
一、Java底层基础题
1、SpringMVC的原理以及返回数据如何渲染到jsp/html上?
答:Spring MVC的核心就是 DispatcherServlet , 一个请求经过 DispatcherServlet ,转发给HandlerMapping ,然后经反射,对应 Controller及其里面方法的@RequestMapping地址,最后经ModelAndView和ViewResoler返回给对应视图 。 具体可参考:Spring MVC的工作原理
2、一个类对象属性发生改变时,如何让调用者知道?
答:Java event时间监听 ,即在set方法改变属性时,触发 ,这种模式也可以理解为观察者模式,具体查看:观察者模式简单案例和说明
3、重写equals为何要重写hashCode?
答:判断两个对象是否相等,比较的就是其hashCode, 如果你重载了equals,比如说是基于对象的内容实现的,而保留hashCode的实现不变,那么很可能某两个对象明明是“相等”,而hashCode却不一样。 hashcode不一样,就无法认定两个对象相等了
4、谈谈你对JVM的理解?
答: Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。Java编译器只要面向JVM,生成JVM能理解的代码或字节码文件。Java源文件经编译成字节码程序,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。
JVM执行程序的过程 :I.加载。class文件 ,II.管理并分配内存 ,III.执行垃圾收集
JRE(java运行时环境)由JVM构造的java程序的运行环境
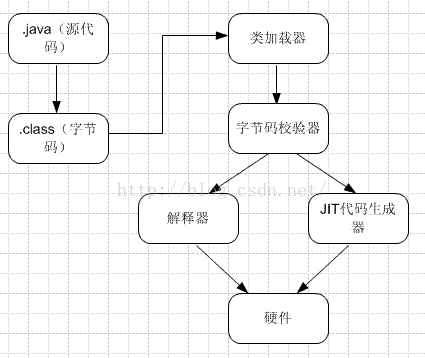
具体详情:JVM原理和调优
5、Mysql的事物隔离级别?
答:Mysql的事物隔离级别 其实跟 Spring的事物隔离级别一样,都是1、Read Uncommitted(读取未提交内容), 2、Read Committed(读取提交内容),3、Repeatable Read(可重读),4、Serializable(可串行化) 具体参照:mysql事物隔离级别
6、Spring的原理
答:Spring的核心是IOC和AOP ,IOC是依赖注入和控制反转,
其注入方式可分为set注入、构造器注入、接口注入等等。IOC就是一个容器,负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。简单理解就是:JAVA每个业务逻辑处理至少需要两个或者以上的对象协作进行工作,但是每个对象在使用它的合作对象的时候,都需要频繁的new
对象来实现,你就会发现,对象间的耦合度高了。而IOC的思想是:Spring容器来管理这些,对象只需要处理本身业务关系就好了。至于什么是控制反转,就是获得依赖对象的方式反转了。
AOP呢,面向切面编程,最直接的体现就是Spring事物管理。至于Spring事物的相关资料,就不细说了,参考:Spring注解式事物管理
7、谈谈你对NIO的理解
答:IO是面向流,NIO是面向缓冲 ,这里不细讲了,具体参照:Java NIO和IO的区别
8、ArrayList和LinkedList、Vector的区别?
答:总得来说可以理解为:.
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
Vector和ArrayList类似,但属于强同步类,即线程安全的,具体比较参照:比较ArrayList、LinkedList、Vector
9、随便说说几个单例模式,并选择一种线程安全的
答:单例的类别:懒汉、饿汉、枚举、静态内部类、双重校验锁 等等 , 选择线程安全我选最后一种,双重校验锁。 具体实现方式参照:Java:单例模式的七种写法
10、谈谈红黑树
答:算法和数据结构一直是我薄弱之处,这方面说自己补吧,成效不大,这里我就推荐一个:红黑树
11、举例说说几个排序,并说明其排序原理
答:这里我就不细说了,大家自己看看 Java实现几种常见的排序算法
12、Mysql索引的原理
答:索引的作用大家都知道,就是加快查询速度,但是原理,我说不上来,这里直接看吧:Mysql索引工作原理
13、序列化的原理和作用
答:Serialization(序列化)是一种将对象以一连串的字节描述的过程;反序列化deserialization是一种将这些字节重建成一个对象的过程,主要用于HTTP或者WebService接口传输过程中对象参数的传播,具体可参看:Java序列化机制和原理
二、并发及项目调优
1、说说线程安全的几种实现方式?
答:什么是线程安全? 我的理解是这样的,一个对象被多个线程同时访问,还能保持其内部属性的顺序性及同步性,则认定为线程安全。实现线程安全的三种方式:被volatile、synchronized等关键字修饰,或者使用java.util.concurrent下面的类库。 至于前两者的关系,参考:synchronized和volatile的用法区别
2、方法内部,如何实现更好的异步?
