
走进JDK(二)------String
本文基于java8.
基本概念:
- Jvm 内存中 String 的表示是采用 unicode 编码
- UTF-8 是 Unicode 的实现方式之一
一、String定义
public final class String implements java.io.Serializable, Comparable<String>, CharSequence
String是个final类,不允许继承。并且实现了Serializable, Comparable<String>, CharSequence接口
- java.io.Serializable
这个序列化接口没有任何方法和域,仅用于标识序列化的语意。
- Comparable<String>
这个接口只有一个compareTo(T 0)接口,用于对两个实例化对象比较大小。
- CharSequence
这个接口是一个只读的字符序列。包括length(), charAt(int index), subSequence(int start, int end)这几个API接口,值得一提的是,StringBuffer和StringBuild也是实现了改接口。
二、主要成员变量
//String的底层是一个字符数组,并且为private final,决定了String一旦创建,无法通过方法去改变该String对象的值 private final char value[]; //hash是String实例化的hashcode的一个缓存。因为String经常被用于比较,比如在HashMap中。如果每次进行比较都重新计算hashcode的值的话,那无疑是比较麻烦的,而保存一个hashcode的缓存无疑能优化这样的操作。 private int hash; //Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,
否则就会出现序列化版本不一致的异常,即是InvalidCastException。 private static final long serialVersionUID = -6849794470754667710L;
三、构造函数
public String() { this.value = "".value; } public String(String original) { this.value = original.value; this.hash = original.hash; } //当传入char[]时,通过Arrays.copyOf()复制该数组给到Stirng的成员变量value[]中 public String(char value[]) { this.value = Arrays.copyOf(value, value.length); } //传入char[],可以自定义起始位置,元素个数 public String(char value[], int offset, int count) { if (offset < 0) { throw new StringIndexOutOfBoundsException(offset); } if (count <= 0) { if (count < 0) { throw new StringIndexOutOfBoundsException(count); } if (offset <= value.length) { this.value = "".value; return; } } if (offset > value.length - count) { throw new StringIndexOutOfBoundsException(offset + count); } this.value = Arrays.copyOfRange(value, offset, offset+count); } //也可以传入byte[],并且指定起始位置,长度以及编码类型 public String(byte bytes[], int offset, int length, Charset charset) { if (charset == null) throw new NullPointerException("charset"); checkBounds(bytes, offset, length); this.value = StringCoding.decode(charset, bytes, offset, length); } //也可以传入byte[],并且指定起始位置,长度 public String(byte bytes[], int offset, int length) { checkBounds(bytes, offset, length); this.value = StringCoding.decode(bytes, offset, length); } public String(StringBuffer buffer) { synchronized(buffer) { this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); } } public String(StringBuilder builder) { this.value = Arrays.copyOf(builder.getValue(), builder.length()); }
总之,String提供的构造函数可以将String、char[]、byte[]、StringBuffer、StringBuilder等多种参数类型的初始化方法。但本质上,其实就是将接收到的参数传递给全局变量value[]。
四、length()、isEmpty()、charAt()
//返回当前字符串的字符数量 public int length() { return value.length; } //判断字符串为空的方法就是判断字符数组的长度是否为0 public boolean isEmpty() { return value.length == 0; } //根据对应的index获取char public char charAt(int index) { if ((index < 0) || (index >= value.length)) { throw new StringIndexOutOfBoundsException(index); } return value[index]; } //根据指定的编码格式,将String转换成byte[] public byte[] getBytes(String charsetName) throws UnsupportedEncodingException { if (charsetName == null) throw new NullPointerException(); return StringCoding.encode(charsetName, value, 0, value.length); } public byte[] getBytes(Charset charset) { if (charset == null) throw new NullPointerException(); return StringCoding.encode(charset, value, 0, value.length); } //得到一个操作系统默认的编码格式的字节数组 public byte[] getBytes() { return StringCoding.encode(value, 0, value.length); }
