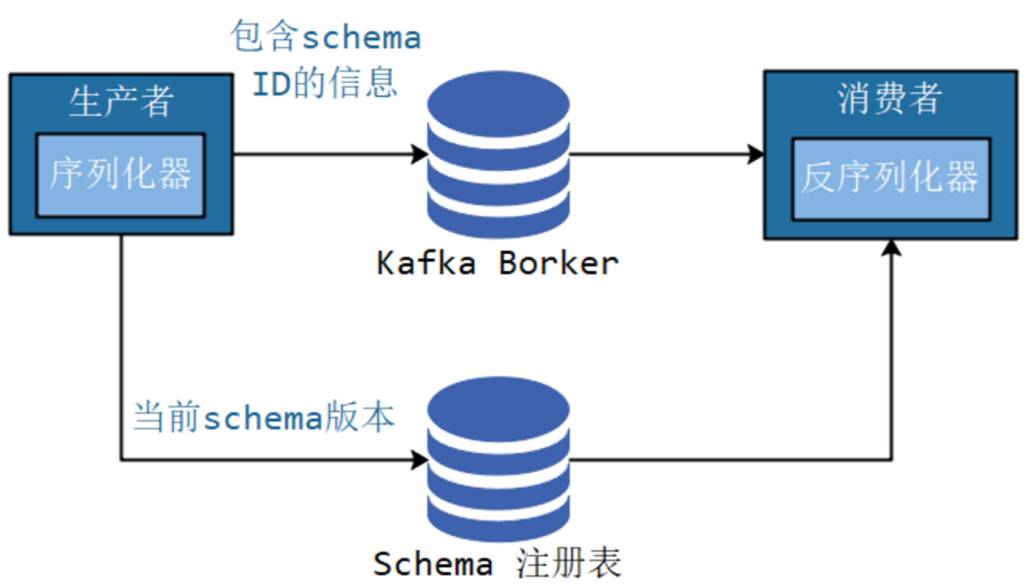
Avro会使用一个JSON文件作为schema来描述数据,Avro在读写时会用到这个schema,可以把这个schema内嵌在数据文件中。这样,不管数据格式如何变动,消费者都知道如何处理数据。
但是内嵌的消息,自带格式,会导致消息的大小不必要的增大,消耗了资源。我们可以使用schema注册表机制,将所有写入的数据用到的schema保存在注册表中,然后在消息中引用schema的标识符,而读取的数据的消费者程序使用这个标识符从注册表中拉取schema来反序列化记录。
注意:Kafka本身并不提供schema注册表,需要借助第三方,现在已经有很多的开源实现,比如Confluent Schema Registry,可以从GitHub上获取。如何使用参考如下网址:
https://cloud.tencent.com/developer/article/1336568
分区
我们在新增ProducerRecord对象中可以看到,ProducerRecord包含了目标主题,键和值,Kafka的消息都是一个个的键值对。键可以设置为默认的null。
键的主要用途有两个:一,用来决定消息被写往主题的哪个分区,拥有相同键的消息将被写往同一个分区,二,还可以作为消息的附加消息。
如果键值为null,并且使用默认的分区器,分区器使用轮询算法将消息均衡地分布到各个分区上。
如果键不为空,并且使用默认的分区器,Kafka对键进行散列(Kafka自定义的散列算法,具体算法原理不知),然后根据散列值把消息映射到特定的分区上。很明显,同一个键总是被映射到同一个分区。但是只有不改变主题分区数量的情况下,键和分区之间的映射才能保持不变,一旦增加了新的分区,就无法保证了,所以如果要使用键来映射分区,那就要在创建主题的时候把分区规划好,而且永远不要增加新分区。
自定义分区器
某些情况下,数据特性决定了需要进行特殊分区,比如电商业务,北京的业务量明显比较大,占据了总业务量的20%,我们需要对北京的订单进行单独分区处理,默认的散列分区算法不合适了, 我们就可以自定义分区算法,对北京的订单单独处理,其他地区沿用散列分区算法。或者某些情况下,我们用value来进行分区。
SelfPartitionProducer
package cn.enjoyedu.selfpartition; import cn.enjoyedu.config.BusiConst; import cn.enjoyedu.config.KafkaConst; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; import java.util.concurrent.Future; public class SelfPartitionProducer { private static KafkaProducer<String,String> producer = null; public static void main(String[] args) { /*消息生产者*/ Properties properties = KafkaConst.producerConfig(StringSerializer.class, StringSerializer.class); /*使用自定义的分区器*/ properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "cn.enjoyedu.selfpartition.SelfPartitioner"); producer = new KafkaProducer<>(properties); try { /*待发送的消息实例*/ ProducerRecord<String,String> record; try { record = new ProducerRecord<>(BusiConst.SELF_PARTITION_TOPIC,"teacher01", "mark"); Future<RecordMetadata> future = producer.send(record); System.out.println("Do other something"); RecordMetadata recordMetadata = future.get(); if(null!=recordMetadata){ System.out.println(String.format("偏移量:%s,分区:%s", recordMetadata.offset(), recordMetadata.partition())); } } catch (Exception e) { e.printStackTrace(); } } finally { producer.close(); } } }
