
走进JDK(十一)------LinkedHashMap
概述
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap 对访问顺序也提供了相关支持。
原理
LinkedHashMap在HashMap结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。
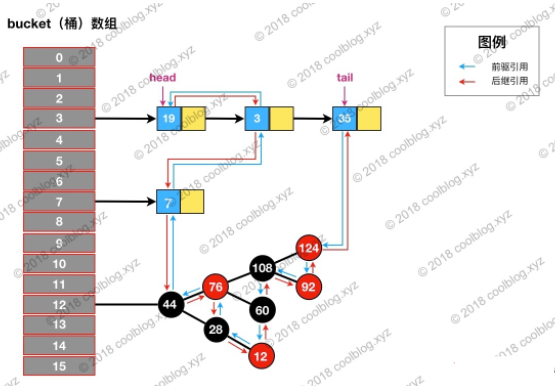
上图中,淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了。
Entry
在对核心内容展开分析之前,这里先插队分析一下键值对节点的继承体系。先来看看继承体系结构图:
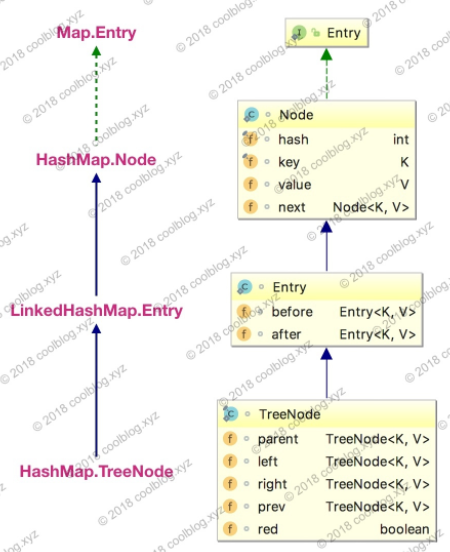
LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。
主要方法
1、put()------LinkedHashMap的put()与HashMap保持一致,区别在于newNode()。
// HashMap 中实现 public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } // HashMap 中实现 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) {...} // 通过节点 hash 定位节点所在的桶位置,并检测桶中是否包含节点引用 if ((p = tab[i = (n - 1) & hash]) == null) {...} else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) {...} else { // 遍历链表,并统计链表长度 for (int binCount = 0; ; ++binCount) { // 未在单链表中找到要插入的节点,将新节点接在单链表的后面 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) {...} break; } // 插入的节点已经存在于单链表中 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) {...} afterNodeAccess(e); // 回调方法,后续说明 return oldValue; } } ++modCount; if (++size > threshold) {...} afterNodeInsertion(evict); // 回调方法,后续说明 return null; } // HashMap 中实现 Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) { return new Node<>(hash, key, value, next); } // LinkedHashMap 中覆写 Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); // 将 Entry 接在双向链表的尾部 linkNodeLast(p); return p; } // LinkedHashMap 中实现 private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail; tail = p; // last 为 null,表明链表还未建立 if (last == null) head = p; else { // 将新节点 p 接在链表尾部 p.before = last; last.after = p; } }
2、remove()------LinkedHashMap的remove()与HashMap保持一致,区别在于afterNodeRemoval()。