五、equals()、compareTo()
1、equals()
public boolean equals(Object anObject) { //如果引用的是同一个对象,自然是相等的 if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; //挨个字符进行比较 while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
2、compareTo()
//compareTo(): //1、当当前String对象<入参,返回-1 //2、当前String对象=入参,返回0 //3、当前String对象>入参,返回1 public int compareTo(String anotherString) { int len1 = value.length; int len2 = anotherString.value.length; //取两个String中较小的长度 int lim = Math.min(len1, len2); char v1[] = value; char v2[] = anotherString.value; int k = 0; while (k < lim) { char c1 = v1[k]; char c2 = v2[k]; //当出现第一个不同字符的时候,比较大小 if (c1 != c2) { return c1 - c2; } k++; } //如果在规定的长度内,两个字符串一致,则比较字符串的长度 return len1 - len2; }
六、hashCode()、getBytes()
public int hashCode() { //hash用于保存当前字符串的hash值 int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { //为啥乘以31?主要是因为31是一个奇质数,所以31*i=32*i-i=(i<<5)-i,这种位移与减法结合的计算相比一般的运算快很多。 h = 31 * h + val[i]; } hash = h; } return h; }
getBytes()的实现主要有以下几种:
//按照给定的字符编码返回对应的字节数组 public byte[] getBytes(String charsetName) throws UnsupportedEncodingException { if (charsetName == null) throw new NullPointerException(); return StringCoding.encode(charsetName, value, 0, value.length); } public byte[] getBytes(Charset charset) { if (charset == null) throw new NullPointerException(); return StringCoding.encode(charset, value, 0, value.length); } //按照系统默认编码方式进行 public byte[] getBytes() { return StringCoding.encode(value, 0, value.length); }
七、intern()
public native String intern();
作用:将该字符串人工写入到字符串常量池。
先来看一组面试当中经常会出现的,如下:
String s1 = "Hello"; String s2 = "Hello"; String s3 = "Hel" + "lo"; String s4 = "Hel" + new String("lo"); String s5 = new String("Hello"); String s6 = s5.intern(); String s7 = "H"; String s8 = "ello"; String s9 = s7 + s8; System.out.println(s1 == s2); // true System.out.println(s1 == s3); // true System.out.println(s1 == s4); // false System.out.println(s1 == s9); // false System.out.println(s4 == s5); // false System.out.println(s1 == s6); // true
在java中,给String赋值主要有两种方式:
//一、直接字面量进行赋值 String str = "Hello"; //二、通过new关键字创建一个String对象 String str = new String("Hello");
再来看一下jvm中的内存模型:
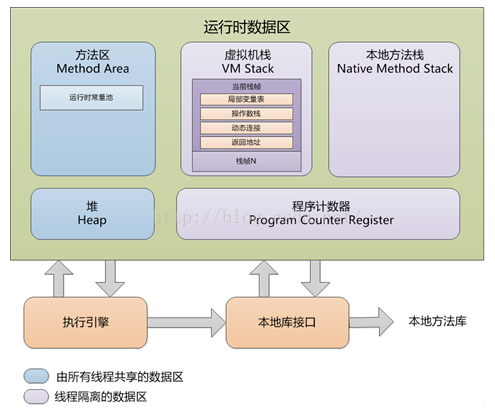
先说第二种方式,由于是new一个对象,无可厚非,先在堆中开辟一块空间,然后创建一个String对象,并且在需要使用此对象的地方保存一个引用,指向堆中的位置。
而由于String又是不可改变的,自然就会想到利用缓存的概念。试想如果一段代码或是一个jvm中有一万个String str = "阿里马云";难道要在堆中保存一万个对象吗?很明显这种设计是比较low的。因此jvm对于字面量声明的方式,在堆中创建字符串,
、然后将字符串的引用存放在方法区的字符串常量池中,也就是说如果都是String str = "阿里马云";的声明方式,那么整个jvm中只会有一个对象存放在堆中,常量池中保存该对象的引用。
ok,那么上面的面试题就可以一题题来解释了
1、s1、s2都是字面量声明,是一个对象,true 2、s3则是两个字面量拼接而成,编译器会进行优化(编译器优化的目的只有一个,就是提高性能),在编译时s3就变成“Hello”了,所以s1==s3。 3、s4虽然也是拼接,但“lo”是通过new关键字创建的,在编译期无法知道它的地址,所以不能像s3一样优化。所以必须要等到运行时才能确定,必然新对象的地址和前面的不同。 4、同理,s9由两个变量拼接,编译期也不知道他们的具体位置,不会做出优化。 5、s5是new出来的,在堆中的地址肯定和s4不同。 6、s6利用intern()方法得到了s5在字符串池的引用,并不是s5本身的地址。由于它们在字符串池的引用都指向同一个“Hello”对象,自然s1==s6。
总结:
- 字面量创建字符串会先在字符串池中找,看是否有相等的对象,没有的话就在堆中创建,把地址驻留在字符串池;有的话则直接用池中的引用,避免重复创建对象。
- new关键字创建时,在运行时会创建一个新对象,变量所引用的都是这个新对象的地址。
其他还有类似indexOf、substring等相对简单,不补充说明了

posted on 2019-04-10 21:04 阿里-马云的学习笔记 阅读(336) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号