答:我们知道异步其实就是让另一个线程去跑,那么如何创建线程? 第一种直接new Thread ,第二种new 一个实现Runnable接口的实现类。 第三种,通过线程池来管理创建等 ,这里说到更好的实现异步,那就是说我们在方法内部避免频繁的new 线程,就可以考虑线程池了。 那么线程池如何创建? 这里可以new 一个线程池,但是需要考虑单例,或者在程序初始启东时,就创建一个线程池,让他跑着,然后在具体方法的时候,通过线程池来创建线程,实现异步
3、项目中为何要用缓存?如何理解nginx + tomcat + redis 集群缓存?
答1:最直接的表现就是减轻数据库的压力。避免因为数据读取频繁或过大而影响数据库性能,降低程序宕机的可能性
答2:nginx常用做静态内容服务和代理服务器,直面外来请求转发给后面的应用服务。nginx本身也能做缓存,比如静态页面的缓存什么的。而tomcat是应用服务器,处理JAVA
WEB程序功能等等
。你也可以这么理解,假设把用户的请求当做是一条河流,那么nginx就相当于一个水利工程,tomcat相当于一条条分流的支流,而redis
相当于支流旁边的一个个水库。
当你洪水来了,nginx根据你每条支流的承受力度分发不同的水流量,在确保程序正常运行的情况下,分发给每条支流(tomcat)不同的水流量。而redis相当于一个个支流的水库,存储水源,降低压力,让后面的水量平稳。
4、日常项目中,如果你接手,你准备从哪些方面调优?
答:这个呢首先是了解哪些需要优化,需要优化肯定是项目性能遭遇瓶颈或者猜测即将遭遇了,我们才会去考虑优化。那么怎么优化?
a、扩容 ,扩容的理解,就是扩充服务器并行处理的能力,简单来说就是加服务器,增加处理请求的能力,例如增加nginx 、tomcat等应用服务器的个数,或者物理服务器的个数,还有加大服务器带宽等等,这里考虑的是硬件方面
b、调优
,调优,包括系统调优和代码调优 。
系统调优就是说加快处理速度,比如我们所提到的CDN、ehcache、redis等缓存技术,消息队列等等,加快服务间的响应速度,增加系统吞吐量,避免并发,至于代码调优,这些就需要多积累了,比如重构、工厂等,
数据库调优的话这个我不是很懂,只知道索引和存储过程,具体参考:Mysql数据库调优21个最佳实践
,其他数据库调优方面就各位自己找找吧
5、谈谈你对分布式的理解
答:个人理解:分布式就是把一个系统/业务 拆分成多个子系统/子业务 去协同处理,这个过程就叫分布式,具体的演变方式参考:Java分布式应用技术架构介绍
6、Redis实现消息队列
答:Redis实现消息队列 、参考2
8、分享一个调优工具和方案:如何利用 JConsole观察分析Java程序的运行,进行排错调优
之前的面试总结:面试题总结——JAVA高级工程师
之前的技术问答:技术问答 也提到了一些面试的经验和知识点
三、手写代码题(包含sql题)
1、假设商户表A(id , city ) ,交易流水表B (aid, amount , time) 这里的time代表交易时间, 请用sql写出查询每个城市每个月的销售业绩(答案可在评论里回复)
2、假设有一个数组 A ,int[] A = { 1 , 3 , -1 ,0 , 2 , 1 , -4 , 2 , 0 ,1 ... N}; 原来是需要查出大于0的数组,但是由于传参错误或者其他原因,导致查出0和负数了,现在要求在不使用新数组和新集合的情况下(即只使用这个A数组,因数组数据比较大,且只能用一次循环) 实现正数放到数组的前面,小于等于0的数放到数组的末尾(答案可在评论里回复)
总结:
暂时就先总结这些,后续再补充吧,面试题千变万化,不变的是知识点和技术根本。基础很重要,故不积跬步,无以至千里;不积小流,无以成江海。学好基础,把握好技术的原理,然后去实践,这样才能深入了解一门技术,学不可以已!
另外,面试过程中,保持自信,不会的咱大胆的说不会,没啥好丢脸的,不会不是说你真的不会,也许是忘了,也许是没注意到,记住面试题目,回来自己补充资料和相关的信息,相信你肯定会越来越从容,要记住不是为了面试而面试,而是为了未来的工作而面试,如果能一直保持这个状态,没有什么事情拿不下的。
拿我自己来说,很多不会,关键在于你愿不愿意去学,愿不愿意去付诸行动。加油吧,希望各位看官都能找到心仪的工作
