
redis教程(三)-----redis缓存雪崩、缓存穿透、缓存预热
缓存雪崩
概念
缓存雪崩是由于原有缓存失效(过期),新缓存未到期间。所有请求都去查询数据库,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决方案
加锁排队
一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
public object GetProductListNew() { const int cacheTime = 30; const string cacheKey = "product_list"; const string lockKey = cacheKey; var cacheValue = CacheHelper.Get(cacheKey); if (cacheValue != null) { return cacheValue; } else { lock (lockKey) { cacheValue = CacheHelper.Get(cacheKey); if (cacheValue != null) { return cacheValue; } else { cacheValue = GetProductListFromDB(); //这里一般是 sql查询数据。 CacheHelper.Add(cacheKey, cacheValue, cacheTime); } } return cacheValue; } }
缓存标记
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法。还有一个解决办法解决方案是:给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
public object GetProductListNew() { const int cacheTime = 30; const string cacheKey = "product_list"; //缓存标记。 const string cacheSign = cacheKey + "_sign"; var sign = CacheHelper.Get(cacheSign); //获取缓存值 var cacheValue = CacheHelper.Get(cacheKey); if (sign != null) { return cacheValue; //未过期,直接返回。 } else { CacheHelper.Add(cacheSign, "1", cacheTime); ThreadPool.QueueUserWorkItem((arg) => { cacheValue = GetProductListFromDB(); //这里一般是 sql查询数据。 CacheHelper.Add(cacheKey, cacheValue, cacheTime*2); //日期设缓存时间的2倍,用于脏读。 }); return cacheValue; } }
缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存。
缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
这样做后,就可以一定程度上提高系统吞吐量。
缓存穿透
1、空值缓存
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决的办法就是:如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
public object GetProductListNew() { const int cacheTime = 30; const string cacheKey = "product_list"; var cacheValue = CacheHelper.Get(cacheKey);if (cacheValue != null) { return cacheValue; } else { cacheValue = GetProductListFromDB(); //数据库查询不到,为空。 if (cacheValue == null) { cacheValue = string.Empty; //如果发现为空,设置个默认值,也缓存起来。 } CacheHelper.Add(cacheKey, cacheValue, cacheTime); return cacheValue; } }
把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
注:这种最好将缓存时间设置的短一些,因为恶意攻击时,会需要占用很多的内存,依赖于redis的剔除策略,降低对于内存的占用。另外缓存时间设置过长也会有一个问题,就是本来为空的数据存储层已经不为空了,当然这种也可以搭配主动更新的策略进行更新。
2、布隆过滤器拦截
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
a、布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
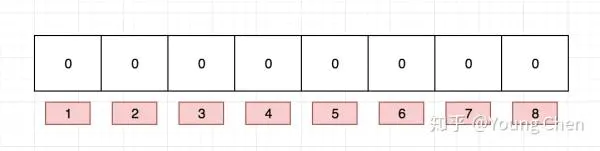
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
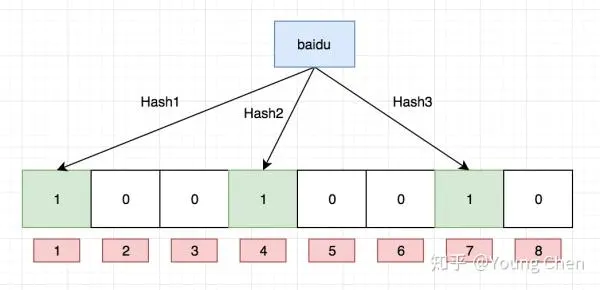
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
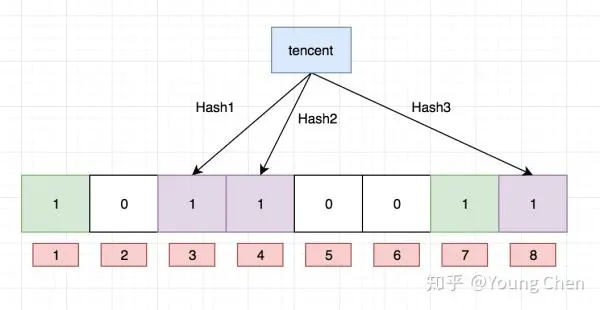
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
下面来看一个场景,一个推荐系统需要根据用户前一天的历史数据生成推荐内容,但是每一天公司会新增很多用户,所以他前一天的用户踪迹都是空的,因此可以将每天新增的这些用户做成布隆过滤器,这样每天进行推荐的时候,就可以过滤出一部分的新用户,一定程度上缓解了缓存穿透的现象。
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样避免,用户请求的时候,再去加载相关的数据。
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下。
2、数据量不大,可以在WEB系统启动的时候加载。
3、定时刷新缓存。
缓存更新
缓存中的数据通常都是有生命周期的,需要在指定时间后被删除或更新,这样可以保证缓存空间在一个可控的范围。
1、LRU/LFU/FIFO 算法剔除
使用场景:redis使用maxmemory-policy作为内存最大值,当redis中数据内存达到设置的这个值时,则会触发用户所配置的数据剔除策略,redis的默认剔除策略如下:
- volatile-lru:从已设置过期时间的内存数据集中挑选最近最少使用的数据 淘汰;
- volatile-ttl: 从已设置过期时间的内存数据集中挑选即将过期的数据 淘汰;
- volatile-random:从已设置过期时间的内存数据集中任意挑选数据 淘汰;
- allkeys-lru:从内存数据集中挑选最近最少使用的数据 淘汰;
- allkeys-random:从数据集中任意挑选数据 淘汰;
- no-enviction(驱逐):禁止驱逐数据。(默认淘汰策略。当redis内存数据达到maxmemory,在该策略下,直接返回OOM错误)

posted on 2019-06-11 23:44 阿里-马云的学习笔记 阅读(789) 评论(0) 编辑 收藏 举报