// HashMap 中实现 public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } // HashMap 中实现 final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) {...} else { // 遍历单链表,寻找要删除的节点,并赋值给 node 变量 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) {...} // 将要删除的节点从单链表中移除 else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); // 调用删除回调方法进行后续操作 return node; } } return null; } // LinkedHashMap 中覆写 void afterNodeRemoval(Node<K,V> e) { // unlink LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 将 p 节点的前驱后后继引用置空 p.before = p.after = null; // b 为 null,表明 p 是头节点 if (b == null) head = a; else b.after = a; // a 为 null,表明 p 是尾节点 if (a == null) tail = b; else a.before = b; }
简单描述下过程:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
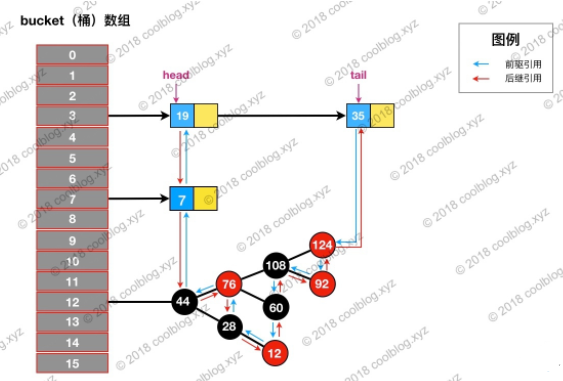
举个例子,假如我们要删除下图键值为 3 的节点。
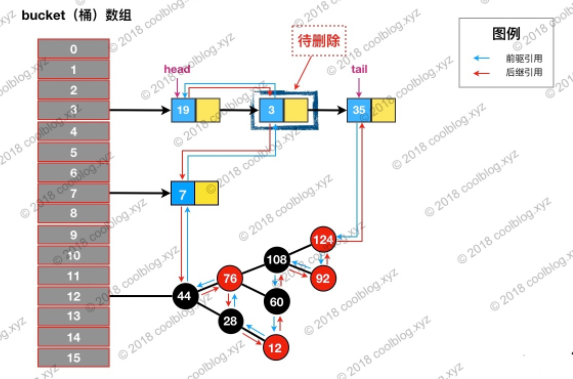
根据 hash 定位到该节点属于3号桶,然后在对3号桶保存的单链表进行遍历。找到要删除的节点后,先从单链表中移除该节点。如下:
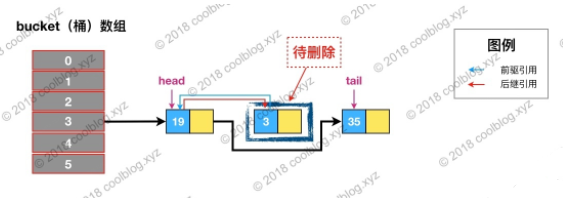
如果是HashMap,remove()的操作就结束了,但是LinkedHashMap还维护了一个双向链表,如下:
3、get()
// LinkedHashMap 中覆写 public V get(Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null) return null; // 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后 if (accessOrder) afterNodeAccess(e); return e.value; } // LinkedHashMap 中覆写 void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; // 如果 b 为 null,表明 p 为头节点 if (b == null) head = a; else b.after = a; if (a != null) a.before = b; /* * 这里存疑,父条件分支已经确保节点 e 不会是尾节点, * 那么 e.after 必然不会为 null,不知道 else 分支有什么作用 */ else last = b; if (last == null) head = p; else { // 将 p 接在链表的最后 p.before = last; last.after = p; } tail = p; ++modCount; } }
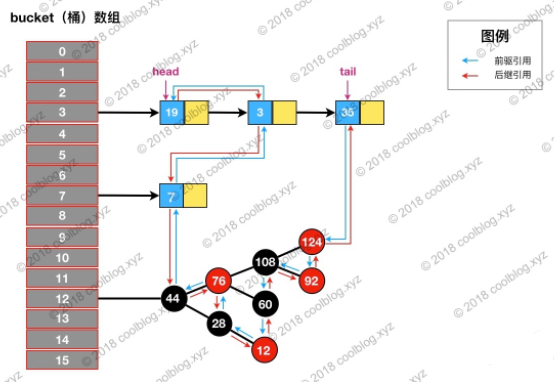
举个例子,依然访问下图键值为3的节点,访问前结构为:
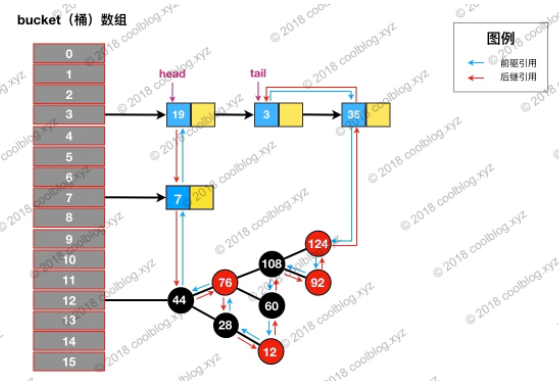
访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下:

posted on 2019-04-18 23:08 阿里-马云的学习笔记 阅读(266) 评论(0) 编辑 收藏 举报