SelfPartitioner
package cn.enjoyedu.selfpartition; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import org.apache.kafka.common.PartitionInfo; import java.util.List; import java.util.Map; /** * 类说明:自定义分区器,以value值进行分区 */ public class SelfPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic); int num = partitionInfos.size(); int parId = ((String)value).hashCode()%num; return parId; } public void close() { //do nothing } public void configure(Map<String, ?> configs) { //do nothing } }
Kafka的消费者
消费者和消费者群组、分区再均衡
消费者的含义,同一般消息中间件中消费者的概念。在高并发的情况下,生产者产生消息的速度是远大于消费者消费的速度,单个消费者很可能会负担不起,此时有必要对消费者进行横向伸缩,于是我们可以使用多个消费者从同一个主题读取消息,对消息进行分流。
消费者群组
Kafka里消费者从属于消费者群组,一个群组里的消费者订阅的都是同一个主题,每个消费者接收主题一部分分区的消息。
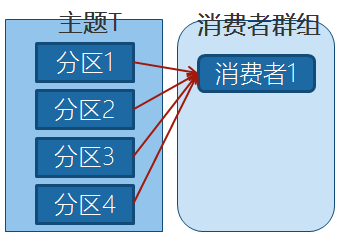
如上图,主题T有4个分区,群组中只有一个消费者,则该消费者将收到主题T1全部4个分区的消息。
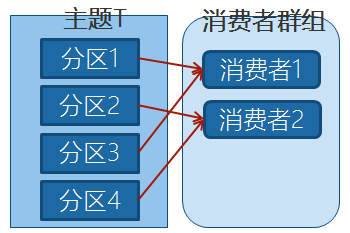
如上图,在群组中增加一个消费者2,那么每个消费者将分别从两个分区接收消息,上图中就表现为消费者1接收分区1和分区3的消息,消费者2接收分区2和分区4的消息。
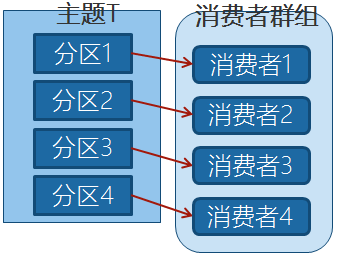
如上图,在群组中有4个消费者,那么每个消费者将分别从1个分区接收消息。

但是,当我们增加更多的消费者,超过了主题的分区数量,就会有一部分的消费者被闲置,不会接收到任何消息。
往消费者群组里增加消费者是进行横向伸缩能力的主要方式。所以我们有必要为主题设定合适规模的分区,在负载均衡的时候可以加入更多的消费者。但是要记住,一个群组里消费者数量超过了主题的分区数量,多出来的消费者是没有用处的。
如果是多个应用程序,需要从同一个主题中读取数据,只要保证每个应用程序有自己的消费者群组就行了。如下图所示:
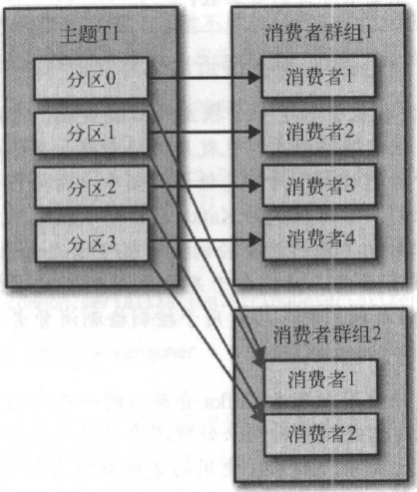
分区再均衡
当消费者群组里的消费者发生变化,或者主题里的分区发生了变化,都会导致再均衡现象的发生。从前面的知识中,我们知道,Kafka中,存在着消费者对分区所有权的关系,
这样无论是消费者变化,比如增加了消费者,新消费者会读取原本由其他消费者读取的分区,消费者减少,原本由它负责的分区要由其他消费者来读取,增加了分区,哪个消费者来读取这个新增的分区,这些行为,都会导致分区所有权的变化,这种变化就被称为再均衡。
再均衡对Kafka很重要,这是消费者群组带来高可用性和伸缩性的关键所在。不过一般情况下,尽量减少再均衡,因为再均衡期间,消费者是无法读取消息的,会造成整个群组一小段时间的不可用。
消费者通过向称为群组协调器的broker(不同的群组有不同的协调器)发送心跳来维持它和群组的从属关系以及对分区的所有权关系。如果消费者长时间不发送心跳,群组协调器认为它已经死亡,就会触发一次再均衡。
在0.10.1及以后的版本中,心跳由单独的线程负责,相关的控制参数为max.poll.interval.ms。
消费者分区分配的过程
消费者要加入群组时,会向群组协调器发送一个JoinGroup请求,第一个加入群主的消费者成为群主,群主会获得群组的成员列表,并负责给每一个消费者分配分区。分配完毕后,群组把分配情况发送给群组协调器,协调器再把这些信息发送给所有的消费者,每个消费者只能看到自己的分配信息,只有群主知道群组里所有消费者的分配信息。这个过程在每次再均衡时都会发生。
使用Kafka消费者
订阅
创建消费者后,使用subscribe()方法订阅主题,这个方法接受一个主题列表为参数,也可以接受一个正则表达式为参数;正则表达式同样也匹配多个主题。如果新创建了新主题,并且主题名字和正则表达式匹配,那么会立即触发一次再均衡,消费者就可以读取新添加的主题。比如,要订阅所有和test相关的主题,可以subscribe(“tets.*”)
轮询
为了不断的获取消息,我们要在循环中不断的进行轮询,也就是不停调用poll方法。
poll方法的参数为超时时间,控制poll方法的阻塞时间,它会让消费者在指定的毫秒数内一直等待broker返回数据。poll方法将会返回一个记录(消息)列表,每一条记录都包含了记录所属的主题信息,记录所在分区信息,记录在分区里的偏移量,以及记录的键值对。
poll方法不仅仅只是获取数据,在新消费者第一次调用时,它会负责查找群组,加入群组,接受分配的分区。如果发生了再均衡,整个过程也是在轮询期间进行的。
多线程下的消费者
KafkaConsumer的实现不是线程安全的,所以我们在多线程的环境下,使用KafkaConsumer的实例要小心,应该每个消费数据的线程拥有自己的KafkaConsumer实例,如何使用?参见代码,模块kafka-no-spring下包concurrent中
消费者配置
消费者有很多属性可以设置,大部分都有合理的默认值,无需调整。有些参数可能对内存使用,性能和可靠性方面有较大影响。可以参考org.apache.kafka.clients.consumer包下ConsumerConfig类。
fetch.min.bytes
每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。缺省为1个字节。多消费者下,可以设大这个值,以降低broker的工作负载
fetch.wait.max.ms
如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在应答fetch请求之前,server会阻塞的最大时间。缺省为500个毫秒。和上面的fetch.min.bytes结合起来,要么满足数据的大小,要么满足时间,就看哪个条件先满足。
max.partition.fetch.bytes
指定了服务器从每个分区里返回给消费者的最大字节数,默认1MB。假设一个主题有20个分区和5个消费者,那么每个消费者至少要有4MB的可用内存来接收记录,而且一旦有消费者崩溃,这个内存还需更大。注意,这个参数要比服务器的message.max.bytes更大,否则消费者可能无法读取消息。
session.timeout.ms
如果consumer在这段时间内没有发送心跳信息,则它会被认为挂掉了。默认3秒。
auto.offset.reset
消费者在读取一个没有偏移量的分区或者偏移量无效的情况下,如何处理。默认值是latest,从最新的记录开始读取,另一个值是earliest,表示消费者从起始位置读取分区的记录。
注意:默认值是latest,意思是说,在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录),可以先启动生产者,再启动消费者,观察到这种情况。观察代码,在模块kafka-no-spring下包hellokafka中。
enable .auto.commit
默认值true,表明消费者是否自动提交偏移。为了尽量避免重复数据和数据丢失,可以改为false,自行控制何时提交。
partition.assignment.strategy
分区分配给消费者的策略。系统提供两种策略。默认为Range。允许自定义策略。
Range
把主题的连续分区分配给消费者。例如,有主题T1和T2,各有3个分区,消费者C1和C2,则可能的分配形式为:
C1: T1(0,1),T2(0,,1)
C2: T1(2),T2(2)
RoundRobin
把主题的分区循环分配给消费者。例如,有主题T1和T2,各有3个分区,消费者C1和C2,则可能的分配形式为:
C1: T1(0,2),T2(1)
C2: T1(1),T2(0,2)
自定义策略
extends 类AbstractPartitionAssignor,然后在消费者端增加参数:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, 类.class.getName());即可。
client.id
当向server发出请求时,这个字符串会发送给server。目的是能够追踪请求源头,以此来允许ip/port许可列表之外的一些应用可以发送信息。这项应用可以设置任意字符串,因为没有任何功能性的目的,除了记录和跟踪。
max.poll.records
控制每次poll方法返回的的记录数量。
receive.buffer.bytes和send.buffer.bytes
指定TCP socket接受和发送数据包的缓存区大小。如果它们被设置为-1,则使用操作系统的默认值。如果生产者或消费者处在不同的数据中心,那么可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。

posted on 2020-06-03 23:11 阿里-马云的学习笔记 阅读(555) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号